Summary: Uncertainty quantification in machine learning systematically measures and communicates how confident we should be in model predictions. By identifying and managing errors, noise, and model limitations, UQ supports safer, more reliable decisions in fields like healthcare, engineering, and finance. It is essential for building trustworthy, interpretable, and robust AI systems.
Introduction
In the ever-evolving world of artificial intelligence, uncertainty quantification (UQ) has emerged as a critical discipline for building trustworthy, robust, and interpretable models. While machine learning (ML) models celebrate for their predictive power, understanding the confidence behind their predictions is equally vital.
This is where uncertainty quantification steps in, offering a systematic approach to measure, interpret, and manage the unknowns in model predictions.
This blog explores the fundamentals of uncertainty quantification in machine learning, why it matters, the types and sources of uncertainty, key methods, practical applications, and the challenges faced by practitioners. We’ll also provide real-world uncertainty quantification examples, discuss relevant tools and libraries, and answer essential WH questions to guide your understanding.
Key Takeaways
- Uncertainty quantification enhances trust and reliability in machine learning predictions.
- Both aleatoric and epistemic uncertainties must be considered for robust modeling.
- Methods like Bayesian inference, ensembles, and prediction intervals are widely used for UQ.
- UQ is vital in safety-critical domains like healthcare, finance, and autonomous systems.
- Despite challenges, integrating UQ into ML workflows is increasingly accessible with modern tools.
Why Uncertainty Exists in Models
Machine learning models, by their very nature, are built on data and statistical inference. However, real-world data is noisy, incomplete, and often subject to change. Several factors introduce uncertainty into ML models:
- Data Noise: Imperfections or randomness in the data, such as measurement errors or missing values.
- Model Limitations: No model can perfectly capture the complexity of real-world processes.
- Parameter Estimation: Model parameters are estimated from data, and these estimates can vary.
- Changing Conditions: Models trained on historical data may face new, unseen scenarios after deployment.
As a result, every prediction made by a machine learning model carries some degree of uncertainty, making uncertainty quantification in machine learning an indispensable practice4.
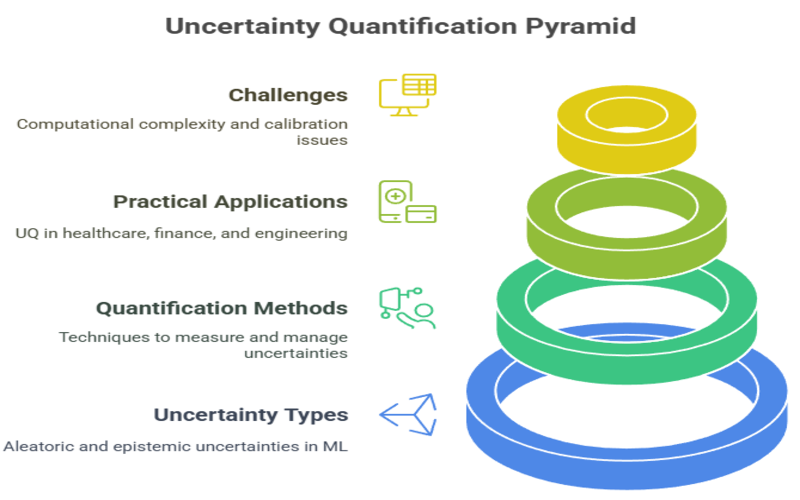
Types of Uncertainty

Understanding the different types of uncertainty is crucial for selecting the right quantification methods and interpreting results accurately. The two primary categories are aleatoric uncertainty and epistemic uncertainty, each with distinct origins, characteristics, and implications for machine learning models.
Aleatoric Uncertainty (Statistical/Irreducible)
Aleatoric uncertainty refers to the inherent randomness or noise in the data itself. This is the type of uncertainty that arises from factors that are fundamentally unpredictable, such as measurement errors, sensor noise, or environmental variability.
Example
Imagine a temperature sensor that sometimes gives slightly different readings under identical conditions due to random fluctuations. This variability is aleatoric uncertainty and is present even if the model and data collection are perfect.
Characteristic
Aleatoric uncertainty is irreducible—no matter how much data you collect, this randomness cannot be eliminated. It is intrinsic to the data-generating process and must be accounted for in model predictions.
Quantification and Mitigation
- Statistical techniques, such as estimating variance or prediction intervals, use to quantify this uncertainty.
- Some models, especially in deep learning, design to explicitly model aleatoric uncertainty by predicting both a mean and a variance for outputs.
- Data augmentation and robust training can help models better represent aleatoric variability, but cannot remove it.
Epistemic Uncertainty (Systematic/Reducible)
Epistemic uncertainty arises from a lack of knowledge about the model or the data-generating process. It reflects what the model doesn’t know due to insufficient, incomplete, or unrepresentative data or limitations in the model structure.
Example
If a machine learning model trained only on images of cats and dogs from one country, it may be uncertain when classifying animals from another country or breed it hasn’t seen before. This uncertainty is epistemic—it exists because the model hasn’t learned enough about the broader world.
Characteristic
Epistemic uncertainty is reducible. It can be decreased by gathering more diverse and high-quality data, improving model architecture, or using more sophisticated learning techniques.
Quantification and Mitigation
- Bayesian methods, such as Bayesian neural networks or Monte Carlo dropout, provide probabilistic estimates of epistemic uncertainty by modeling distributions over model parameters.
- Ensemble methods (training multiple models and aggregating their predictions) can also help estimate epistemic uncertainty, as greater disagreement among models signals higher uncertainty.
- Active learning strategies target data points with high epistemic uncertainty for annotation, making data collection more efficient
Techniques for Quantifying Uncertainty

A variety of uncertainty quantification methods have been developed for machine learning and deep learning. Here are some of the most widely used techniques:
Prediction Intervals
- What: Provide a range within which the true value expected to fall with a certain probability.
- How: Methods like quantile regression or conformal prediction used.
- Uncertainty Quantification Formula: For a prediction y^y^, a 95% prediction interval might be [y^−δ,y^+δ][y^−δ,y^+δ], where δδ is derived from model residuals or quantiles1.
Bayesian Methods
- What: Incorporate prior beliefs and update them with data to produce a posterior distribution over model parameters.
- How: Techniques include Bayesian neural networks and Gaussian processes.
- Example: A Bayesian neural network outputs a distribution of predictions rather than a single value.
Ensemble Methods
- What: Combine predictions from multiple models to estimate uncertainty.
- How: Train several models (e.g., random forests, deep ensembles) and analyze the variance in their outputs.
Monte Carlo Dropout
- What: Use dropout at inference time in neural networks to simulate an ensemble.
- How: Run multiple forward passes with dropout enabled and compute the variance of predictions.
Gaussian Processes
- What: Non-parametric models that provide a full predictive distribution for outputs.
- How: Particularly useful for regression tasks with small to medium-sized datasets.
Surrogate Modeling and Polynomial Chaos Expansion
- What: Build simpler models to approximate complex systems and propagate input uncertainties to outputs.
- How: Useful for computationally expensive simulations..
Conformal Prediction
- What: Produces valid prediction intervals under minimal assumptions.
- How: Can be applied to any underlying model, including deep learning.
Applications of Uncertainty Quantification

Uncertainty quantification (UQ) in machine learning is now central to deploying AI in high-stakes, real-world applications. By systematically measuring and communicating the confidence of model predictions, UQ enables safer, more reliable, and more interpretable decision-making across a wide range of domains. Here are some of the most impactful applications of uncertainty quantification:
Healthcare and Medical Diagnosis
UQ helps clinicians understand how much trust to place in AI-driven diagnoses, treatment recommendations, or predictions about patient outcomes. For example, in medical imaging, Bayesian and fuzzy logic-based UQ methods can highlight when a model is uncertain about a tumor’s presence, prompting additional review or tests.
Uncertainty estimates prevent over-reliance on AI, reducing the risk of errors in critical scenarios like radiology or intensive care.
Engineering Design and Prognostics
In engineering, UQ is used to assess the safety and reliability of components, such as predicting the remaining useful life of batteries or engines. Quantifying uncertainty in these predictions supports maintenance scheduling and risk management.
UQ enables engineers to evaluate the robustness of new designs under uncertain operating conditions, improving system safety and performance.
Earth Observation and Climate Science
For satellite and remote sensing data, UQ helps flag unreliable predictions, guiding further data collection and model improvement.
By providing probabilistic forecasts (e.g., for rainfall or climate events), UQ supports informed decision-making for disaster response and resource management.
Finance and Risk Management
UQ allows financial institutions to gauge the confidence in credit risk models, ensuring that uncertain or borderline cases are flagged for human review.
Traders use UQ to assess the risk of automated trading strategies, helping to avoid large losses due to overconfident but unreliable predictions.
Manufacturing and Quality Control
UQ enables more accurate predictions of equipment failure, allowing for timely interventions and reducing downtime.
By understanding prediction uncertainty, manufacturers can optimize production parameters to minimize defects and waste.
Uncertainty Quantification Example
Consider a deep learning model predicting whether an image contains a tumor. If the model outputs a high probability but also a high uncertainty, clinicians can be alerted to review the case manually, reducing the risk of misdiagnosis.
Tools and Libraries for UQ
A range of open-source tools and libraries support uncertainty quantification in machine learning workflows:
- TensorFlow Probability: Probabilistic modeling and statistical inference in TensorFlow.
- Pyro: Deep probabilistic programming built on PyTorch.
- scikit-learn: Ensemble methods and conformal prediction extensions.
- GPyTorch: Scalable Gaussian process inference with PyTorch.
- Emukit: Framework for decision-making under uncertainty, including Bayesian optimization and experimental design.
- Uncertainty Toolbox: Standardized metrics and visualization for UQ in Python.
Challenges in Uncertainty Quantification
Uncertainty quantification (UQ) in machine learning faces several significant challenges that impact its reliability, interpretability, and practical deployment:
Computational Complexity
Many UQ methods, especially Bayesian approaches and deep ensembles, are computationally intensive and may require major changes to model architecture and training routines. This makes them difficult to scale for large or real-time applications.
Calibration Issues
Achieving well-calibrated uncertainty estimates is challenging. A model may be over-confident (underestimating uncertainty) or under-confident (overestimating uncertainty), both of which can mislead users. Proper calibration ensures that predicted confidence matches the actual probability of correctness.
Distribution Shift and Out-of-Distribution Data
UQ methods often struggle when models encounter data that differs from the training set (distribution shift). For example, Bayesian neural networks may become over-confident on unfamiliar data, undermining the reliability of uncertainty estimates.
Sample Complexity
Some UQ approaches require large amounts of data to provide reliable uncertainty estimates, which is not always feasible, especially in domains with limited or expensive data.
Interpretability and Usability
Effectively communicating uncertainty to end-users is non-trivial. Human operators need to understand and trust uncertainty estimates, which requires thoughtful design of user interfaces, data visualizations, and user training
Conclusion
Uncertainty quantification is an essential aspect of modern machine learning and deep learning, enabling practitioners to build models that are not only accurate but also trustworthy and robust. By understanding and quantifying the unknowns, organizations can make better decisions, manage risks, and foster greater confidence in AI-driven systems.
If you’re looking to master these concepts and apply them in real-world projects, consider enrolling in our advanced courses on machine learning and uncertainty quantification. Our programs combine theoretical foundations with hands-on case studies, equipping you with the skills to navigate the complexities of UQ in today’s data-driven landscape.
Frequently Asked Questions
What Is Uncertainty Quantification in Machine Learning?
Uncertainty quantification in machine learning is the process of measuring and interpreting the confidence or reliability of model predictions, helping users understand when to trust or question automated decisions.
Why Is Uncertainty Quantification Important in Deep Learning?
Uncertainty quantification in deep learning is crucial for safety-critical applications, such as healthcare and autonomous driving, where knowing the model’s confidence can prevent costly or dangerous mistakes.
What Are the Main Methods for Uncertainty Quantification?
Popular uncertainty quantification methods include Bayesian approaches, ensemble models, prediction intervals, Monte Carlo dropout, and conformal prediction. Each method offers different trade-offs in terms of accuracy, interpretability, and computational cost.
Can You Provide an Uncertainty Quantification Example?
A credit scoring model might predict a high likelihood of loan repayment, but with high uncertainty for applicants with limited credit history. This uncertainty can prompt further review before making a lending decision.
Authors
-

Written by:
Aashi VermaReviewed by: