Summary: This blog explores the end-to-end Machine Learning Pipeline, a systematic workflow that automates model creation. We break down each stage—from data processing and model development to deployment. Discover the benefits, history, real-world applications, and why this structured approach is crucial for modern data science success.
Introduction
In today’s tech-driven world, “machine learning” is a term that’s frequently heard, often associated with futuristic robots and complex algorithms. But how do we go from raw data to a smart, predictive model that can recommend your next favorite song or detect fraudulent transactions? The answer lies in a structured and powerful process: the Machine Learning Pipeline.
This end-to-end workflow is the unsung hero behind many of the artificial intelligence applications we use daily. It’s the assembly line of the digital age, transforming unprocessed information into actionable insights and intelligent systems.
Key Takeaways
- An ML pipeline automates the entire machine learning model lifecycle.
- It breaks down complex processes into manageable, repeatable, and efficient stages.
- Key phases include data processing, model development, deployment, and monitoring.
- Pipelines enhance collaboration, scalability, and the reproducibility of your results.
- They are essential for real-world applications across finance, healthcare, and e-commerce.
What is an ML Pipeline?
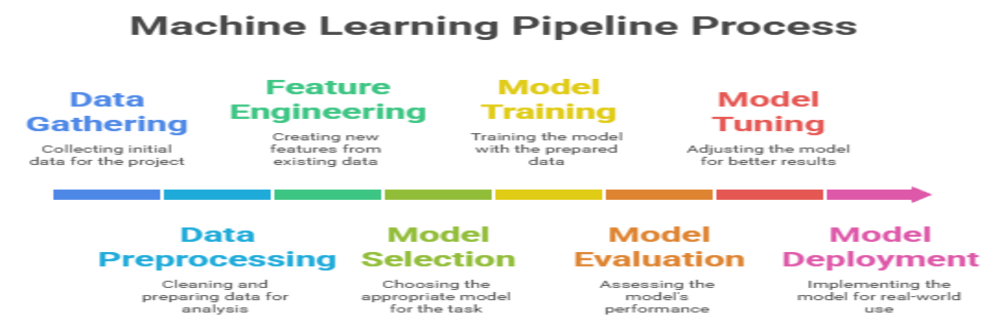
A Machine Learning Pipeline (or ML pipeline) is a systematic, automated workflow that takes a machine learning project from its initial data-gathering phase to the final deployment of a predictive model. Think of it as a recipe for building an AI system; a series of interconnected steps that must followed in a specific order to achieve a successful outcome
This structured approach breaks down the complex process of creating a machine learning model into manageable, repeatable stages. By automating this journey, a pipeline in machine learning makes the development process more efficient, scalable, and reliable.
Data Processing: The Foundation of a Powerful ML Pipeline
Every successful machine learning model is built on a foundation of high-quality, relevant data. The data processing stage, often the most time-consuming part of the entire process, is where this foundation is laid. It involves several critical steps:
Data Ingestion/Collection
The first step is to gather raw data from various sources, which could include databases, APIs, CSV files, or even images and text.
Data Preprocessing and Cleaning
Raw data is often messy, incomplete, or inconsistent. This step involves “cleaning” the data by handling missing values, removing duplicate entries, and correcting errors.
Feature Engineering
This is the creative heart of data processing. It involves selecting the most relevant features (variables) from the data and sometimes creating new ones that will help the model make more accurate predictions. This process transforms the cleaned data into a format that optimiz for the machine learning algorithm.
Model Development: Bringing Intelligence to Life
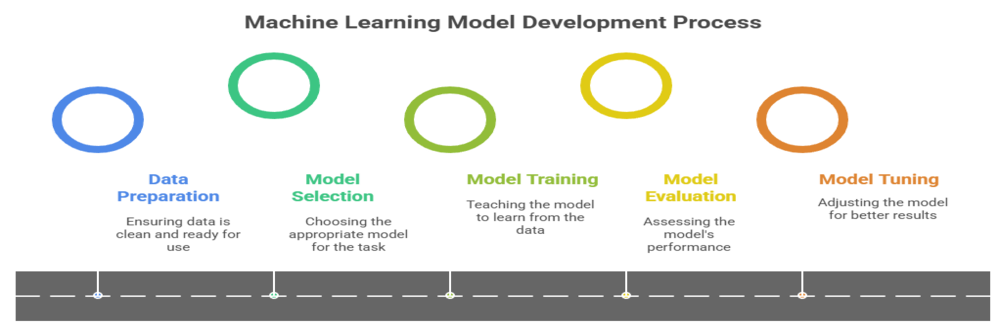
With the data prepared, the next phase is to build and train the machine learning model. This is where the “learning” in machine learning truly happens. The key stages are:
Model Selection
Data scientists choose the most appropriate algorithm for the problem at hand, whether it’s for classification (e.g., spam detection), regression (e.g., house price prediction), or clustering.
Model Training
The selected algorithm is fed the prepared data. During this training process, the model learns to identify patterns and relationships within the data. This often involves minimizing a “loss function,” which measures the gap between the model’s predictions and the actual values.
Model Evaluation and Tuning
Once trained, the model’s performance is rigorously evaluated using a separate set of test data. If the model isn’t accurate enough, its parameters (hyperparameters) are adjusted and the model retrain in an iterative process until it meets the desired performance level.
Model Deployment: Unleashing the Model into the Real World
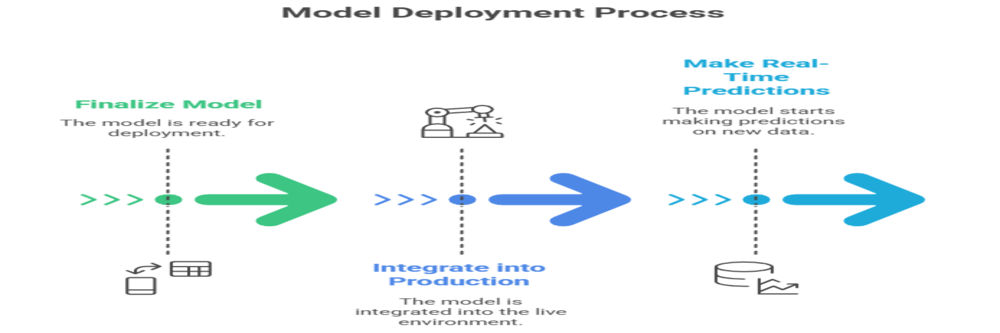
A trained model is only useful if it can be put to work. Model deployment is the process of integrating the finalized model into a live production environment where it can make real-time predictions on new, unseen data.
Common deployment strategies include:
Shadow Deployment
The new model runs alongside the existing one without impacting users, allowing for real-world performance comparison.
Canary Deployment
The new model is gradually rolled out to a small subset of users before being released to everyone.
Blue-Green Deployment
Two identical production environments maintained, allowing for seamless switching to the new model once it’s validated.
After deployment, continuous monitoring is crucial to ensure the model’s performance doesn’t degrade over time, a phenomenon known as “model drift”.
Machine Learning Workflow Benefits: Why It Matters
Adopting a machine learning pipeline architecture offers numerous advantages that streamline the entire process from start to finish.
Increased Efficiency and Productivity
By automating repetitive tasks like data preprocessing and model training, pipelines save valuable time and reduce the potential for human error.
Enhanced Reproducibility and Consistency
A standardized workflow ensures that experiments are repeatable and results are consistent, which is crucial for reliable model development.
Improved Collaboration
Pipelines provide a clear and structured framework, making it easier for teams of data scientists, engineers, and developers to collaborate effectively.
Scalability
The modular nature of a pipeline in machine learning allows for individual components to be scaled independently, making it easier to handle large datasets and complex models.
A Look Back: The History of Machine Learning Pipelines
The concept of automated workflows isn’t new, but the formalization of the machine learning pipeline is a more recent development tied to the rise of data science.
Pre-2000s
Early data processing was largely manual or relied on simple scripts and spreadsheets. The Cross-Industry Standard Process for Data Mining (CRISP-DM), established in 1996, provided a foundational framework for data mining projects.
2000s
As machine learning gained traction, the need for more systematic workflows became apparent.
Late 2000s – Early 2010s
The emergence of “data science” as a field solidified the data-driven workflows that are now integral to machine learning pipelines.
2010s and Beyond
The rise of Automated Machine Learning (AutoML) has further revolutionized pipelines by automating tasks like hyperparameter tuning and model selection, making machine learning more accessible to a broader audience.
Real-World Applications of ML Pipelines
From your daily commute to your entertainment choices, machine learning pipelines are working behind the scenes in numerous industries:
E-commerce and Marketing
Recommender systems on platforms like Netflix and Amazon use pipelines to analyze your viewing and purchasing history to suggest what you might like next.
Financial Services
Banks and financial institutions use ML pipelines for fraud detection, credit scoring, and assessing financial risk.
Healthcare
In healthcare, pipelines are used for tasks like medical image analysis to detect diseases and for predicting patient outcomes..
Social Media
Platforms leverage pipelines to personalize content feeds, target advertising, and detect and remove inappropriate content.
Closing Thoughts
The Machine Learning Pipeline is the operational backbone of modern artificial intelligence. It converts the complex, iterative process of building a model into a streamlined, automated, and scalable workflow.
By ensuring efficiency, reproducibility, and reliability, the ML pipeline is no longer just an advantage. It has become a fundamental necessity for any organization aiming to harness the full power of data and drive meaningful innovation in a competitive, data-driven world.
Frequently Asked Questions
What is a machine learning pipeline?
A machine learning pipeline is an end-to-end, automated workflow for building, training, and deploying a machine learning model. It breaks down the entire process into a series of connected steps, including data collection, preprocessing, model training, evaluation, and deployment, to make the development process more efficient, consistent, and scalable.
Why is a machine learning pipeline important in data science?
A machine learning pipeline is crucial in data science because it brings structure and automation to the complex process of model development.
This is important for several reasons: it increases efficiency by automating repetitive tasks, ensures results are reproducible, and improves collaboration among team members. Ultimately, it helps data scientists move models from experimentation to production faster and more reliably.
Which industries benefit most from ML pipelines?
A wide range of industries benefit from ML pipelines due to their ability to process vast amounts of data and generate predictive insights. Key sectors include:
- Financial Services for fraud detection and risk assessment.
- Healthcare for improved diagnostics and personalized treatment plans.
- Marketing and E-commerce for personalized recommendations and customer analytics.
- Government for optimizing processes and making data-driven decisions.
- Oil and Gas for efficient resource exploration.
Authors
-

Written by:
Neha SinghReviewed by: