
Summary: This blog explains what is Hadoop and how does it work in simple terms. From its core components to real-world uses, learn why Hadoop is vital for processing big data and how it supports modern data science practices across industries like healthcare, banking, retail, and social media.
Introduction
Ever wondered how companies like Netflix or Amazon handle tons of data every day? That’s where Hadoop jumps in like a superhero! In this blog, we’ll break down the big buzz around big data—and why it needs a helper like Hadoop to make sense of it all.
You’ll learn what is Hadoop and how does it work?—in a fun, simple way. No tech jargon, no complex stuff—just clear, easy explanations. By the end, you’ll understand its key parts, how it stores and processes data, and where it’s actually used. So grab your curiosity—we’re diving into the world of data with style!
Key Takeaways
- It is an open-source framework that stores and processes big data efficiently.
- It uses components like HDFS, MapReduce, YARN, and Hadoop Common.
- Hadoop ensures data safety, fault tolerance, and scalability across many machines.
- It supports various industries, including healthcare, banking, and e-commerce.
- Learning Hadoop is a strong step toward mastering data science and big data analytics.
What is Hadoop?
Hadoop is an open-source software that helps store and process large amounts of data across many computers. Think of it like a smart system that breaks big data into smaller parts, stores them in different places, and then processes them quickly when needed. It’s built to handle huge volumes of information that regular software can’t manage easily.
The Story Behind Hadoop
It started as a project inspired by Google’s data handling method. It was created to solve one big problem: working with data that’s too large for a single computer to process. Over time, it became one of the most popular tools for big data management.
Why Hadoop Matters Today
In today’s world, businesses deal with massive data every day—from social media, online shopping, sensors, and customer feedback. It helps make sense of all this data quickly and affordably. Companies in healthcare, banking, e-commerce, and more use it.
The growing importance of data has also made Hadoop a valuable technology. In fact, the global market was valued at $35.74 billion in 2020. It is expected to grow rapidly and reach $842.25 billion by 2030, with a strong annual growth rate of 37.4% from 2021 to 2030.
Core Components of Hadoop
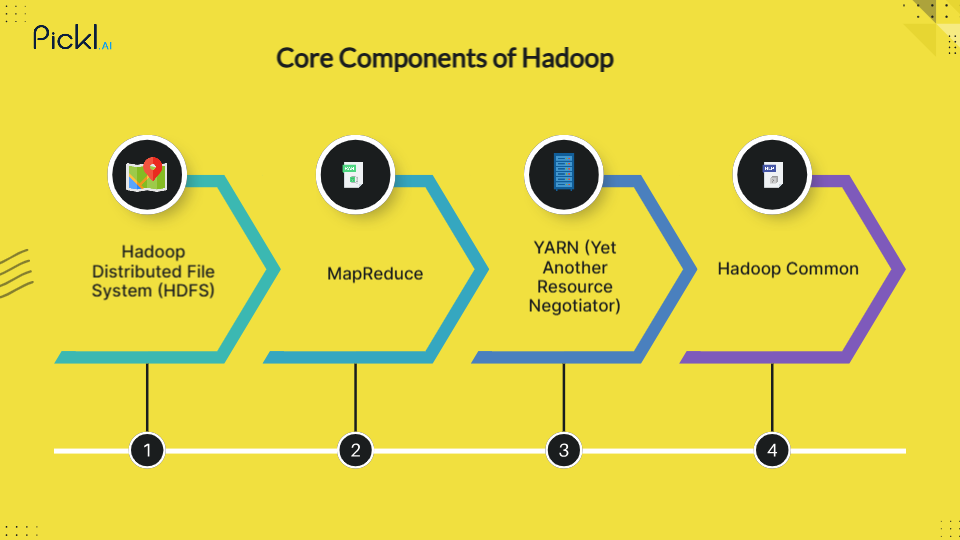
It is a powerful tool for storing and processing large amounts of data. To do this effectively, it uses four key parts that work together: HDFS, MapReduce, YARN, and Hadoop Common. Let’s break them down in simple terms so that anyone can understand what each one does.
Hadoop Distributed File System (HDFS)
HDFS is like a big digital storage system. Imagine you have a huge file that’s too large for one computer to handle. HDFS splits that file into smaller parts and stores them across many computers.
This way, even very large files can be saved easily. Also, it keeps extra copies of the data in case one computer fails, so nothing is lost.
MapReduce
MapReduce is the part of Hadoop that helps process data. For example, if you want to count the number of times a word appears in a group of documents, MapReduce breaks this task into smaller steps.
The “Map” step handles the smaller tasks on different computers, and the “Reduce” step combines the results to get the final answer. It makes data processing faster and more efficient.
YARN (Yet Another Resource Negotiator)
YARN is like the manager of the Hadoop system. It keeps track of which computer is doing what. YARN assigns jobs to the available computers if one task is finished or needs help. It ensures all the system parts are working smoothly and resources are used wisely.
Hadoop Common
It includes all the tools and libraries that the other parts of Hadoop need to run. Think of it as the foundation or toolbox that supports the entire Hadoop system. It helps the different parts talk together and work as one unit.
How Hadoop Works
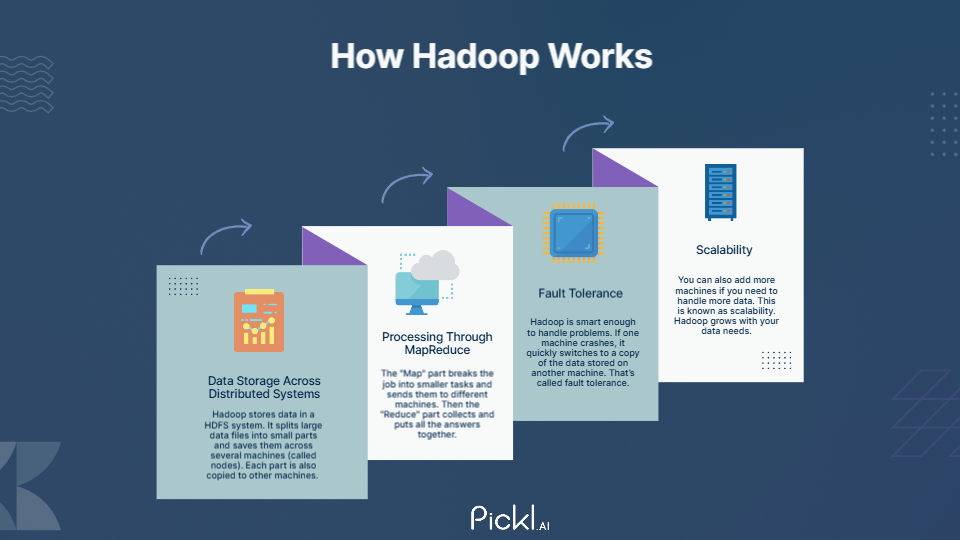
They may sound like a complex system, but at its core, it’s a smart way to store and process huge amounts of data across many computers. Instead of using one powerful computer, Hadoop breaks big tasks into smaller ones and spreads them out. Here’s how it works in simple terms:
Data Storage Across Distributed Systems
Imagine you have a huge book to store, but your shelf is too small. So, you break the book into pages and store those pages across many smaller shelves. Hadoop does something similar with data.
It stores data in a HDFS (Hadoop Distributed File System) system. It splits large data files into small parts and saves them across several machines (called nodes). Each part is also copied to other machines. So, if one machine fails, a copy of the data is still available somewhere else, making the system reliable.
Processing Through MapReduce
Once data is stored, Hadoop uses a method called MapReduce to process it. Think of MapReduce as dividing a big chore among many people.
The “Map” part breaks the job into smaller tasks and sends them to different machines. Each machine works on its part of the job. Then the “Reduce” part collects and puts all the answers together. This helps process vast amounts of data faster than doing it all in one place.
Fault Tolerance and Scalability
Hadoop is smart enough to handle problems. If one machine crashes, it quickly switches to a copy of the data stored on another machine. That’s called fault tolerance.
You can also add more machines if you need to handle more data. This is known as scalability. Hadoop grows with your data needs.
Key Features of Hadoop
It is a popular tool for storing and processing huge amounts of data. It is built in a way that makes handling large data fast, easy, and cost-effective. Many companies use Hadoop to manage their growing data needs, whether it’s a social media platform or an online shopping website. Here are some key features that make Hadoop so useful:
- Handles Big Data Easily: Hadoop can store and process data in terabytes or petabytes without slowing down.
- Works on Many Machines: It spreads the data across many computers, so the job gets done faster.
- Keeps Data Safe: Even if one machine fails, the data is copied to other machines to prevent loss.
- Saves Money: It runs on simple hardware, which makes it cheaper than other data tools.
- Grows with Your Needs: As your data grows, you can add more computers without changing the system.
Benefits of Hadoop
It brings many advantages, especially when dealing with large amounts of data. Whether you’re a business owner, a data enthusiast, or just curious about big data, Hadoop makes storing, managing, and processing huge volumes of information easier. Here’s how Hadoop can be helpful, even if you’re not a tech expert:
- Handles Large Data: Hadoop can store and process tons of data—think of millions of files—without slowing down.
Saves Money: It runs on regular, low-cost computers instead of expensive machines, helping companies cut costs. - Keeps Data Safe: The data isn’t lost even if one computer fails. Hadoop keeps copies in different places to avoid data loss.
- Grows with Your Needs: You can start small and add more computers as your data grows, without changing the whole system.
- Works Fast: It breaks big tasks into smaller ones and handles them all at once, making work faster.
Limitations of Hadoop
While Hadoop is a powerful tool for handling large volumes of data, it also has limitations. It may not be the best fit for every data problem, especially when speed and ease of use are essential. Here are some of the common drawbacks of using Hadoop:
- Slow for Real-Time Processing: it works best for batch jobs and not for tasks that need quick, real-time answers.
- Complex Setup and Management: Setting up and managing Hadoop can be tough. It often requires skilled people to run smoothly.
- Not Ideal for Small Data: If your data is small or medium-sized, Hadoop might be overkill and less efficient.
- High Hardware Use: It needs a lot of storage and computing power, which can increase costs.
- Limited Support for Interactive Queries: It doesn’t easily support quick, ad-hoc questions like regular databases.
Real-World Applications of Hadoop
Many companies use to handle large amounts of data quickly and affordably. It helps them make better decisions, offer smarter services, and deeply understand their customers. Even if you’re not from a tech background, you’ll likely benefit from Hadoop-powered systems in your daily life without even knowing it.
Here are some simple examples of how Hadoop is used in the real world:
- Online Shopping: E-commerce sites use Hadoop to recommend products based on what you’ve viewed or bought before.
- Banking and Finance: Banks detect fraud by analysing transaction patterns using Hadoop.
- Healthcare: Hospitals store and analyse patient records to improve treatment plans and predict diseases early.
- Social Media: Platforms like Facebook or Twitter analyse user posts and trends to show relevant content.
- Transport Services: Companies like Uber use Hadoop to find the fastest routes and match drivers with passengers.
What This Means for You
Now that you know what is Hadoop and how does it work, you can see why it plays a vital role in the world of big data and data science. It makes handling, storing, and processing huge datasets easier, which is a must-have skill in today’s data-driven world.
If you’re excited to explore data processing, big data tools, and real-world analytics more, consider joining data science courses by Pickl.AI. These courses are designed to help you build practical skills with hands-on projects—perfect for beginners and professionals aiming to boost their career in data science.
Frequently Asked Questions
What is Hadoop and how does it work in data science?
Hadoop is an open-source framework used in data science to store and process massive datasets. It works by distributing data across multiple machines using HDFS and processes it using MapReduce, making it efficient, fault-tolerant, and scalable—ideal for big data analytics.
Is Hadoop still relevant today?
Yes, Hadoop remains relevant, especially in industries managing massive datasets. While modern tools like Spark are popular, Hadoop is still widely used for data warehousing, analytics, and scalable storage. It forms a strong foundation for big data infrastructure in many companies globally.
Can I learn Hadoop without a technical background?
Absolutely! Hadoop concepts are beginner-friendly if explained clearly. You can start with visual content, simple analogies, and beginner courses like those from Pickl.AI, which teach Hadoop basics and big data concepts in an easy-to-understand format—no coding experience required.
Authors
-

Written by:
Aishwarya KurreReviewed by:



