
Summary: Data Quality ensures data accuracy and reliability while Data Observability monitors data delivery systems in real-time. They complement each other by improving data management and enhancing decision-making.
Introduction
Data is the lifeblood of the digital age. Today, every organisation tries to explore the significant aspects of data and its applications. The ultimate objective of any organisation is to harness the power of data and improve its decision-making process. However, the quality of data becomes pivotal here.
In simple terms, Data Quality identifies the state of data and whether it is valuable and relevant. Conversely, Data Observability deals with techniques for determining whether the data contains any signal that needs further research or investigation.
In this blog, we will discuss the two key aspects of data management: observability and quality. While we usually use these terms interchangeably, there is a line of difference between them.
Significance of Data
Data is crucial in the modern business realm. Recognising its relevance, organisations leverage data to delve deeper into Data Observation and maintain high Data Quality standards.
This empowers businesses to understand customer behaviour, streamline operations, and make informed, data-driven decisions. High-quality data is crucial for accurate analytics, reporting, and forecasting. It ensures that businesses can trust their insights and predictions, reducing the risk of errors and enhancing strategic planning.
Without reliable data, businesses would navigate in the dark, relying on guesswork rather than concrete evidence. This could lead to misinformed decisions, inefficiencies, and missed opportunities.
Data provides the clarity and direction necessary for effective decision-making, enabling organisations to stay competitive in a rapidly evolving market. By investing in robust data management practices, businesses can harness the power of data to drive growth, innovation, and operational excellence.
Data is the backbone of modern business strategy, offering invaluable insights that guide every aspect of operations. As the digital landscape continues to evolve, the significance of data will only increase, solidifying its role as a critical asset for success in the business world.
Know More: Nominal vs Ordinal Data: Understanding the Differences.
What is Data Observability and its Significance?

Data Observability involves monitoring and understanding data in real-time, ensuring its reliability, accuracy, and availability. It plays a pivotal role in ensuring that data remains transparent and trustworthy. In today’s fast-paced business environment, the significance of Data Observability cannot be overstated. Data Observability enables organisations to detect anomalies, troubleshoot issues, and maintain data pipelines effectively.
5 Pillars of Data Observability
It is a critical aspect of modern data management that ensures data remains transparent, reliable, and trustworthy in real time. To achieve this, organisations rely on five fundamental pillars:
Data Collection
Data collection from various sources is at the core of Data Observationability. This pillar emphasises the importance of capturing data accurately and comprehensively at its source. Effective data collection ensures that the data under observation is complete, up-to-date, and error-free. It serves as the foundation upon which all other aspects of observability rely.
Data Monitoring
The second pillar is real-time data monitoring, which focuses on continuous data tracking as it flows through various processes and pipelines.
This involves setting up monitoring tools and systems that can promptly detect anomalies, deviations, or issues in the data. Data monitoring is crucial for early detection and quick response to data-related problems, ensuring data remains reliable and trustworthy.
Data Transparency
Data Transparency is the pillar that ensures data is accessible and understandable to all stakeholders within an organisation. This involves creating data dictionaries, documentation, and metadata. It provides clear insights into the data’s structure, meaning, and usage. Transparency is essential to enable practical data interpretation and utilisation across the organisation.
Data Reliability
The fourth pillar, Data Reliability, focuses on maintaining data dependability and consistency throughout its lifecycle. This involves implementing data validation processes, cleansing routines, and quality checks to eliminate errors, inaccuracies, or inconsistencies. Reliable data is essential for making informed decisions and conducting meaningful analyses.
Data Availability
Data Availability is the final pillar, ensuring that data is readily accessible when needed. This involves establishing redundancy measures, backup systems, and disaster recovery plans to provide uninterrupted access to data. Downtime can have significant consequences in a data-driven environment, making data availability a critical consideration for observability.
What is the Data Observability Framework?

The Data Observability Framework is a structured approach organisations follow to ensure that their data remains transparent, reliable, and trustworthy in real-time. It encompasses various vital components and practices aimed at maintaining Data Observability as it moves through different processes.
Elements of the Data Observability Framework
The concept of Data Observability is crucial in the world of data management and analytics. It refers to monitoring and understanding your data’s quality, reliability, and health. The five pillars of Data Observability are vital aspects that organisations focus on to ensure their data is accurate, up-to-date, and well-managed. Let’s break down each of these pillars:
Freshness
Freshness refers to how current and up-to-date your data is. It’s essential to ensure that your data is not stale or outdated. Timely data is crucial for making informed decisions and maintaining the accuracy of analytics. Monitoring freshness involves tracking the time the data was last updated or collected and ensuring it aligns with business needs.
Quality
Data Quality is about the reliability and accuracy of your data. High-quality data is free from errors, inconsistencies, and anomalies.
To assess Data Quality, you may need to perform data profiling, validation, and cleansing to identify and address missing values, duplicates, or outliers. Quality data ensures that your analytics and reporting are trustworthy and dependable.
Volume
Volume pertains to the quantity of data you have. Understanding the scale of your data is essential, as it can impact storage, processing, and analysis. Monitoring data volume involves tracking how much data is generated, collected, and stored over time.
It’s especially critical in big data and large-scale analytics projects, where managing and scaling storage and processing resources is challenging.
Schema
A data schema defines the structure and organisation of your data. It specifies the data types, relationships, and constraints within a dataset. Ensuring a consistent and well-defined schema is essential for data integrity and compatibility. Changes in the schema can affect downstream processes, so monitoring schema changes and versioning is crucial for maintaining Data Observability.
Lineage
Data lineage provides a clear picture of the data’s journey, showing where it comes from, how it’s transformed, and where it’s used. It helps you understand the flow of data within your organisation and trace back any issues or inconsistencies. Tracking data lineage can be challenging but is essential for Data Governance, compliance, and troubleshooting.
Must Know: All About Data Quality Framework & Its Implementation.
Similarity and Difference Between Data Quality and Data Observability
Both Data Quality and Data Observability are concerned with the usefulness of an organisation’s data. To this end, they are essential to an organisation and complement each other.
That said, Data Quality and Data Observability have slightly different goals. Data Quality aims to ensure more accurate, more reliable data. Data Observability seeks to ensure the quality and reliability of the entire data delivery system.
Data Quality is concerned with the data itself, while Data Observability is concerned with the system that delivers that data.
To that end, Data Observability goes a step ahead of monitoring data and alerting users to Data Quality issues. It attempts to identify data collection and management problems and fix those big-picture issues at the source.
Tabular representation of differences between Data Quality and Data Observability are given below:

Read: Unlocking the 12 Ways to Improve Data Quality.
How Data Quality and Data Observability Can Work Together to Improve Data Usefulness
Because Data Quality and Data Observability aim to ensure more valuable and reliable data, many organisations use them to improve the data they collect. Data Observability can improve Data Quality over the long run by identifying bit-picture problems with data pipelines.
With more reliable data pipelines, cleaner data comes in, and fewer errors are introduced. The result is higher-quality data and less downtime due to data issues.
There are many ways to make Data Quality and Data Observability work together. These include:
- Connecting data to scan and inspect data from various sources and pipelines.
- Gaining awareness by identifying relationships between different data sources.
- Automating Data Quality controls using Machine Learning to generate new quality monitoring rules based on evolving data patterns and sources.
- Adapting business workflows and processes based on identified data patterns.
- Generating alerts when Data Quality deteriorates to resolve issues quickly.
The more your organisation relies on data to make day-to-day and long-term operational and strategic decisions, the more critical Data Quality and the reliability of the data management process become. Access to data is necessary, so ensuring its accuracy and usability becomes even more vital.
Check More: Elevate Your Data Quality: Unleashing the Power of AI and ML for Scaling Operations.
Data Observability vs. Data Quality vs. Data Governance
Data Observability, Data Quality, and Data Governance are three critical aspects of data management within organisations. Each plays a unique role, but they are interconnected in ensuring that data remains valuable, reliable, and compliant. Here’s a breakdown of the differences between these concepts:
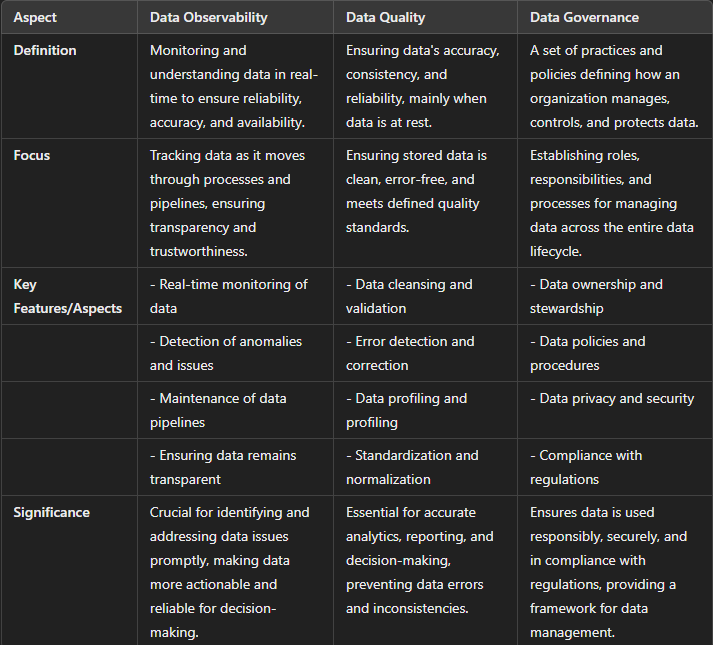
How are Data Observability, Data Quality, and Data Governance Complementary to each other?
Data Observability, Data Quality, and Data Governance enhance an organisation’s data management. Data Observability enhances Data Quality by enabling organisations to monitor their data in real-time. This real-time monitoring allows for the prompt detection and correction of quality issues, ensuring the data remains accurate and reliable.
Data Governance is crucial in maintaining Data Quality by establishing the necessary standards and policies. By setting these guidelines, Data Governance ensures that data is consistently managed and maintained to meet quality requirements. These policies provide a framework for organisations to follow, which helps preserve the integrity and usability of the data.
Additionally, Data Observability supports Data Governance by providing real-time insights into data usage. These insights help organisations enforce their governance policies more effectively. Organisations can ensure compliance with governance standards and swiftly address deviations by continuously monitoring how data is accessed and utilised.
Together, these three elements create a robust system for managing data. Data Observability provides the tools for real-time monitoring, Data Quality ensures data accuracy and reliability, and Data Governance establishes the policies and standards to maintain data integrity.
This integrated approach allows organisations to manage their data more efficiently and effectively, leading to better decision-making and overall performance.
Frequently Asked Questions
What is the difference between Data Quality and Data Observability?
Data Quality ensures data accuracy, consistency, and reliability. Data Observability monitors the entire data delivery system in real time to detect anomalies and issues, providing the data pipeline’s reliability and transparency.
Why is Data Observability important for businesses?
Data Observability is crucial for companies as it enables real-time data monitoring, allows early detection of issues, ensures data reliability, and maintains the transparency and trustworthiness of data pipelines.
How do Data Quality and Data Observability work together?
Data Quality and Data Observability complement each other by ensuring accurate, reliable data. Observability identifies and resolves data pipeline issues, enhancing Data Quality. Together, they provide a robust data management framework.
Wrapping it up
Data Observability and Data Quality are critical components in data management and analytics. While both aim to ensure data reliability and accuracy, they serve distinct purposes. Data Quality focuses on the intrinsic characteristics of data, striving for consistency, completeness, and correctness.
By understanding these differences, organisations can effectively leverage both Data Observability and Data Quality to maintain a high standard of data integrity, enabling better decision-making and insights in today’s data-driven world.
Expand Your Professional Growth with Pickl.AI
With the growing expansion of data across different businesses, it has become imperative for organisations to hire data experts. Professionals with data skills can reasonably understand the significance of data and harness its power to ensure profitable growth for the organisation.
With Pickl.AI, you get a platform to learn about the complex concepts of data science and its applications. As a part of the learning process, you will be exposed to several case studies and projects that will further hone your skills as a data professional.
Moreover, with Pickl.AI’s data science job preparation program, you have a scope for growth and job opportunities. For more information on this, connect with Pickl.AI today.
Authors
-

Written by:
Neha SinghReviewed by:



