
Summary: Data can be deceiving. Sometimes, the most valuable insights lie in the unexpected – the anomalies. Anomaly detection, a powerful machine learning technique, helps us spot these outliers, the data points that deviate significantly from the norm. This blog explores various anomaly detection algorithms, from statistical methods to complex AI techniques.
Introduction
Anomaly detection is identified as one of the most common use cases in Machine Learning. The purpose of finding and identifying outliers is helpful in prevention of fraudulent activities, adversary attacks and network intrusions that have the ability to compromise the company’s future.
The following blog will provide you a thorough evaluation on how Anomaly Detection Machine Learning works, emphasising on its types and techniques. Further, it will provide a step-by-step guide on anomaly detection Machine Learning python.
Anomaly Detection in Machine Learning
An approach to data analysis and Machine Learning called “anomaly detection,” also referred to as “outlier detection,” focuses on finding data points or patterns that considerably differ from what is considered to be “normal” or anticipated behaviour.
Observations that deviate from the majority of the data are known as anomalies and might take the shape of occurrences, trends, or events that differ from customary or expected behaviour.
Finding anomalous occurrences that might point to intriguing or potentially significant events is the aim of anomaly detection. Anomalies could be a sign of many different things, including fraud, mistakes, flaws, health problems, security breaches, and more. In many fields, finding anomalies can yield insightful data and useful information.
Anomaly Detection Machine Learning Example
In this section, we will highlight anomaly detection, a powerful machine learning technique that can identify these outliers. Anomaly detection unlocks a world of possibilities, and given below are the Machine Learning anomaly detection examples that you need to know about:
Network Intrusion Detection
Anomaly detection Machine Learning algorithms is used to monitor network traffic and identify unusual patterns that might indicate a cyberattack or unauthorised access. For instance, sudden spikes in data traffic or unusual communication patterns between devices can be flagged as anomalies.
Healthcare Monitoring
Anomaly detection can be applied to patient monitoring data to identify irregularities in vital signs. This could include detecting unusual heart rhythms in ECG data or unexpected variations in blood pressure that might indicate a health issue.
Manufacturing Quality Control
Anomaly detection can be used to monitor the output of manufacturing processes. It can identify faulty products by analysing sensor data, such as detecting defects in the shape or size of products on an assembly line.
Energy Usage Monitoring
Anomaly detection is used to identify abnormal energy consumption patterns in industrial or residential settings. Sudden spikes or drops in energy usage can indicate equipment malfunction or energy theft.
Fraud Detection in Financial Transactions
Anomaly detection techniques are used to identify fraudulent credit card transactions. Transactions that deviate from a user’s usual spending patterns or involve unusual locations can be flagged for further investigation.
Aircraft Engine Performance Monitoring
Anomaly detection is used to monitor aircraft engine health. By analysing data from various sensors on the engine, deviations from normal operating conditions can be detected, allowing maintenance crews to address potential issues before they lead to failures.
E-commerce Customer Behaviour
Anomaly detection can be used to identify unusual patterns in customer behaviour on e-commerce platforms. For instance, sudden changes in purchase habits or unusually high cart abandonment rates might indicate fraud or other issues.
Environmental Monitoring
Anomaly detection is used to monitor environmental factors like air quality and water pollution. Unusual variations in pollutant levels or other environmental parameters can be indicative of an incident or pollution source.
Supply Chain Anomalies
Anomaly detection applied to supply chain data to identify disruptions or irregularities. Unexpected delays in shipping, drastic changes in order quantities, or sudden supplier changes can be flagged as anomalies.
Server Log Analysis
Anomaly detection used to monitor server logs and identify unusual patterns that might indicate a security breach or system failure. This could include sudden spikes in failed login attempts or unusual patterns of resource usage.
These examples highlight the versatility of anomaly detection in various domains. The specific techniques and algorithms used can vary based on the nature of the data and the problem at hand.
Anomaly Detection Machine Learning Techniques
Anomaly detection, a powerful branch of machine learning, equips us to identify these outliers – the data points that deviate significantly from the norm. In this section, we’ll explore various machine learning techniques for anomaly detection, from statistical methods to complex algorithms.
Unsupervised Anomaly Detection
Unsupervised anomaly detection tackles this challenge, empowering us to find hidden patterns and outliers in data, ultimately leading to better decision-making and improved security.
Artificial Neural Networks (ANNs)
Autoencoders, a type of neural network, can used for unsupervised anomaly detection. An autoencoder consists of an encoder network that maps input data to a lower-dimensional representation, and a decoder network that reconstructs the input from the lower-dimensional representation.
During training, the model learns to minimise the reconstruction error. Anomalies, being different from normal data, result in higher reconstruction errors.
Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
DBSCAN is a density-based clustering algorithm. It identifies regions of high data point density as clusters and flags points with low densities as anomalies. Points that don’t belong to any cluster or in low-density regions considered anomalies.
Isolation Forest
The Isolation Forest algorithm creates a random partition of the data by selecting features and random split values. Anomalies can isolated more quickly as they require fewer splits to separated from the majority of the data. This algorithm is efficient and effective for high-dimensional datasets.
Gaussian Mixture Models (GMM)
GMM represents the data distribution as a mixture of several Gaussian distributions. Anomalies might have low probabilities under the fitted GMM, as they deviate from the common Gaussian patterns observed in normal data.
Supervised Anomaly Detection
Supervised anomaly detection is a method that leverages labelled data to train models for pinpointing anomalies. We will explore how supervised learning empowers us to fight fraud, detect equipment failures, and uncover other hidden abnormalities within our data sets.
Support Vector Machines (SVM)
In a supervised context, SVM trained to find a hyperplane that best separates normal instances from anomalies. Anomalies treated as the minority class, and the model aims to maximise the margin between the two classes.
Random Forests
Random Forests can adapted for anomaly detection by treating it as malous data. Instances that are difficult to classify (misclassified or those in the minority class) receive higher outlier scores, indicating they might be anomalies.
k-Nearest Neighbors (k-NN)
In the supervised approach, k-NN assigns labels to instances based on their k-nearest neighbours. Anomalies assigned to the class where they have the fewest neighours, or instances that are far from their neighbours can identified as anomalies.
Semi-Supervised Anomaly Detection
Semi-supervised techniques leverage a combination of labelled normal data and unlabeled data to enhance anomaly detection performance. Choosing the right technique depends on the characteristics of your data, the distribution of anomalies, and the available resources for training and evaluation.
Pre-trained Models
Models that are pre-trained on a large dataset, like deep learning models trained on ImageNet, can be fine-tuned for anomaly detection on a specific problem. Anomalies might lead to deviations from the normal patterns the model has learned.
Transfer Learning
Transfer learning involves using a pre-trained model from one domain to solve a related task in another domain. By fine-tuning the model with your data, you can leverage its learned features for anomaly detection.
It’s important to experiment and iterate to find the most effective approach for your specific use case.
How to do Anomaly Detection using Machine Learning in Python?
Here’s a detailed step-by-step guide on how to perform anomaly detection using Machine Learning in Python. We’ll use a simple example of credit card fraud detection and the Isolation Forest algorithm for this demonstration.
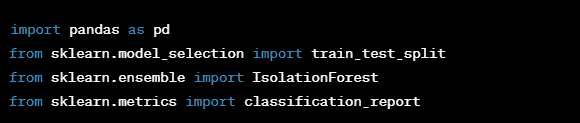
Step 1: Import Libraries Start by importing the necessary libraries.
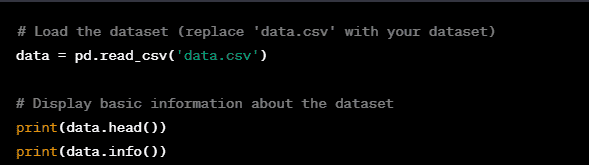
Step 2: Load and Explore Data Load your dataset and explore its structure and content.
Step 3: Data Preprocessing Preprocess the data by handling missing values and scaling numerical features.

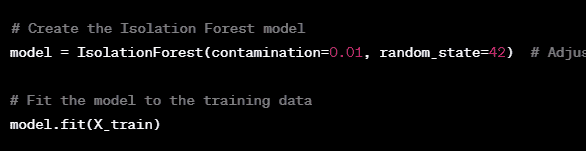
Step 4: Model Training Train the Isolation Forest model on the training data.
Step 5: Anomaly Detection and Evaluation: Detect anomalies in the testing data and evaluate the model’s performance.

Step 6: Interpretation and Tuning Interpret the results, analyse the classification report, and adjust the parameters if needed.
The contamination parameter in the Isolation Forest determines the expected proportion of anomalies in the data. You can adjust this based on your dataset’s characteristics.
You can explore other algorithms like one-class SVM, autoencoders, or different ensemble methods for anomaly detection.
Step 7: Deployment Once you’re satisfied with the model’s performance, you can deploy it to detect anomalies in real-time data. This might involve setting up a pipeline to preprocess incoming data and use the trained model to predict anomalies.
Remember that anomaly detection is a continuous process. As new patterns of anomalies emerge, you’ll need to update and retrain your model to ensure its effectiveness.
Conclusion
In conclusion, we have provided you with an in-depth understanding of Anomaly Detection Machine Learning. Make sure that you learn the entire process thoroughly with much practice using Python.
In case you want to opt for a free Machine Learning Certification course to learn anomaly detection, you can apply for the same through Pickl.AI. With recorded sessions and lifetime access to the learning material, you will gain an expertise in anomaly detection.
Frequently Asked Questions
What are the Different Types of Anomaly Detection Algorithms?
There are two main categories: statistical methods and machine learning techniques. Statistical methods analyse historical data to identify deviations from the expected patterns. Machine learning algorithms, like k-Nearest Neighbors or Isolation Forests, learn from data to identify anomalies without relying on pre-defined patterns.
How Do I Choose the Right Anomaly Detection Algorithm?
The best algorithm depends on your data and specific needs. Consider factors like the type of data (numerical vs. categorical), the expected distribution of anomalies (rare vs. frequent), and the desired level of interpretability.
Is Anomaly Detection Foolproof?
No algorithm is perfect. Anomalies can missed (false negatives) or normal data can be flagged incorrectly (false positives). Careful evaluation and tuning of the chosen algorithm are crucial to optimize its effectiveness for your specific use case.
Authors
-

Written by:
Shriya SinghReviewed by:



