
Summary: Discover eleven practical Machine Learning projects tailored for beginners. Each project offers hands-on experience and insights into advanced techniques, from predicting house prices to real-time object recognition.
Introduction
Machine Learning is a transformative field that has gained traction in recent years. Adding Machine Learning skills to your profile can boost it. As beginners embark on their journey to explore the realm of Machine Learning, they often seek practical projects to apply their newfound knowledge and skills.
The best Machine Learning course will also help you acquire the necessary skills via practical applications. ML projects are an integral part of Machine Learning interview questions. Hence, gaining useful knowledge is a must.
This comprehensive guide presents eleven captivating Machine Learning projects tailored for beginners. Each project includes detailed explanations, codes, and examples to facilitate a deeper understanding and hands-on experience.
What is Machine Learning?
Machine Learning is a branch of Artificial Intelligence (AI) that enables systems to learn from data and improve performance without explicit programming. It focuses on developing algorithms that automatically learn patterns and make decisions or predictions based on data.
At its core, Machine Learning revolves around algorithms learning from data. Instead of relying on explicit programming instructions, these algorithms iteratively learn from the data provided. This iterative aspect allows them to discover patterns and insights that humans might miss or find too complex to extract manually.
Critical components of Machine Learning are:
- Data: Data is central to Machine Learning. Algorithms require large amounts of quality data to identify patterns effectively. This data can range from structured information in databases to unstructured text or images.
- Algorithms: Machine Learning algorithms are the engines that drive learning. They are designed to process data, detect patterns, and make decisions or predictions. Common algorithms include decision trees, neural networks, support vector machines, and clustering algorithms.
- Model Training: Training a Machine Learning model involves feeding it data to learn from. During training, the model adjusts its parameters to optimise its ability to make predictions or decisions based on new data.
Applications and Impact
Machine Learning finds applications across various fields, including finance, healthcare, marketing, and more. It powers recommendation systems, fraud detection algorithms, autonomous vehicles, and personalised medicine. Its ability to process vast amounts of data and extract meaningful insights has revolutionised industries, making processes more efficient and enabling innovations that were once considered futuristic.
Future Directions
As technology advances, Machine Learning continues to evolve. Current trends include integrating Machine Learning with other technologies like big data and the Internet of Things (IoT) and advancements in deep learning and reinforcement learning. These developments promise to enhance the capabilities of Machine Learning systems further, making them more adaptive, autonomous, and capable of tackling increasingly complex problems.
Top 11 Machine Learning Projects
Knowing about top Machine Learning projects is crucial for staying updated with industry trends, gaining practical insights into advanced techniques, and exploring real-world applications. It helps professionals understand best practices, challenges, and innovations, enhancing their skills and credibility in the rapidly evolving field of Machine Learning.
Predicting House Prices with Linear Regression
Linear regression is an excellent starting point for beginners diving into Machine Learning. In this project, we use linear regression to predict house prices based on features such as square footage, number of bedrooms, and location. Through step-by-step guidance, beginners will learn to preprocess data, build a regression model, and evaluate its performance.
Python code example using Scikit-learn for implementing linear regression to predict house prices:

Note: Replace ‘feature1’, ‘feature2’, … with the actual feature names from your dataset. Similarly, ‘house_prices.csv’ should be replaced with the filename or path to your dataset file. This code will give you a basic framework for implementing linear regression for house price prediction in Python.
Recognising Handwritten Digits with the MNIST Dataset
The MNIST dataset is a classic benchmark for image classification tasks. In this project, beginners delve into image recognition by building a neural network to classify handwritten digits. By leveraging libraries like TensorFlow or PyTorch, participants gain insights into convolutional neural networks (CNNs) and the intricacies of image processing.
Here’s a simple Python code example using TensorFlow and Keras to recognise handwritten digits using a basic CNN:

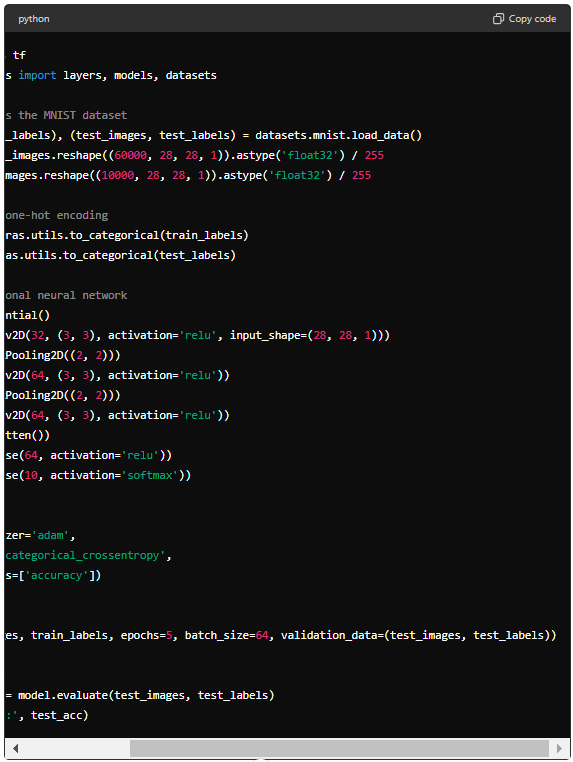
Note: This code uses a simple CNN architecture with three convolutional layers followed by max-pooling and two dense layers. The model is trained using the MNIST dataset and evaluated on the test set. You can further optimise and experiment with the model architecture for better accuracy.
Sentiment Analysis on Movie Reviews
Sentiment analysis offers a fascinating glimpse into natural language processing (NLP). In this project, beginners explore NLP techniques by analysing movie reviews to determine sentiment polarity (positive, negative, or neutral). Using tools like NLTK or spaCy, participants preprocess text data, extract features, and train sentiment classifiers.
Here’s a simple Python code example using Scikit-learn and the IMDb movie review dataset for sentiment analysis:
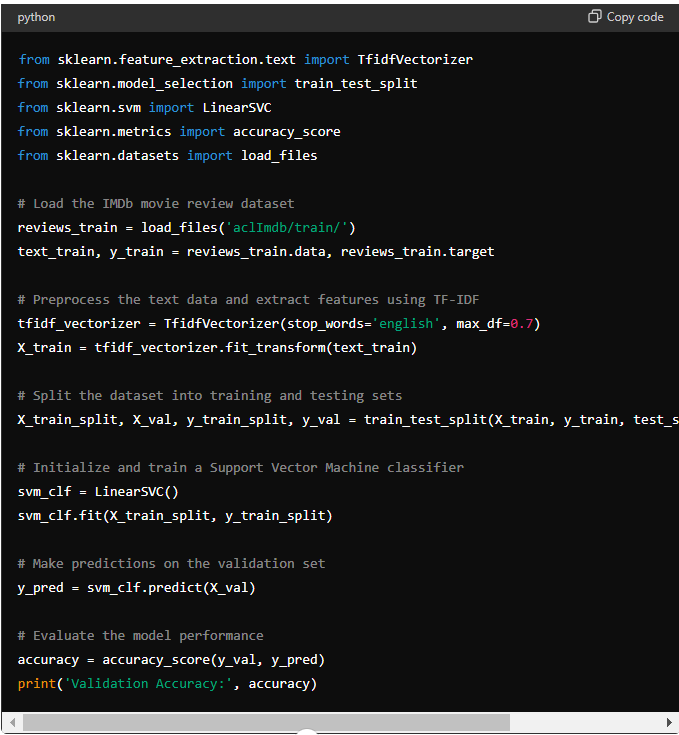
Note: We load the IMDb movie review dataset, preprocess the text data using TF-IDF vectorisation, split the dataset into training and validation sets, and train a Support Vector Machine classifier. Finally, we evaluate the model’s accuracy on the validation set. You can further optimise the model or explore different algorithms to improve performance.
Clustering Customer Segments with K-Means
Understanding customer behaviour is crucial for businesses across industries. In this project, beginners apply K-means clustering to segment customers based on purchasing patterns and demographics. Participants gain insights into market segmentation and targeted marketing strategies by visualising clusters and interpreting results.
Here’s a simple Python code example using Scikit-learn to perform K-Means clustering on a synthetic customer dataset:
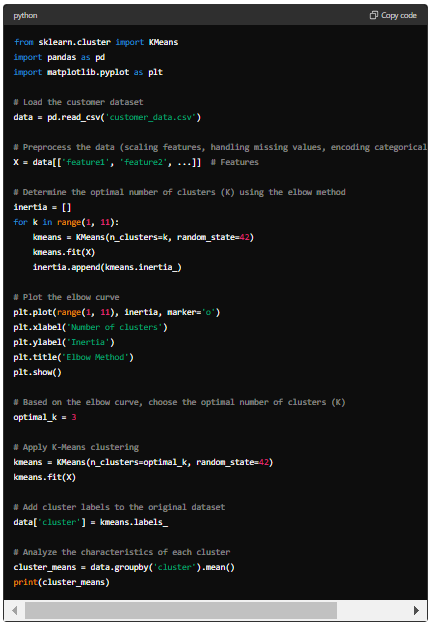
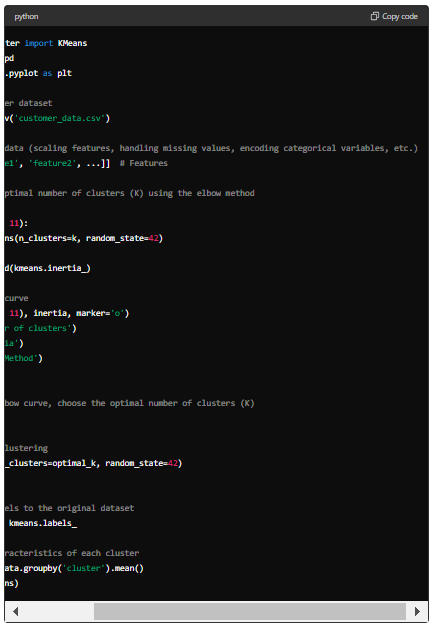
Note: Replace ‘feature1’, ‘feature2′, …’ with the actual features from your dataset, and ‘customer_data.csv’ with the filename or path to your dataset file. This code will help you perform K-Means clustering on your customer dataset and analyse the characteristics of each cluster.
Detecting Fraudulent Transactions with Anomaly Detection
Fraud detection is a critical application of Machine Learning in finance and cybersecurity. In this project, beginners tackle fraud detection by employing anomaly detection algorithms such as isolation forests or autoencoders. Through feature engineering and model evaluation, participants identify anomalous transactions and enhance fraud prevention mechanisms.
Python code example using the Isolation Forest algorithm for detecting fraudulent transactions:

Note: Replace ‘feature1’, ‘feature2′, …’ with the actual features from your dataset, and ‘transaction_data.csv’ with the filename or path to your transaction dataset file. This code will help you detect fraudulent transactions using the Isolation Forest algorithm. Adjust the contamination parameter according to your dataset’s expected proportion of fraudulent transactions.
Recommender System for Movie Recommendations
Recommender systems play a pivotal role in personalising user experiences across digital platforms. In this project, beginners construct a movie recommender system using collaborative filtering or content-based approaches. By leveraging user-item interactions and movie metadata, participants design algorithms to generate personalised recommendations.
Simple Python code example using the Surprise library to build a collaborative filtering movie recommender system:

Note: Replace ‘ratings.csv’ with the filename or path to your movie ratings dataset. This code uses the Surprise library, which provides a simple interface for building and evaluating collaborative filtering models. It loads the dataset, splits it into training and testing sets, builds a user-based collaborative filtering model using KNN, trains it, makes predictions, evaluates its performance, and finally provides movie recommendations for a specific user.
Classifying Iris Flower Species with Decision Trees
The Iris flower dataset is a classic example of classification tasks in Machine Learning. In this project, beginners utilise decision tree algorithms to classify Iris flower species based on sepal and petal attributes. Participants gain insights into classification algorithms and model interpretability by visualising decision boundaries and interpreting tree structures.
Python code example using Scikit-learn to classify Iris flower species with a decision tree classifier:
Note: We load the Iris dataset, split it into training and testing sets, build a decision tree classifier, train the classifier using the training data, make predictions on the testing set, and evaluate the model’s accuracy. Adjusting hyperparameters or other classification algorithms can improve the model’s performance.
Analysing Stock Market Trends with Time Series Forecasting
Time series forecasting enables analysts to predict future trends based on historical data. In this project, beginners explore time series analysis by forecasting stock market trends using techniques like ARIMA or LSTM networks. Participants gain valuable insights into financial modelling and algorithmic trading by analysing price movements and evaluating forecast accuracy.
Simple Python code example using the ARIMA model for time series forecasting of stock prices:
Note: Replace ‘stock_data.csv’ with the filename or path to your historical stock price dataset. The ARIMA model is just one example, and you may need to experiment with different models and parameters based on the characteristics of the stock price data.
Additionally, consider incorporating more advanced models like LSTM for improved performance, especially when dealing with complex patterns in the stock market.
Image Segmentation for Medical Imaging
Medical imaging holds immense potential for diagnosing diseases and guiding treatment plans. In this project, beginners delve into image segmentation techniques to identify and delineate regions of interest in medical images. By applying algorithms like U-Net or Mask R-CNN, participants contribute to advancements in medical image analysis and healthcare technology.
We’ll perform a basic segmentation task on an MRI brain image to segment the brain tissues into different regions: white matter, gray matter, and cerebrospinal fluid (CSF).
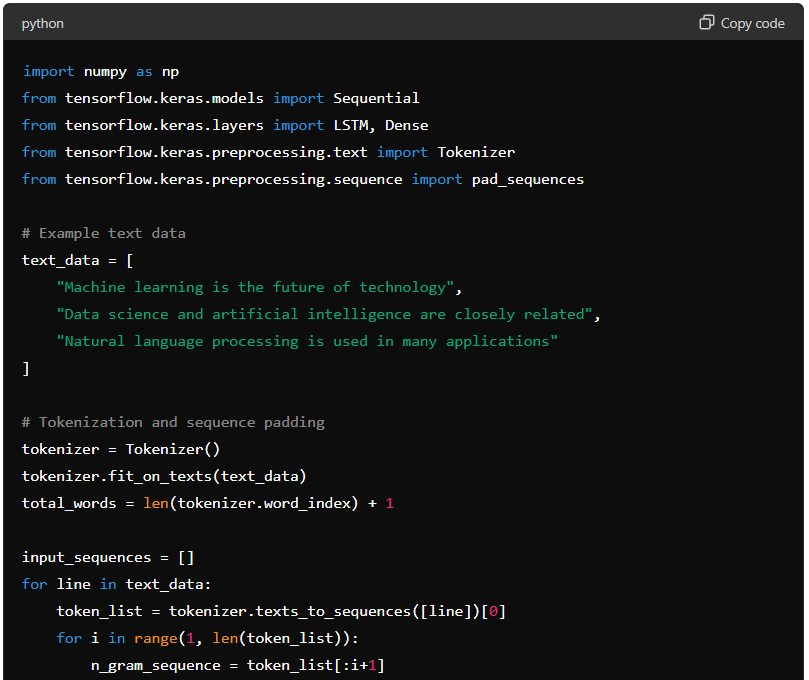
Note: We label the connected components in the binary image using the label() function.
Finally, we plot the original MRI image and the segmented brain tissues using Matplotlib.
Please replace ‘brain_mri.jpg’ with the filename or path to your MRI brain image.
This example provides a basic demonstration of image segmentation for medical imaging and more sophisticated techniques and preprocessing steps may be required for specific applications and datasets.
Recognising Objects in Real-time with Deep Learning
Real-time object recognition is a captivating application of deep learning in computer vision. In this project, beginners develop object detection models to identify and localise objects within live video streams. By implementing architectures like YOLO or SSD, participants explore real-world applications of deep learning in autonomous driving, surveillance, and augmented reality.
Simplified example of how you can recognise objects in real-time using YOLOv4 with the OpenCV library in Python:
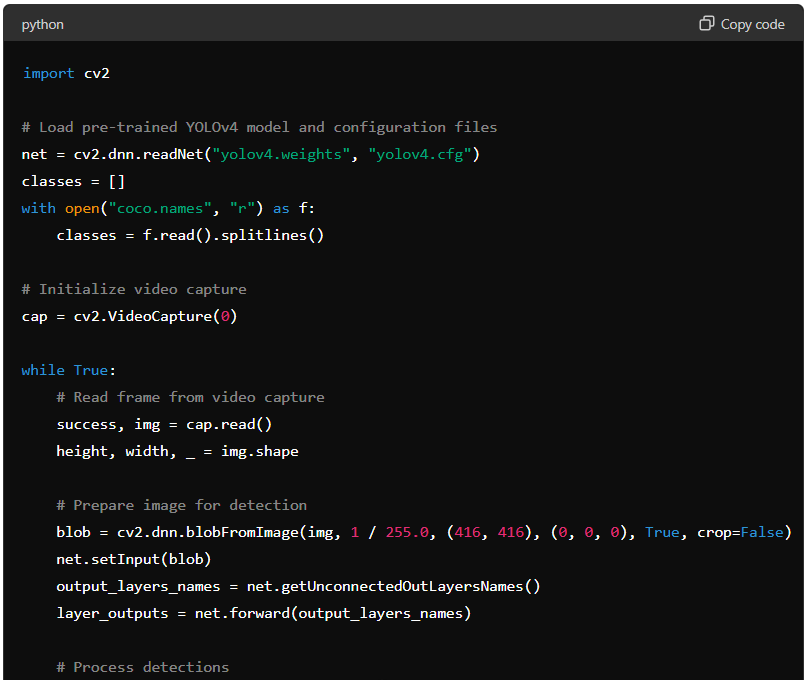
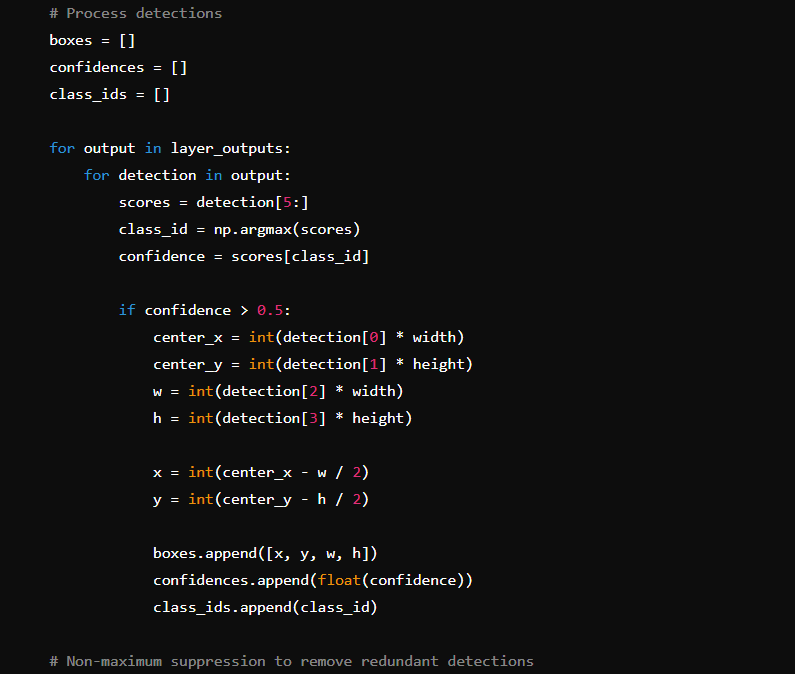

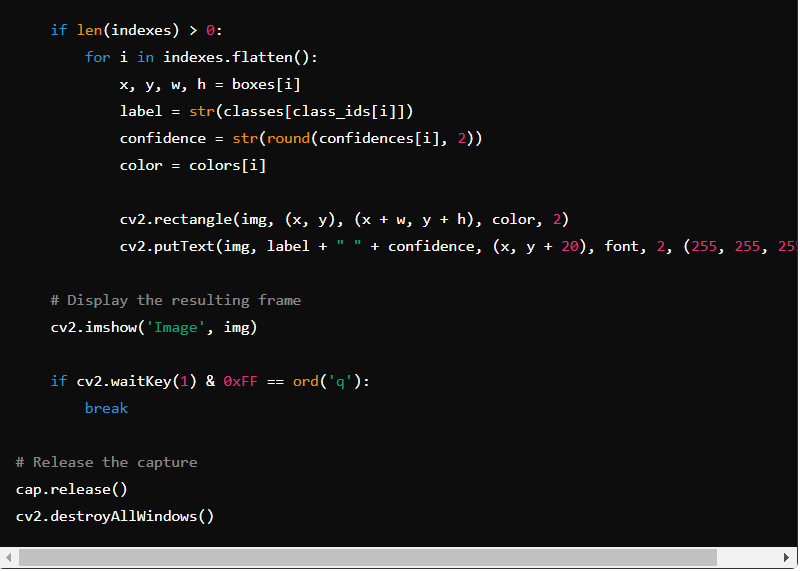
Note: The processed frame is displayed in real-time using OpenCV’s imshow() function.
Press ‘q’ to quit the application.
Please make sure to have the YOLOv4 model weights file (yolov4.weights), the configuration file (yolov4.cfg), and the class names file (coco.names) in the working directory. Additionally, you need to have OpenCV installed (pip install opencv-python).
Generating Text with Recurrent Neural Networks
Text generation is a fascinating frontier in natural language processing and Artificial Intelligence. In this project, beginners train recurrent neural networks (RNNs) to generate coherent text sequences based on input data. By experimenting with architectures like LSTM or GRU, participants delve into language modelling and creative AI applications.
Here is a simple example of how you can generate text using a character-level recurrent neural network (RNN) in Python with TensorFlow and Keras:


Note: This example demonstrates a basic character-level text generation model using LSTM recurrent neural networks. You can adjust parameters like the number of LSTM units, training epochs, and text generation settings to experiment with different text generation results.
Frequently Asked Questions
What are the best Machine Learning projects for beginners?
Start with projects like predicting house prices using linear regression, recognising handwritten digits with the MNIST dataset, or performing sentiment analysis on movie reviews. These projects offer practical insights into data preprocessing, model building, and evaluation, essential for beginners to grasp Machine Learning fundamentals.
How do Machine Learning projects enhance skills?
Machine Learning projects, such as clustering customer segments with K-means or detecting fraudulent transactions, provide hands-on experience in data manipulation, algorithm selection, and model evaluation. They strengthen Data Analysis, pattern recognition, and problem-solving skills, critical for advancing proficiency in Machine Learning techniques.
Why are Machine Learning projects essential for career growth?
These projects showcase practical expertise in handling real-world data challenges, highly valued by employers seeking candidates adept in applying Machine Learning to solve complex problems. They demonstrate your ability to innovate, improve decision-making, and contribute effectively to data-driven initiatives in various industries.
Closing Statements
These eleven Machine Learning projects offer an immersive journey for beginners to explore diverse applications and techniques within the field. By delving into practical implementations and hands-on exercises, participants gain invaluable experience and pave the way for further exploration and innovation in Machine Learning.
Level up your skills with a Data Science certification courses
With the growing demand for Data Scientists, data skills have become one of the most lucrative additions to anyone’s profile. If you, too, want to take a giant leap in your career, the best time is to start now.
Pickl.AI offers a free Machine Learning course and other courses like Data Analytics certification course, Data Science Job Guarantee program, and others. These courses cover core data skills and essential Data Science tools. Moreover, they help you acquire non-technical skills that prepare you for the job market.
Authors
-

Written by:
Smith AlexReviewed by:



