
Summary: This guide covers various methods for data importing in Python, from CSV and Excel files to APIs and cloud storage. It provides practical tips for efficient data integration.
Introduction
Data importing in Python is a crucial skill for anyone entering the world of data science, machine learning, or data analysis.
Imagine the global data integration market growing from $15.24 billion in 2024 to over $47.60 billion by 2034, with a compound annual growth rate (CAGR) of 12.06%. With such an explosion in data usage, the ability to easily import and manage data has never been more critical.
But don’t worry – we’ve got your back! This cheat sheet will guide you through all the significant ways to import data into Python in simplest and quickest way possible, no matter what type of data you’re dealing with.
Key Takeaways
- Python offers powerful libraries like Pandas and NumPy for data importing.
- CSV, Excel, JSON, and SQL are common data formats you’ll encounter.
- Handling encoding issues is crucial when importing data.
- APIs allow real-time data access for dynamic analysis.
- Best practices like limiting data and using the right library boost efficiency.
Let’s Dive into the World of Data Importing
Before you get deep into analysing, cleaning, or visualising your data, you need to know how to import it correctly. Python offers several libraries that make importing data a breeze.
In this cheat sheet, we’ll walk through the most common types of data you might encounter, like CSV files, Excel spreadsheets, JSON files, and much more. We’ll also explore some nifty tools that will help you handle everything like a pro.
Importing Data from CSV Files
CSV (Comma-Separated Values) files are the bread and butter of data storage. Whether it’s a simple list or a massive dataset, CSVs store data in a clean, tabular format. Python, with its friendly Pandas library, makes importing CSV files as easy as pie. Here’s how you do it:

Key Points to Remember:
- filename: This is the path to your CSV file (don’t forget the .csv extension!).
- header: You can specify which row to treat as the column headers (defaults to 0, meaning the first row).
delimiter: If your file uses a different delimiter, like semicolons (;), you can specify it here. - nrows: If you don’t want to read the whole file, you can specify how many rows to load.
- skiprows: Need to skip some rows? No problem!
Pandas also gives you options to handle missing data, and you can even set the data type for each column to make sure everything stays in check!
Importing Data from Excel Files
Excel files are another common source of data. Thanks to Pandas, importing Excel files is just as simple as working with CSV files. Check out the code below:

Key Points to Remember:
- filename: Path to your Excel file (make sure it’s .xlsx).
- sheet_name: Name of the worksheet you want to read (you can specify it or default to the first sheet).
- header: Same as CSVs, choose which row to use as column names.
If you’re dealing with multiple sheets or complex Excel files, Pandas will make your life easier with a simple function call.
Importing Data from Flat Files
Flat files are plain text files, and they come in different forms like CSV or TSV (Tab-Separated Values). When working with large files, NumPy is an excellent tool for importing data.

Key Points to Remember:
- filename: Path to your file.
- delimiter: If it’s a CSV, use ,; for tab-separated files, use \t.
- dtype: You can specify the data type of each column here (e.g., int, float).
NumPy can handle huge datasets and is especially great for numerical data.
Importing Data from JSON Files
JSON (JavaScript Object Notation) is widely used for data exchange, especially in web applications. Python’s built-in json module makes importing JSON files super easy. Here’s how you can do it:

Managing Different Data Formats and Encodings
After importing your data, you may encounter issues with character encoding, especially if your file contains special characters (such as é, ü, etc.). Python makes it easy to handle encoding issues. If you’re unsure about the encoding, you can use the Chardet library to detect the encoding automatically:

Importing Data from SQL Databases
Working with databases is another essential aspect of data science. SQLAlchemy and Pandas allow you to query databases and import data into Python in a few simple steps. Let’s look at how you can import data from an SQL database:
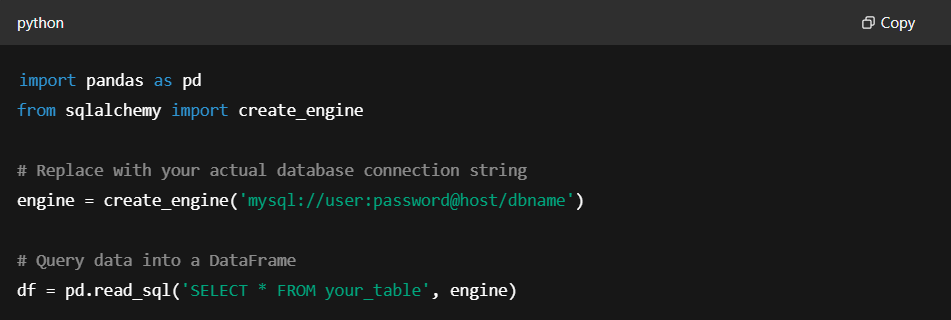
With SQLAlchemy, you can connect to various types of databases, including MySQL, PostgreSQL, SQLite, and more.
Importing Data from APIs: Bringing Data from the Web
Sometimes, the data you need isn’t stored in a local file or database but is accessible through APIs (Application Programming Interfaces). Python makes it easy to interact with web APIs and retrieve data, especially when you need real-time or frequently updated data. The requests library is commonly used for this purpose.
Here’s how you can fetch data from a web API:

Key Points to Remember:
- url: The API endpoint you want to fetch data from.
- .json(): A method to parse the returned data as a JSON object.
Using APIs allows you to pull data from a variety of sources, such as weather information, stock prices, or social media metrics.
Importing Data from Cloud Storage: Accessing Files from the Cloud
With the rise of cloud computing, a lot of data is stored on platforms like Google Drive, AWS S3, or Azure Blob Storage. Luckily, Python provides libraries to access these cloud storage solutions directly.
For example, to access data from AWS S3, you can use the boto3 library. Here’s how you would get started:
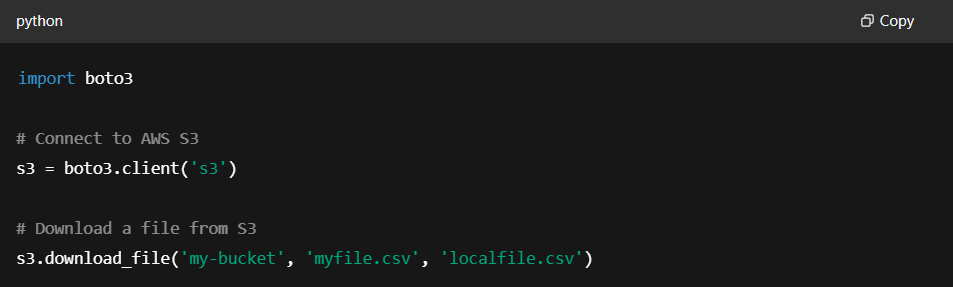
Key Points to Remember:
- boto3.client(‘s3’): Initializes the connection to AWS S3.
- download_file: Downloads a file from your S3 bucket to your local machine.
Advanced Data Importing with Python
Now that you’ve got the basics down, let’s talk about some advanced techniques. If you’re dealing with very large datasets, you can use Dask for parallel processing or work with PySpark for distributed computing. These tools allow you to handle data too large for traditional in-memory approaches.
Best Practices for Efficient Data Importing
To make your data importing smooth, consider the following best practices:
- Use the Right Library: Pandas, NumPy, and SQLAlchemy are excellent tools, but always choose the best one for your specific use case.
- Check the Data’s Encoding: Always make sure your data is properly encoded to avoid any mishaps during analysis.
- Limit the Data You Import: If your dataset is too large, only import the columns or rows you need to keep your work efficient.
What Does It Mean For You?
In data science, data importing is a foundational skill that can significantly impact the speed and accuracy of your analyses. Whether you’re handling CSV files, Excel sheets, JSON, or databases, Python’s vast ecosystem of libraries makes it easier to import data for further processing.
With tools like Pandas, NumPy, and SQLAlchemy, you can seamlessly integrate data into your projects. If you’re eager to learn more about data science and master these skills, consider enrolling in data science courses at Pickl.AI. Join today and get hands-on experience to boost your career in data science!
Frequently Asked Questions
What is data importing in Python?
Data importing in Python involves bringing data from external sources like files, databases, or APIs into Python for analysis. Popular libraries like Pandas and NumPy make it easy to work with different file formats such as CSV, Excel, and JSON.
How do I import data from an SQL database into Python?
To import data from an SQL database into Python, use SQLAlchemy or Pandas. SQLAlchemy establishes a connection to the database, and Pandas reads the data into a DataFrame for easy manipulation and analysis.
What is the best library for importing CSV files in Python?
The best library for importing CSV files in Python is Pandas. It’s efficient and offers options to handle missing values, set data types, and control the header rows while reading large CSV files.
Authors
-

Written by:
Neha SinghReviewed by:



