Summary: Adopting DataOps transforms data science practices by automating workflows, ensuring higher data quality, and fostering collaboration among teams. This approach enhances efficiency, scales operations easily, and proactively reduces risks through early error detection and robust governance. Organizations benefit from accelerated insights, improved reliability, and optimized use of data resources.
Introduction
In the fast-paced world of data science, the ability to rapidly and reliably deliver valuable insights is paramount. However, many data science teams find themselves bogged down by inefficient workflows, poor data quality, and a lack of collaboration.
This is where DataOps in data science emerges as a transformative methodology, promising to revolutionize how data science projects are executed.
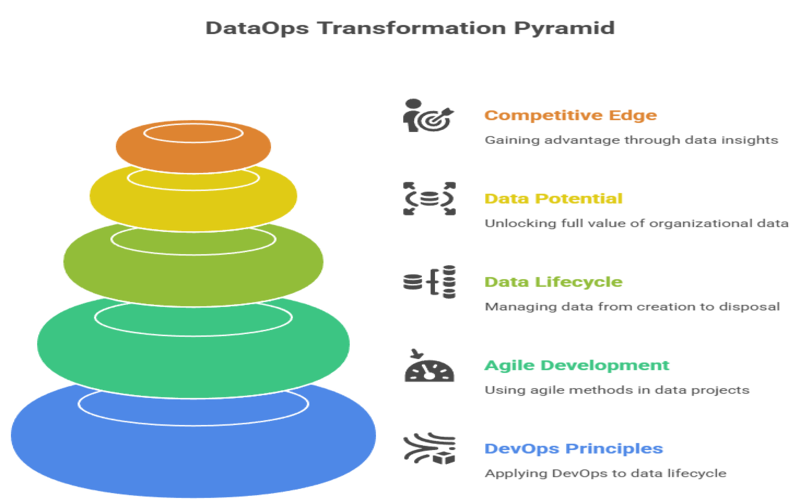
By applying the principles of DevOps and agile development to the entire data lifecycle, DataOps empowers organizations to unlock the full potential of their data and gain a significant competitive edge.
Key Takeaways
- DataOps automation accelerates delivery of actionable insights and analytics solutions.
- Continuous validation ensures consistently high-quality, trustworthy datasets for business use.
- Enhanced collaboration bridges gaps between data engineering, science, and operational teams.
- Scalable frameworks allow organizations to manage increasing data complexity seamlessly.
- Built-in governance and monitoring reduce the chances of analytics and compliance risks.
What Is DataOps in Data Science?
DataOps, a portmanteau of “data” and “operations,” is a collaborative data management practice designed to improve the communication, integration, and automation of data flows between data managers and data consumers.
Modeled after DevOps, which has transformed software development, DataOps applies similar principles of continuous integration and continuous delivery (CI/CD) to the data pipeline. It’s a holistic approach that brings together data engineers, data scientists, analysts, and IT operations to streamline the journey of data from source to value.
At its core, DataOps is about breaking down the silos that often exist between the teams that produce data and those that consume it. It fosters a culture of collaboration and shared responsibility, ensuring that everyone is aligned with the common goal of delivering high-quality, reliable data for analysis.
This methodology is not just a set of tools or technologies; it’s a mindset that encourages continuous improvement, automation, and innovation in a data-driven environment.
Why DataOps Matters in 2025
The significance of DataOps is projected to soar in 2025 as organizations grapple with ever-increasing data volumes, velocity, and variety. The traditional, often manual, approaches to data management are no longer sustainable in an era where real-time insights are crucial for business success.
According to Gartner, by 2026, a data engineering team guided by DataOps practices and tools will be ten times more productive than teams that do not use DataOps.
In 2025, the ability to quickly adapt to changing business needs and market dynamics will be a key differentiator. DataOps provides the agility and flexibility required to respond to these changes effectively.
As artificial intelligence (AI) and machine learning (ML) become more integrated into business operations, the need for robust and reliable data pipelines will be more critical than ever. DataOps will be instrumental in ensuring the quality and integrity of the data that fuels these advanced analytics, enabling more accurate and trustworthy models.
Furthermore, with the growing complexity of data ecosystems, including hybrid and multi-cloud environments, a structured and automated approach to data management is essential for scalability, security, and compliance. DataOps provides the framework to manage this complexity effectively.
Key Benefits of DataOps in Data Science

The adoption of DataOps in data science offers a multitude of benefits that directly address the common challenges faced by data teams. These advantages lead to more efficient, effective, and impactful data science initiatives.
One of the most significant benefits of DataOps in data science is the accelerated delivery of insights. By automating repetitive tasks and streamlining workflows, DataOps significantly reduces the time it takes to move a data project from conception to production. This allows organizations to react more quickly to market changes and capitalize on new opportunities.
Another key benefit is improved data quality and reliability. DataOps integrates automated testing and validation throughout the data pipeline, catching errors and inconsistencies early on. This focus on quality ensures that data scientists are working with trustworthy data, leading to more accurate models and more reliable insights.
Enhanced collaboration is also a major advantage. DataOps breaks down the barriers between data engineers, data scientists, and business analysts, fostering a culture of teamwork and shared ownership. This collaborative environment leads to better communication, fewer misunderstandings, and more effective data projects.
Other notable benefits include:
- Increased Efficiency and Reduced Costs: Automation of manual tasks frees up data professionals to focus on higher-value activities and reduces operational costs.
- Greater Agility: The iterative and incremental approach of DataOps allows teams to be more responsive to changing requirements.
- Improved Resource Utilization: By streamlining processes, DataOps helps in the optimal allocation and use of resources.
- Data Democratization: It enables broader access to vetted and governed data, empowering more users across the organization to make data-driven decisions.
DataOps Tools and Technology
A successful DataOps implementation relies on a combination of tools and technologies that automate and streamline the various stages of the data lifecycle. These DataOps tools for data science can be broadly categorized into several key areas:
Data Orchestration and Workflow Automation
These tools are at the heart of DataOps, enabling the automation and management of complex data pipelines. Popular open-source options include Apache Airflow and Prefect, while commercial platforms like DataKitchen and Rivery offer comprehensive solutions.
Data Integration and Ingestion
These tools facilitate the movement of data from various sources into a centralized repository. Fivetran and StreamSets are prominent players in this space.
Data Transformation
Tools like dbt (data build tool) have gained immense popularity for their ability to transform data within a data warehouse using SQL, promoting collaboration and version control for transformation logic.
Data Quality and Observability
To ensure data reliability, tools that monitor data pipelines and detect anomalies are crucial. Monte Carlo and Unravel provide robust data observability platforms.
Version Control
Git-based platforms like GitHub and GitLab are essential for managing code and collaborating on data pipeline development, treating data and infrastructure as code.
Containerization
Technologies like Docker and Kubernetes are used to create consistent and reproducible environments for developing and deploying data pipelines.
Cloud Platforms
Cloud providers like AWS, Azure, and Google Cloud offer a suite of services that form the foundation for a modern DataOps stack, including data storage, processing, and analytics tools.
Implementation of DataOps
Implementing DataOps is a journey that involves a cultural shift alongside the adoption of new tools and processes. A successful implementation typically follows a structured approach:
Build Cross-Functional Teams
The first step is to break down silos and create teams that bring together data engineers, data scientists, developers, and business analysts.
Establish Clear Processes
Define standardized data pipelines with clear protocols for data intake, processing, and delivery.
Automate Repetitive Tasks
Identify and automate manual and repetitive tasks within the data workflow to improve efficiency and reduce the risk of human error.
Adopt a Data Product Mindset
Treat data as a product with end-users in mind, focusing on delivering value to the business.
Start Small and Scale
Begin with a pilot project to demonstrate the value of DataOps and then gradually scale the implementation across the organization.
Continuously Monitor and Iterate
Implement continuous monitoring to track the performance of data pipelines and use the feedback to drive ongoing improvements.
Working Process of DataOps

The working process of DataOps is cyclical and iterative, mirroring the agile and DevOps methodologies it is based on. It can be broken down into several key stages:
Plan
This initial stage involves collaboration between business stakeholders, data scientists, and engineers to define the goals, requirements, and key performance indicators (KPIs) for a data project.
Develop
Data engineers and scientists work on building and refining data products, including data pipelines and machine learning models.
Integrate
The developed code and data products are integrated into the existing technology stack. Continuous integration practices ensure that new changes are regularly merged and tested.
Test
Rigorous automated testing is performed at every stage to validate data quality, pipeline functionality, and business logic.
Release and Deploy
Once tested and validated, the data pipelines and models are deployed to a production environment. Continuous delivery practices automate this process, enabling frequent and reliable releases.
Operate and Monitor
The production pipelines are continuously monitored for performance, data quality, and errors. Statistical process control (SPC) can use to ensure data remains within acceptable ranges.
Feedback
Feedback from users and monitoring systems collect and used to inform the next iteration of planning and development, creating a continuous improvement loop.
Pros of DataOps
The adoption of DataOps brings numerous advantages to a data science practice. By implementing DataOps, organizations can rapidly unlock the full value of their data assets while ensuring quality, reliability, and scalability at every step.
Faster Time-to-Value
By integrating automation and streamlining data workflows, DataOps greatly reduces the time needed to develop, deploy, and refine analytics solutions. As a result, business users and stakeholders gain access to actionable insights more quickly, supporting timely and informed decision-making that drives competitive advantage.
Improved Data Quality
DataOps emphasizes continuous testing, validation, and active monitoring throughout the data lifecycle. This rigorous approach helps identify and address anomalies, inconsistencies, and errors early, resulting in datasets that are consistently reliable and trustworthy for analytics and reporting.
Enhanced Collaboration
The collaborative framework encouraged by DataOps breaks down silos between data engineers, analysts, data scientists, and operations teams. By promoting shared responsibility, standardized processes, and transparent communication, DataOps creates an environment where teams can work together seamlessly towards common data goals.
Reduced Risk
By embedding automated governance controls, continuous validation, and error detection into data workflows, DataOps helps identify potential data issues early in the process. This proactive risk management approach minimizes the chances of data breaches, compliance failures, or costly errors in analytics results.
Cons of DataOps
While the benefits are substantial, there are also some challenges and potential downsides to consider when implementing DataOps:
Cultural Shift
The move to a DataOps culture can be challenging and requires a significant change in mindset and processes across the organization.
Initial Investment
Implementing DataOps requires an upfront investment in tools, technology, and training.
Complexity of Technology
The DataOps landscape includes a wide array of tools, and selecting and integrating the right ones can be complex.
Potential for Increased Governance Burden
While improving governance, the enforcement of new rules and policies can sometimes perceive as a hindrance by data teams.
Frequently Asked Questions
What is DataOps in data science?
DataOps in data science is a methodology that applies agile and DevOps principles to the entire data lifecycle. It focuses on collaboration, automation, and continuous improvement to streamline data workflows and accelerate the delivery of high-quality, reliable data for analytics and machine learning.
How does DataOps improve data science workflows?
DataOps improves data science workflows by automating repetitive tasks, implementing continuous integration and delivery for data pipelines, and fostering collaboration between data engineers and data scientists. This leads to faster development cycles, higher data quality, and more reliable and reproducible results.
Why is DataOps important in 2025?
DataOps is crucial in 2025 because it enables organizations to manage the increasing volume and complexity of data effectively. It provides the agility and speed needed to deliver real-time insights, which is essential for staying competitive in a data-driven world and supporting the growing use of AI and machine learning.
Which tools are commonly used in DataOps?
Commonly used DataOps tools include data orchestration platforms like Apache Airflow and Prefect, data integration tools such as Fivetran, transformation tools like dbt, and data observability platforms like Monte Carlo. Version control systems like Git are also fundamental.
Authors
-

Written by:
Aashi VermaReviewed by: