
Summary: Feature scaling in Machine Learning ensures equitable feature contributions by standardising numerical data and enhancing algorithm performance and stability. It mitigates biases towards larger-scale features, accelerates convergence in optimisation algorithms, and improves model robustness against outliers.
Introduction
In the ever-evolving landscape of Machine Learning, scaling plays a pivotal role in refining models’ performance and robustness. Among the many techniques available to enhance the efficacy of Machine Learning algorithms, feature scaling stands out as a fundamental process.
In this comprehensive article, we delve into the depths of feature scaling in Machine Learning, uncovering its importance, methods, and advantages while showcasing practical examples using Python.
Understanding Feature Scaling in Machine Learning
Feature scaling stands out as a fundamental process. In this comprehensive article, we delve into the depths of feature scaling in Machine Learning, uncovering its importance, methods, and advantages while showcasing practical examples using Python.
Let’s give a simplified explanation for this:
Let’s say that in a dataset, men’s weights range between 15kg and 50 kg. Then, feature scaling will standardise this as 0 and 1, where 0 means the lowest value and 1 means the highest.
Why Feature Scaling is Important in Machine Learning?
Feature scaling is crucial in Machine Learning for several reasons. First, it ensures that all features contribute equally to the model’s training process, preventing any one feature from dominating due to its larger scale.
This balance enhances the model’s accuracy and stability during training and prediction. Secondly, feature scaling aids algorithms that use distance-based calculations, such as k-nearest neighbours and support vector machines, by normalising distances across all features.
This normalisation prevents biases towards larger-scale features, improving the model’s performance and convergence. Overall, feature scaling in Machine Learning enhances model efficiency, accuracy, and robustness across diverse datasets.
Critical Attributes of Feature Scaling in Machine Learning
Understanding key attributes of feature scaling in Machine Learning is crucial for optimal model performance. It ensures data consistency, prevents bias towards certain features, and enhances algorithm convergence.
Uniform Feature Magnitudes for Optimal Learning
At the heart of scaling lies the principle of achieving uniformity in feature magnitudes. Scaling ensures that all features contribute proportionally to the learning process, preventing any feature from dominating the algorithm’s behaviour. This feature equality fosters an environment where the algorithm can discern patterns and relationships accurately across all data dimensions.
Algorithm Sensitivity Harmonisation
Machine Learning algorithms often hinge on distance calculations or similarity measures. Features with divergent scales can distort these calculations, leading to biased outcomes. Scaling steps in as a guardian, harmonising the scales and ensuring that algorithms treat each feature fairly.
This harmonisation is particularly critical in algorithms such as K-Nearest Neighbors and Support Vector Machines, where distances dictate decisions.
Convergence Enhancement and Faster Optimization
Scaling expedites the convergence of optimisation algorithms. Techniques like gradient descent converge faster when operating on features with standardised scales. The even playing field offered by scaling empowers optimisation routines to traverse the solution space efficiently, reducing the time and iterations required for convergence.
Robustness Against Outliers
Scaling, primarily via methods like standardisation, endows models with enhanced robustness against outliers. Extreme values that would otherwise exert disproportionate influence are tamed when features are scaled. This resilience to outliers translates into more reliable and stable predictions, as the model is less susceptible to extreme data points.
Model Interpretability and Transparency
Scaled features facilitate model interpretability. The standard scale allows practitioners to discern the impact of each feature on predictions more clearly. Interpretable models build trust, enabling stakeholders to understand the rationale behind decisions and glean actionable insights from the model’s outputs.
Effective Regularisation and Complexity Control
Scaling lays the foundation for effective regularisation. Techniques like L1 and L2 regularisation, designed to manage model complexity, perform optimally when features are scaled. Scaling ensures that regularisation operates uniformly across all features, preventing any single feature from dominating the regularisation process.
Stable and Consistent Model Behaviour
Scaled features promote stability and consistency in model behaviour. When input data exhibits varied scales, small changes in one feature might lead to erratic shifts in model predictions. Scaling mitigates this instability, resulting in more dependable and predictable model outcomes.
Reduction of Dimensionality Bias
In high-dimensional datasets, larger-scale features can inadvertently receive higher importance during dimensionality reduction techniques like Principal Component Analysis (PCA). Scaling prevents this bias, allowing PCA to capture the actual variance in the data and extract meaningful components.
Key Application of Feature Scaling in Machine Learning
Looking at the key applications of feature scaling in Machine Learning is crucial for enhancing model performance. It ensures that variables are on a similar scale, preventing biases towards certain features. The application of feature scaling is rooted in several key reasons:
- Alleviating Algorithm Sensitivity: Many Machine Learning algorithms are sensitive to the scale of input features. Without scaling, algorithms such as K-Nearest Neighbors (KNN), Support Vector Machines (SVMs), and clustering techniques might not give accurate results as they calculate distances or similarities between data points.
- Accelerating Convergence: Feature scaling can significantly speed up the convergence of iterative optimisation algorithms, such as gradient descent. Normalising or standardising features makes the optimisation process more stable and efficient.
- Enhancing Model Performance: Scaling helps improve models’ performance by ensuring that no single feature dominates the learning process. This balance in influence contributes to more accurate predictions.
Advantages of Feature Scaling in Machine Learning

Understanding the advantages of feature scaling in Machine Learning is crucial for enhancing model performance. It ensures that all features contribute equally and facilitates faster convergence in algorithms like gradient descent. This optimisation ultimately leads to more accurate and reliable predictions. The advantages of employing feature scaling are multifaceted:
Enhanced Model Convergence and Efficiency
Feature scaling paves the path to faster and more efficient convergence during the training of Machine Learning algorithms. Optimisation techniques, such as gradient descent, tend to converge more swiftly when features are on a comparable scale. Scaling assists these algorithms in navigating the optimisation landscape more effectively, thereby reducing the time required for model training.
Algorithm Sensitivity Mitigation
Many Machine Learning algorithms rely on distance calculations or similarity metrics. Features with differing scales can unduly influence these calculations, potentially leading to suboptimal results.
By scaling features to a standardised range, we mitigate the risk of certain features overpowering others and ensure that the algorithm treats all features equitably, thus enhancing the overall performance and fairness of the model.
Robustness to Outliers
Scaling techniques, particularly standardisation, make Machine Learning models more robust to outliers. Outliers can disproportionately impact algorithms like linear regression and can be tamed by standardising features. Standardisation assigns less weight to extreme values, preventing outliers from unduly affecting model coefficients and predictions.
Equitable Feature Contributions
Feature scaling levels the playing field for all features in a dataset. When features have disparate scales, those with larger scales may dominate the learning process and overshadow the contributions of other features. Scaling ensures that each feature contributes proportionally to the model’s performance, promoting a balanced and accurate data representation.
Improved Model Interpretability
Scaled features improve model interpretability. When features are on a common scale, it becomes easier to understand and compare their respective contributions to predictions. This interpretability is particularly valuable in scenarios where explaining model outputs is essential for decision-making.
Optimised Regularisation Performance
Regularisation techniques, such as L1 and L2 regularisation, are more effective when features are scaled. Scaling prevents any single feature from dominating the regularisation process, allowing these techniques to apply the desired level of constraint to all features uniformly. As a result, the model achieves better control over complexity, leading to improved generalisation.
Stable Model Behavior
Feature scaling promotes stable and consistent model behaviour. With scaled features, the model’s predictions become less sensitive to variations in the input data, reducing the likelihood of erratic outputs. This stability enhances the model’s reliability and trustworthiness.
Methods of Scaling in Machine Learning
Understanding methods of scaling in Machine Learning is crucial for optimising model performance. This enhances model accuracy and convergence speed and improves Machine Learning algorithms’ stability. Two prominent methods of scaling are Normalisation and Standardisation:
Feature Scaling Data Normalisation: Min-Max Scaling

Normalisation transforms features to a range between 0 and 1. The formula for normalisation is:
Where X is the original feature value, X_min is the minimum value of the feature, and X_max is the maximum value of the feature.
Feature Scaling Data Standardisation: Z-Score Scaling

Standardisation scales feature to have a mean of 0 and a standard deviation of 1. The formula for standardisation is:
Where X is the original feature value, mean(X) is the mean of the feature, and std(X) is the standard deviation of the feature.
Feature Scaling in Python
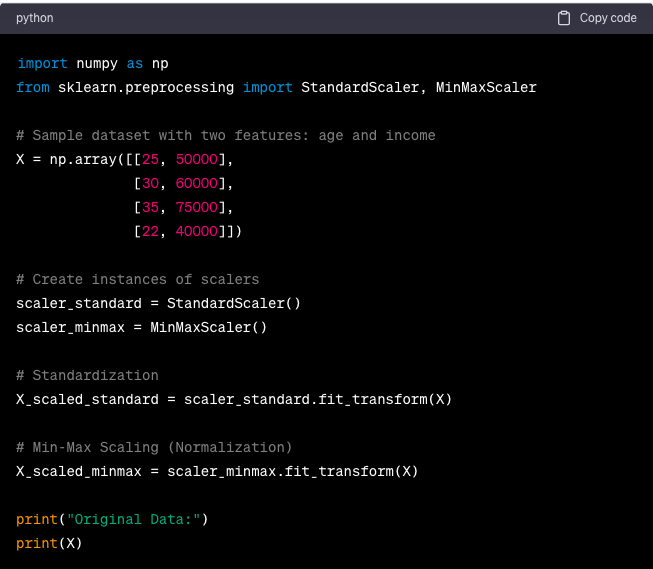
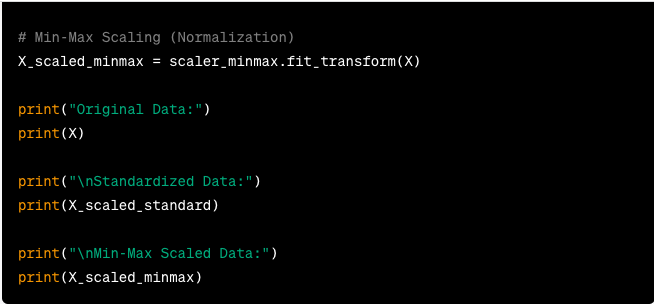
Feature scaling in Machine Learning refers to standardising or normalising the numerical features in a dataset so that they are on a similar scale. Scaling is essential because many Machine Learning algorithms perform better when features are approximately on the same scale. Here’s an example of feature scaling in Python using the Scikit-learn library:
Frequently Asked Questions
What is feature scaling in Machine Learning?
Feature scaling adjusts numerical data to a standardised range, like 0 to 1 or a mean of 0 and a standard deviation of 1. This process ensures all features contribute equally to model training, preventing bias from skewed scales and optimising algorithm performance across diverse datasets.
Why is feature scaling important in Machine Learning?
Feature scaling is crucial to prevent any feature from dominating model training due to its more significant scale. It enhances algorithm accuracy, particularly in distance-based calculations like k-nearest neighbours and SVMs, by normalising feature distances and improving convergence and predictive reliability.
How do you perform feature scaling in Python?
In Python, Scikit-learn provides robust methods for feature scaling. Normalise data using Min-Max scaling to fit within a specified range, or standardise with Z-score scaling to adjust data around its mean and standard deviation. These techniques ensure consistent, optimised performance of Machine Learning models.
The Way Ahead
With all this and much more, Machine Learning is a powerful technology. Having expertise in this domain will give you an edge over your competitors. To start your learning journey in Machine Learning, you can opt for a free course in ML. This course will help develop your fundamentals in ML, and later, you can pursue a full-time course to sharpen your skills further.
Authors
-

Written by:
Smith AlexReviewed by:



