Summary: Web scraping automates data extraction from websites, transforming unstructured web content into usable data. This guide covers how scrapers work, popular Python tools like Beautiful Soup and Scrapy, types of scrapers, and practical uses. Ideal for students and beginners aiming to harness web data for research and business insights.
Introduction
In today’s data-driven world, the ability to gather and analyze information from the internet is an invaluable skill. Whether you’re a data science student, a college researcher, or simply curious about how to collect data efficiently, understanding web scraping is essential.
This blog will walk you through what web scraping is, how it works, the tools you can use (especially with Python), and why it’s so important in various industries. We’ll also answer common questions and provide actionable insights to help you get started.
Key Takeaways
- Web scraping automates data collection, saving time and effort over manual methods.
- Python’s libraries like Scrapy and Beautiful Soup simplify web scraping for beginners.
- Handling JavaScript content requires tools like Selenium or AI-powered scrapers.
- Web scraping is widely used in market research, lead generation, and academic studies.
- Legal and ethical considerations are crucial when scraping data from websites.
What is Web Scraping?

At its core, web scraping is the automated process of extracting data from websites. Instead of manually copying and pasting information from web pages, web scraping uses software programs called web scrapers or bots to collect data quickly and accurately.
Why is Web Scraping Important?
The internet is a vast repository of information—millions of websites host data on products, services, news, social media, academic papers, and more. Web scraping allows you to tap into this wealth of information and transform unstructured web content into structured data that can be analyzed and used for decision-making.
For example, a business might scrape competitor websites to monitor prices and promotions, while a researcher might scrape scientific publications for meta-analysis. The possibilities are endless.
Web Scraping Statistics
- Over 80% of companies use web scraping to gather competitive intelligence.
- The global web scraping market is expected to grow at a CAGR of 15% and reach $1469 billion by 2033.
- Python, the most popular language for web scraping.
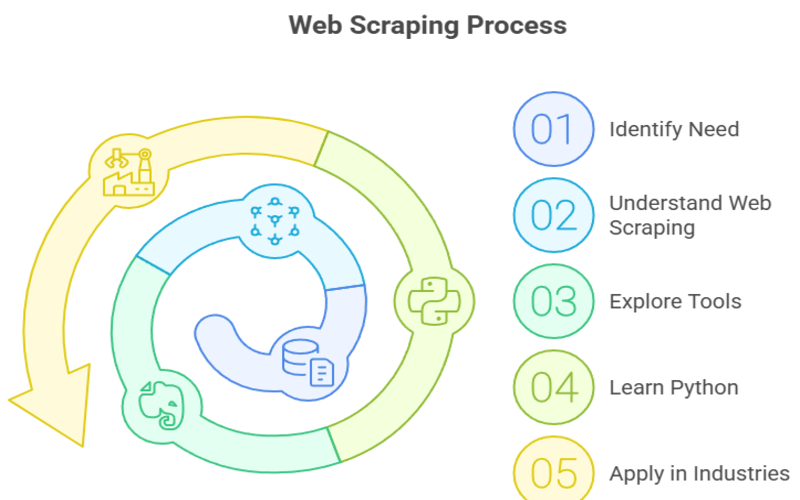
How Web Scrapers Work?
Understanding how web scrapers function will help you appreciate their power and limitations.
Step 1: Fetching the Webpage
Web scrapers start by sending an HTTP request to the target website’s server, just like your browser does when you visit a page. The server responds by sending back the HTML content of the page.
Step 2: Parsing the HTML Content
The scraper then parses the HTML code to locate the data it needs. HTML is structured with tags such as <div>, <span>, <a>, and others that define different parts of the page. By analyzing these tags and their attributes (like classes or IDs), the scraper identifies where the target data is located.
Step 3: Extracting the Data
Once the relevant HTML elements are identified, the scraper extracts the data. For example, it might extract product names, prices, or user reviews from specific tags.
Step 4: Storing the Data
The extracted data is saved into a structured format such as CSV files, Excel spreadsheets, JSON, or databases. This structured data can then be used for analysis, visualization, or integration into other applications.
Handling Complex Web Pages
Modern websites often use JavaScript to load content dynamically. Traditional scrapers that only fetch raw HTML may miss this data. To handle this, scrapers can:
- Use browser automation tools like Selenium to simulate human browsing and execute JavaScript.
- Employ headless browsers that load pages without a graphical interface.
- Use AI-powered scrapers that intelligently interpret complex page structures.
Popular Web Scraping Tools & Libraries

There is a wide range of tools available for web scraping, from beginner-friendly to advanced frameworks. Here are some of the most popular:
Web Scraper (Chrome Extension)
- Best for: Beginners and small projects.
- Features: Visual point-and-click interface, easy to use, no coding required.
- Limitations: Limited scalability and flexibility.
ParseHub
- Best for: Users who want a visual tool with more power.
- Features: Handles JavaScript, pagination, and complex sites.
- Limitations: Paid plans required for large-scale scraping.
Scrapy (Python Library)
- Best for: Developers and data scientists.
- Features: Open-source, highly customizable, supports asynchronous scraping, middleware, and pipelines.
- Advantages: Efficient for large-scale projects, strong community support.
Beautiful Soup (Python Library)
- Best for: Beginners and simple scraping tasks.
- Features: Easy to parse HTML and XML, integrates well with requests library.
- Limitations: Slower for large projects, no built-in crawling.
Selenium
- Best for: Scraping dynamic websites with heavy JavaScript.
- Features: Automates real browsers, simulates user interactions.
- Limitations: Slower than other methods, requires more resources.
Cloud-Based Platforms
- Examples: Zyte (Scrapinghub), Apify, ScrapeOps.
- Best for: Enterprise-level scraping, no local setup needed.
- Features: Proxy management, scheduling, monitoring, data storage.
Types of Web Scrapers
Web scrapers come in various forms, each designed to suit different needs, technical skills, and project scales. Understanding the types of web scrapers helps you choose the right tool for your data extraction goals. Here are the main categories:
Browser Extension Scrapers
Browser extension scrapers are lightweight tools that integrate directly into your web browser, such as Chrome or Firefox. They are ideal for users who want to scrape small amounts of data quickly without installing full software.
These extensions allow you to select data visually on a webpage and export it in formats like CSV. They are beginner-friendly and require no programming knowledge.
Pros:
- Easy to install and use immediately.
- No coding skills needed.
- Great for quick, small-scale scraping tasks.
Cons:
- Limited to scraping one page or small datasets at a time.
- May struggle with complex or dynamic websites.
- Dependent on browser compatibility and updates.
Software-Based Scrapers
Software-based scrapers are standalone applications installed on your computer. They offer more power and flexibility than browser extensions, handling larger datasets and more complex websites. These tools often support scheduling, automation, and customization through programming or graphical interfaces.
Examples include Python libraries like Scrapy and Selenium, as well as desktop tools like Octoparse.
Pros:
- Greater control over scraping tasks and workflows.
- Can handle dynamic content and large-scale scraping.
- Support advanced features like login handling and pagination.
Cons:
- Requires installation and setup.
- May have a steeper learning curve, especially for coding-based tools.
- Uses local computer resources and internet bandwidth.
Cloud-Based Scrapers
Cloud-based scrapers run on remote servers managed by third-party providers. Users configure scraping tasks via web interfaces or APIs, and the service handles data extraction, storage, and delivery. This approach frees up local resources and offers high scalability, reliability, and often features like IP rotation and CAPTCHA solving.
Pros:
- Highly scalable and reliable for large data volumes.
- No need to install software or use local resources.
- Accessible from anywhere with an internet connection.
Cons:
- Usually requires a subscription or pay-as-you-go fees.
- May need technical knowledge to configure and manage.
- Dependent on internet connectivity.
API-Based Scrapers
Some websites provide official APIs (Application Programming Interfaces) that allow users to access their data in a structured, reliable way without traditional scraping. Using APIs is often more efficient and less prone to breaking than scraping HTML pages.
Examples include Twitter API, Google Maps API, and Yelp API.
Pros:
- Reliable and legal access to structured data.
- Less likely to be blocked or throttled.
- Easier to integrate into applications.
Cons:
- Limited to the data the API provider exposes.
- May have usage limits or require authentication.
- Not all websites offer APIs.
Why is Python a Popular Programming Language for Web Scraping?

Python’s popularity in web scraping is no accident. Here’s why:
1. Simple and Readable Syntax
Python’s code is easy to write and understand, making it ideal for beginners and experts alike.
2. Powerful Libraries
- Beautiful Soup: Simplifies HTML parsing.
- Scrapy: Provides a complete scraping framework.
- Requests: Handles HTTP requests easily.
- Selenium: Automates browsers for dynamic content.
- Pandas: Processes and analyzes scraped data efficiently.
3. Strong Community and Resources
Python has a vast community of developers who contribute tutorials, forums, and open-source projects, making learning and troubleshooting easier.
4. Integration with Data Science Tools
Python’s ecosystem includes libraries for data cleaning, machine learning, and visualization, allowing seamless workflows from scraping to analysis.
5. Scalability and Flexibility
Python frameworks like Scrapy support asynchronous scraping and distributed crawling, enabling large-scale data collection.
What is Web Scraping Used For?
Web scraping is a versatile technology that helps businesses and researchers collect valuable data from the web to gain insights, improve decision-making, and automate workflows. Its applications span multiple industries and use cases, enabling organizations to stay competitive and data-driven in 2025.
Market Research and Price Monitoring
One of the most common uses of web scraping is in market research and price monitoring. Companies scrape competitor websites to track product prices, promotions, stock availability, and customer reviews in real-time. This data allows businesses to implement dynamic pricing strategies that adjust prices based on market trends and competitor moves, helping maximize profits and market share.
Lead Generation
Sales and marketing teams use web scraping to gather contact information, company details, and social media profiles from online directories, business listings, and social platforms. Automating this process helps build targeted prospect lists quickly and accurately, supporting personalized outreach and improving conversion rates.
For instance, scraping LinkedIn or industry-specific directories enables marketers to identify decision-makers and influencers relevant to their campaigns.
Real Estate Intelligence
Real estate professionals rely on web scraping to collect comprehensive data on property listings, prices, neighborhood demographics, and market trends from multiple portals. This aggregated data helps agents, investors, and analysts make informed decisions about property valuation, investment opportunities, and market timing.
Academic and Scientific Research
Researchers and academics use web scraping to collect large datasets from online publications, government databases, scientific journals, and forums. This accelerates literature reviews, meta-analyses, and data-driven studies by automating data collection and reducing manual effort.
Sentiment Analysis
Businesses and analysts scrape customer reviews, social media posts, blogs, and forums to analyze public sentiment about products, brands, or events. This data helps companies understand customer satisfaction, detect emerging issues, and refine products or services accordingly. For example, scraping Twitter and Facebook comments allows real-time monitoring of reactions to new product launches or marketing campaigns.
Workflow Automation
Web scraping automates repetitive data collection tasks that would otherwise require significant manual effort, saving time and reducing errors. Organizations use scraping to continuously update databases, track inventory, monitor compliance, and generate reports.
Conclusion
Web scraping is a powerful and versatile technique that enables the automated extraction of valuable data from the internet. It plays a crucial role in data science, business intelligence, market research, and many other fields. Python’s simplicity and rich ecosystem make it the ideal language for web scraping, supported by a wide range of tools and libraries.
As the demand for real-time data grows, mastering web scraping can open doors to exciting career opportunities and research possibilities. Whether you are a data science student or a college researcher, learning web scraping will equip you with a critical skill for the digital age.
Ready to dive deeper? Enroll in our comprehensive Web Scraping with Python course today! Our expert-led program covers everything from beginner basics to advanced AI-powered scraping techniques, complete with hands-on projects and real-world examples. Start your journey to becoming a web scraping expert and unlock the full potential of web data!
Frequently Asked Questions
Is Web Scraping Legal?
The legality depends on the website’s terms of service and applicable laws. Scraping publicly available data is generally allowed, but scraping personal or copyrighted content without permission can be illegal. Always review website policies and respect robots.txt files.
Can I Scrape Websites That Use Javascript?
Yes. Tools like Selenium and headless browsers can execute JavaScript, allowing you to scrape dynamic content.
What Is the Difference Between Web Scraping and Web Crawling?
Web crawling is the process of systematically browsing the web to index pages (used by search engines). Web scraping focuses on extracting specific data from web pages.
How Do AI And Machine Learning Improve Web Scraping?
AI helps identify patterns in complex websites, extract unstructured data, and bypass anti-scraping defenses, making scraping smarter and more efficient.
Can Non-Programmers Do Web Scraping?
Yes. Many no-code tools and browser extensions allow users without coding skills to scrape data visually.
Authors
-

Written by:
Neha SinghReviewed by: