
Summary: Ridge regression in Machine Learning improves model stability and prediction accuracy by adding a regularisation term to address overfitting and multicollinearity. It shrinks coefficients to enhance model generalisation.
Introduction
Regression techniques are essential in Machine Learning for predicting and analysing data relationships. Ridge regression stands out for its ability to handle multicollinearity and improve model prediction accuracy.
Ridge regression, a type of linear regression, includes a regularisation term to prevent overfitting, making it valuable for creating stable and reliable models. This blog will explore ridge regression, its significance in Machine Learning, and how it effectively addresses overfitting issues.
What is Ridge Regression in Machine Learning?
Ridge regression, a type of linear regression, aims to address some limitations of traditional linear regression by incorporating a regularisation term. When dealing with multiple predictor variables, linear regression models can suffer from multicollinearity, where predictors are highly correlated.
This correlation can cause the estimated coefficients to become unstable, leading to overfitting. Overfitting occurs when a model performs well on training data but poorly on new, unseen data.
Ridge regression mitigates this issue by introducing a penalty term to the linear regression equation. This penalty term constrains the sise of the coefficients, effectively shrinking them towards sero.
So, ridge regression reduces the model’s complexity and enhances its generalisation to new data. This approach helps improve the stability and reliability of the regression model, making it more robust and multicollinear.
Mathematical Formula
The ridge regression formula modifies the traditional linear regression equation by adding a regularisation term. The objective of ridge regression is to minimise the following cost function:
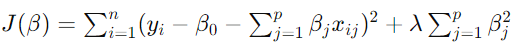
In this formula:
- Jβ is the cost function that ridge regression aims to minimise.
- yi represents the actual value of the dependent variable for the i-th observation.
- β0 is the intercept term.
- βj are the coefficients for the predictor variables xij.
- λ is the regularisation parameter that controls the strength of the penalty term.
 is the penalty term that adds the sum of the squared coefficients to the cost function.
is the penalty term that adds the sum of the squared coefficients to the cost function.
By adjusting λ, you control the impact of the regularisation term. A larger λ value results in greater shrinkage of the coefficients, leading to a simpler model with reduced variance but increased bias. Conversely, a smaller λ value allows the model to fit the data more closely, which may increase variance but reduce bias.
Why Use Ridge Regression?
Ridge regression is a powerful Machine Learning technique that addresses several challenges encountered in traditional linear regression models. Its primary purpose is to enhance model performance by incorporating regularisation. Below, we explore the key reasons for the use of ridge regression.
Overfitting Solution
Ridge regression effectively prevents overfitting by adding a penalty to the sise of the coefficients. The model may fit the training data too closely in standard linear regression, capturing noise rather than the underlying pattern. This overfitting leads to poor performance on new, unseen data.
The model shrinks the coefficients by introducing a regularisation term (lambda λ) in the ridge regression equation, ensuring they remain small and less sensitive to random fluctuations in the training data. This regularisation helps the model generalise new data better, thus improving its predictive accuracy.
Stability
Ridge regression enhances the stability of the regression model, especially in cases with highly correlated predictors (multicollinearity). In ordinary least squares (OLS) regression, multicollinearity can lead to large variances in the coefficient estimates, making the model unstable and unreliable.
Ridge regression addresses this issue by imposing a constraint on the coefficient estimates, making them more robust and stable. This stability is crucial for creating reliable models that perform consistently across different datasets and conditions.
Bias-Variance Trade-off
Ridge regression balances the bias-variance trade-off, a fundamental concept in Machine Learning. In OLS regression, minimising the bias often leads to high variance, resulting in overfitting. Conversely, reducing variance can increase bias, leading to underfitting.
Ridge regression introduces a regularisation parameter (lambda λ) that controls the complexity of the model. By adjusting this parameter, ridge regression finds an optimal balance between bias and variance. This balance ensures that the model neither overfits nor underfits provides a more accurate and reliable prediction.
How Ridge Regression Works
Ridge regression, a crucial regularisation technique in Machine Learning, addresses the issue of overfitting by introducing a penalty term. This method improves regression models’ robustness and predictive performance, especially when dealing with multicollinearity or when the number of predictors exceeds the number of observations.
Regularisation Term
In ridge regression, the regularisation term, denoted by lambda (λ), plays a pivotal role. This term adds a penalty equivalent to the square of the magnitude of the coefficients to the cost function. By doing so, it controls the complexity of the model.
A larger lambda value results in a greater penalty, effectively shrinking the coefficients towards sero. Conversely, a smaller lambda value imposes a lesser penalty, allowing the model to fit the data more closely. The optimal lambda value is usually determined through techniques such as cross-validation.
Parameter Estimation
Estimating parameters in ridge regression involves minimising the modified cost function. Unlike ordinary least squares (OLS) regression, which reduces the sum of squared residuals, ridge regression minimises the sum of squared residuals plus the regularisation term. Mathematically, the cost function in ridge regression is:
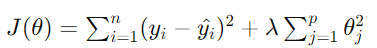
Here, θj represents the regression coefficients. The addition of the regularisation term ![]() ensures that the coefficients are penalised, leading to more stable and reliable parameter estimates.
ensures that the coefficients are penalised, leading to more stable and reliable parameter estimates.
Impact on Coefficients
Ridge regression effectively shrinks the coefficients by balancing the trade-off between fitting the data well and maintaining smaller coefficient values. The shrinkage effect prevents any single predictor from having an undue influence on the model, particularly useful when predictors are highly correlated.
By shrinking the coefficients, ridge regression reduces the model’s variance without substantially increasing its bias. This balance enhances the model’s ability to generalise to new, unseen data, thereby improving its predictive performance.
Implementing Ridge Regression in Python
Implementing ridge regression in Python is straightforward with the help of powerful libraries like NumPy and scikit-learn. This section provides a step-by-step guide to setting up and running a ridge regression model, including how to evaluate its performance.
Libraries: Required Libraries
To get started with ridge regression, you need to install and import the following libraries:
- NumPy: A fundamental package for scientific computing with Python. It provides support for large multi-dimensional arrays and matrices.
- Scikit-learn: A robust Machine Learning library that includes simple and efficient tools for data mining and data analysis.
You can install these libraries using pip if you haven’t already:

Step-by-Step Guide: Code Example Demonstrating Ridge Regression Implementation
Here is a step-by-step guide to implementing ridge regression in Python:
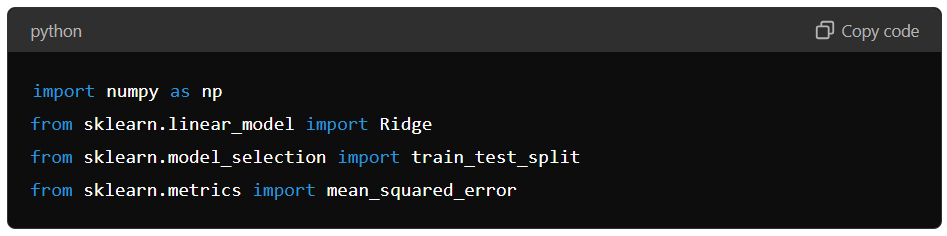
- Import the Libraries:
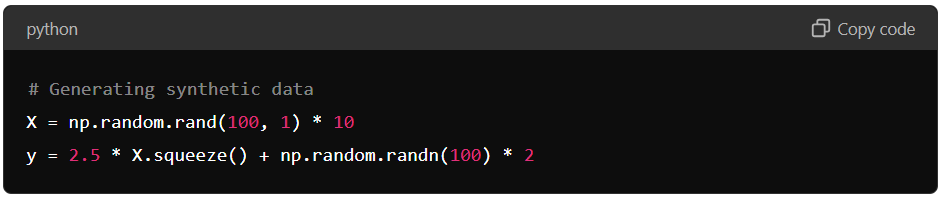
2. Generate or Load the Data:
3. Split the Data:


4. Initialise and Train the Model:

5. Make Predictions:

Evaluation: How to Evaluate the Ridge Regression Model
Evaluating the performance of your ridge regression model is crucial to understanding its effectiveness. Here are the steps to evaluate the model:
- Calculate Mean Squared Error (MSE):

2. Check the Coefficients:

3. Visualise the Results (Optional):
By following these steps, you can effectively implement and evaluate a ridge regression model in Python. This approach helps ensure your model is robust and reliable, addressing issues like overfitting while providing accurate predictions.
Advantages of Ridge Regression
Ridge regression offers several advantages, making it a valuable tool in Machine Learning, particularly for linear regression models facing issues like multicollinearity and overfitting. R ridge regression stabilises the model and enhances its predictive performance by adding a regularisation term to the regression equation. Here are the key advantages of using ridge regression:
Prevents Overfitting
Ridge regression reduces the complexity of the model by shrinking the coefficients. This regularisation helps prevent overfitting, ensuring the model performs well on new, unseen data.
Handles Multicollinearity
In situations where predictor variables are highly correlated, ridge regression provides more reliable coefficient estimates. It minimises the variance of the coefficients, making the model more stable.
Improves Prediction Accuracy
Ridge regression often improves the model’s prediction accuracy by penalising significant coefficients. This regularisation technique balances bias and variance, leading to better generalisation.
Feature Selection
While ridge regression does not perform explicit feature selection like lasso regression, it can still highlight the essential features by reducing the impact of less significant ones.
Computational Efficiency
Ridge regression is computationally efficient, making it suitable for large datasets. It can be easily implemented using popular Machine Learning libraries, such as scikit-learn in Python.
Robustness
The model becomes more robust to small changes in the data, resulting in more consistent and reliable predictions.
Disadvantages of Ridge Regression
Ridge regression is a powerful technique in Machine Learning, especially for addressing multicollinearity and reducing overfitting. However, one must consider its limitations and drawbacks when choosing the appropriate regression method for a specific problem.
Complexity in Interpretation
Ridge regression can interpret the model as more complex due to the shrinkage of coefficients. It becomes harder to understand the impact of each predictor on the response variable.
Bias Introduction
While ridge regression reduces variance, it introduces bias into the model. This trade-off can lead to less accurate predictions if not balanced correctly.
Not Suitable for Feature Selection
Ridge regression includes all the predictors in the final model, even if some have very small coefficients. Unlike lasso regression, which can set some coefficients to sero, it is not practical for feature selection.
Dependency on Regularisation Parameter (Lambda)
The ridge regression performance heavily depends on the choice of the regularisation parameter (lambda). Selecting the optimal lambda requires careful cross-validation, which can be time-consuming.
Sensitivity to Scale of Predictors
Ridge regression is sensitive to the scale of the predictors. The regularisation effect may not be applied uniformly without proper standardisation, leading to skewed results.
Considering these disadvantages, it is crucial to evaluate the context and requirements of your problem before opting for ridge regression.
Comparing Ridge Regression with Other Techniques
Understanding how ridge regression stands out from other regularisation techniques is crucial for making informed decisions when building Machine Learning models. This section compares ridge regression with two popular alternatives: lasso regression and elastic net. Additionally, we explore scenarios where ridge regression is particularly advantageous.
Lasso Regression
Lasso regression (Least Absolute Shrinkage and Selection Operator) is another regularisation technique to prevent overfitting in regression models. Like ridge regression, lasso adds a penalty to the loss function. However, the penalty term is the absolute value of the coefficients (L1 norm) instead of their squared values (L2 norm).
Key Differences:
- Penalty Term: The primary difference between ridge and lasso regression lies in their penalty terms. Ridge regression uses the L2 norm, adding the square of the coefficients to the loss function. In contrast, lasso regression uses the L1 norm, adding the absolute value of the coefficients.
- Effect on Coefficients: Ridge regression tends to shrink coefficients towards sero but does not set any coefficients precisely to sero. Lasso regression, however, can shrink some coefficients to precisely sero, effectively performing feature selection by excluding less essential features from the model.
- Sparsity: Due to its ability to set coefficients to sero, lasso regression often results in sparse models, making them easier to interpret. Ridge regression, while reducing the magnitude of coefficients, generally retains all features in the model.
When to Use Lasso Regression
Lasso regression is instrumental when you suspect that many of your dataset’s features are irrelevant or prefer a simpler, more interpretable model with fewer predictors. It’s advantageous when feature selection is a priority.
Elastic Net
Elastic net is a hybrid regularisation technique that combines ridge and lasso regression penalties. It adds a linear combination of the L1 and L2 norms to the loss function. This approach aims to leverage the strengths of both methods while mitigating their weaknesses.
Key Differences and Similarities:
- Penalty Term: The penalty term in elastic net mixes the L1 and L2 norms. This combination allows for both the shrinkage of coefficients (like ridge) and the sparsity (like lasso).
- Flexibility: The elastic net provides greater flexibility by allowing the user to control the balance between the L1 and L2 penalties through the mixing parameter (alpha). When alpha is 0, the elastic net behaves like ridge regression; when alpha is 1, it behaves like lasso regression.
- Performance: Elastic net is particularly effective when dealing with highly correlated features. While ridge regression may struggle with correlated predictors and lasso may arbitrarily select one predictor, the elastic net can include a group of correlated predictors, providing a more robust solution.
When to Use Elastic Net
An elastic net is ideal for scenarios where you have a large number of correlated predictors. Its ability to balance the L1 and L2 penalties makes it a versatile choice for models that benefit from feature selection and coefficient shrinkage.
Use Cases: When to Use Ridge Regression Over Other Techniques
Choosing the right regularisation technique depends on the specific characteristics of your dataset and the goals of your analysis. Ridge regression is particularly effective in certain situations where its unique advantages can be fully leveraged. Below are scenarios where ridge regression outperforms other techniques.
- High Multicollinearity: Ridge regression excels in situations with high multicollinearity among predictors. By shrinking the coefficients, ridge regression can stabilise the estimates and reduce the variance, making the model more robust.
- All Features are Important: Suppose you believe all features in your dataset are essential and do not want to exclude any predictors. In that case, ridge regression is the appropriate choice. Unlike lasso, which can set coefficients to sero, ridge regression keeps all features in the model.
- Model Interpretability: While ridge regression does not produce a sparse model, it helps balance interpretability and performance. The coefficients are reduced in magnitude, making the model less complex but still inclusive of all features.
- Large Datasets: Ridge regression can efficiently handle large datasets, especially when computational resources are limited. The L2 penalty term simplifies the optimisation process, making ridge regression a faster and more scalable solution.
Closing Statements
Ridge regression in Machine Learning enhances model performance by addressing overfitting and multicollinearity. By introducing a regularisation term, coefficients are shrunk, reducing variance while maintaining a robust model. Ideal for situations with many predictors or high correlation, ridge regression ensures stable and reliable predictions, effectively balancing bias and variance.
Frequently Asked Questions
What is Ridge Regression in Machine Learning
Ridge regression is a linear regression technique with a regularisation term to prevent overfitting. It addresses multicollinearity issues by adding a penalty to the coefficients’ sise. Ridge regression stabilises the model, making it more reliable and accurate in predicting new, unseen data.
How Does Ridge Regression Handle Multicollinearity?
Ridge regression manages multicollinearity by incorporating a regularisation term that penalises large coefficients. This adjustment reduces the variance of the coefficients, making them more stable and reliable, especially when predictor variables are highly correlated. As a result, ridge regression produces a more robust and generalisable model.
When Should I Use Ridge Regression Over Other Techniques?
Opt for ridge regression when facing high multicollinearity or when every feature in your dataset is crucial. It’s beneficial for large datasets and scenarios where maintaining all predictors is essential. Ridge regression balances complexity and performance, ensuring stable predictions even with numerous correlated features.
Authors
-

Written by:
Aashi VermaReviewed by:



