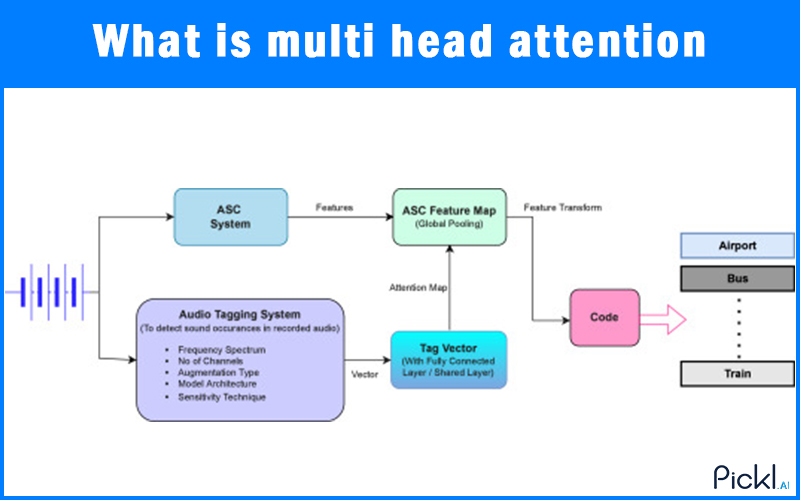
Summary: This blog explains Multi-Head Attention, a core Transformer mechanism. It details how multiple “heads” simultaneously focus on different aspects of data, enhancing understanding by capturing diverse relationships. Learn its formula, how it differs from self-attention, and its broad applications in modern AI.
Introduction
Imagine trying to understand a complex sentence. You don’t just read it word by word in isolation. Your brain simultaneously focuses on different parts of the sentence – identifying subjects, verbs, objects, and how they relate to each other, even if they’re far apart.
This ability to focus on multiple aspects at once is what makes human comprehension so powerful. In the world of Artificial Intelligence, particularly with the rise of Transformer models, a similar mechanism exists for machines: Multi-Head Attention.
The Transformer architecture, first introduced in the groundbreaking paper “Attention Is All You Need,” revolutionized Natural Language Processing (NLP) and has since become the backbone for many state-of-the-art models like BERT, GPT, and T5.
At the very heart of this revolution lies the Multi-Head Attention mechanism, a brilliant innovation that allows these models to process information with unparalleled depth and understanding.
The Need for Attention
Before Transformers, recurrent neural networks (RNNs) and convolutional neural networks (CNNs) were the dominant architectures for sequence processing. While effective, they struggled with long-range dependencies – remembering information from the beginning of a long sentence or document when processing words at the end. They also processed information sequentially, which was computationally expensive and slow.
Attention mechanisms were introduced to address these limitations. Simple “Self-Attention” allowed a model to weigh the importance of other words in a sequence when processing a specific word. For example, in the sentence “The animal didn’t cross the street because it was too tired,” the word “it” refers to “animal.” A self-attention mechanism could establish this connection, regardless of how far apart “it” and “animal” were.
However, a single attention mechanism might struggle to capture all the different types of relationships within a sequence. This is where the ingenuity of Multi-Head Attention shines.
What is Multi-Head Attention?
Multi-Head Attention is an enhancement of the standard self-attention mechanism. Instead of performing a single attention calculation, it performs several of them in parallel. Each “head” or individual attention mechanism learns to focus on different aspects or relationships within the input sequence. Think of it like having multiple specialized spotlight operators, each highlighting a different crucial part of a stage performance simultaneously.
These independent “heads” then concatenate their outputs, which are then linearly transformed to produce the final result. This parallel processing allows the model to jointly attend to information from different representation subspaces at different positions. In simpler terms, it can capture a richer, more diverse set of relationships and dependencies in the data.
How Does Multi-Head Attention Work?

Let’s break down the mechanics of Multi-Head Attention in Transformer models.
The core idea of attention revolves around three vectors for each word in the input sequence:
- Query (Q): This vector represents the current word we are trying to understand.
- Key (K): This vector represents all other words in the sequence.
- Value (V): This vector also represents all other words, carrying the actual information to be extracted.
In a single self-attention head:
- We calculate “attention scores” by taking the dot product of the Query with all Keys. This tells us how relevant each other word (Key) is to the current word (Query).
- These scores are then scaled and passed through a softmax function to get attention weights. The softmax ensures that all weights sum up to 1, effectively creating a probability distribution over the other words.
- Finally, these attention weights are multiplied by the Value vectors and summed up. This weighted sum becomes the output of the attention head, effectively aggregating information from relevant words, weighted by their importance.
Now, for Multi-Head Attention:
Instead of deriving one set of Q, K, and V vectors directly from the input embedding, the input embedding is first projected linearly h times (where h is the number of heads) into h different, lower-dimensional Q, K, and V spaces.
Projection
For each head, the original input embeddings are transformed using different learned linear projections (weight matrices) to create separate Q, K, and V matrices for that specific head.
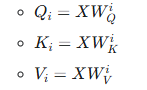
where XX is the input, and WQi,WKi,WViWQi,WKi,WVi are the unique weight matrices for head ii.
Parallel Attention
Each of these h sets of (Q, K, V) then undergoes an independent self-attention calculation. This produces h different “attended” outputs,
- Headi=Attention(Qi,Ki,Vi)
- The Attention(Q,K,V)Attention(Q,K,V) function itself is typically: softmax(QKTdk)Vsoftmax(dkQKT)V
where dkdk is the dimension of the key vectors. This is the core Multi-Head Attention formula.
Concatenation
The outputs from all h attention heads (Head1,Head2,…,HeadhHead1,Head2,…,Headh) are then concatenated side-by-side.
Final Linear Transformation
This concatenated output is then passed through a final linear projection (another learned weight matrix) to transform it back into the desired output dimension. This ensures the output can be fed into the next layer of the Transformer.
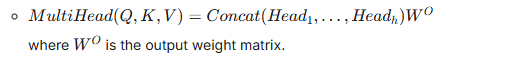
This process allows each head to potentially learn different types of relationships – one head might focus on grammatical dependencies, another on semantic similarities, and yet another on coreferencing.
Multi-Head Attention Formula
To formalize what we discussed:
Let the input sequence be represented by a matrix
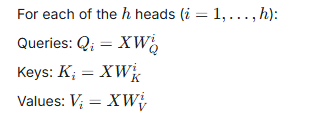
The attention function for each head is calculated as:
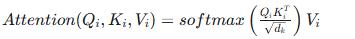
where dkdk is the dimension of the key vectors (typically dmodel/hdmodel/h).
The outputs of all heads are then concatenated and linearly transformed:
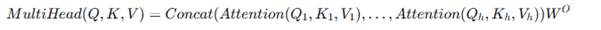
Where WQi,WKi,WVi∈Rdmodel×dkWQi,WKi,WVi∈Rdmodel×dk are projection matrices, and
WO∈Rh⋅dk×dmodelWO∈Rh⋅dk×dmodel is the final output projection matrix. dmodeldmodel
is the dimension of the model’s embeddings.
Multi-Head Attention Example
Consider the sentence: “The quick brown fox jumps over the lazy dog.”
A single attention head might learn to connect “fox” with “jumps” (subject-verb). However, another head might learn to connect “quick” with “fox” and “lazy” with “dog” (adjective-noun relationship). A third head might capture the long-range dependency between “jumps over” and “dog” (verb phrase with object).
When all these heads are combined, the model gets a much richer and more nuanced understanding of the sentence, capturing various syntactic and semantic relationships simultaneously. This parallel processing of different “views” of the input is what makes Multi-Head Attention so powerful.
Multi-Head Attention vs. Self-Attention
It’s crucial to understand that Multi-Head Attention vs. Self-Attention isn’t an “either/or” situation; rather, multi-head attention is an extension of self-attention.
Self-Attention
A single mechanism that computes attention weights between a token and all other tokens in the same sequence. It allows the model to weigh the importance of other words when encoding a particular word. It’s like having one perspective on the relationships.
Multi-Head Attention
Consists of multiple parallel self-attention mechanisms (heads). Each head learns different linear projections of the input and thus focuses on potentially different parts of the sequence, capturing a wider range of relational information. It’s like having multiple perspectives, which are then combined for a more comprehensive understanding.
The key advantage of Multi-Head Attention over a single self-attention mechanism is its ability to jointly attend to information from different representation subspaces. This means it can model diverse types of dependencies (e.g., syntactic, semantic, long-range, and short-range) simultaneously and robustly.
Advantages of Multi-Head Attention
Multi-head attention provides substantial advantages such as enhanced expressiveness, parallel learning of diverse patterns, improved generalization, increased robustness, and greater training stability in modern deep learning models.
Captures Diverse Relationships
Each head can learn to focus on different types of relationships, leading to a richer and more comprehensive understanding of the input.
Enhanced Representational Capacity
By having multiple perspectives, the model can extract more features and nuances from the input sequence.
Improved Robustness
If one head fails to capture a certain dependency, others might succeed, making the overall mechanism more robust.
Parallel Computation
The calculations for each head can be performed in parallel, which is computationally efficient compared to sequential processing in RNNs.
Handles Long-Range Dependencies
Like self-attention, it directly computes relationships between any two positions, regardless of their distance, effectively solving the long-range dependency problem.
Applications of Multi-Head Attention
The impact of Multi-Head Attention extends across various domains:
Natural Language Processing (NLP)
Machine Translation: Accurately translating sentences by understanding how words in one language relate to words in another.
Text Summarization: Identifying key phrases and sentences to create concise summaries.
Question Answering: Pinpointing relevant information in a document to answer queries.
Sentiment Analysis: Understanding the emotional tone of text.
Text Generation: Creating coherent and contextually relevant text.
Read More about how transformer modeling is impacting NLP
Computer Vision (CV)
Image Recognition: Transformers with Multi-Head Attention (e.g., Vision Transformers) are now competitive with or even outperform CNNs in tasks like image classification.
Object Detection: Locating and classifying objects within images.
Image Segmentation: Dividing an image into meaningful regions.
Speech Recognition: Transcribing spoken language into text.
Drug Discovery and Protein Folding: Analyzing sequences of molecules or amino acids.
Conclusion
Multi-Head Attention stands as a testament to the ingenious design of the Transformer architecture. By allowing models to “look” at different parts of an input sequence from multiple perspectives simultaneously, it vastly improves their ability to capture complex and diverse relationships.
This mechanism is not just a technical detail; it’s a fundamental breakthrough that underpins the unprecedented success of modern AI in understanding and generating human-like data. As we continue to push the boundaries of AI, the principles of attention, especially multi-head attention, will undoubtedly remain a cornerstone of innovation.
Frequently Asked Questions
What is the primary purpose of Multi-Head Attention?
The primary purpose of Multi-Head Attention is to allow Transformer models to capture diverse types of relationships and dependencies within an input sequence simultaneously. By using multiple “attention heads,” the model can focus on different aspects of the data, leading to a richer and more comprehensive understanding than a single attention mechanism.
How does Multi-Head Attention differ from simple Self-Attention?
While self-attention calculates a single set of attention weights, Multi-Head Attention performs this calculation multiple times in parallel, each with different learned linear projections of the input. Each “head” learns to focus on different parts or relationships in the sequence, and their outputs are combined for a more holistic view.
Why is the “scaling factor” dkdk used in the Multi-Head Attention formula?
The scaling factor dkdk (where dkdk is the dimension of the key vectors) is used to prevent the dot products of Query and Key vectors from becoming too large, especially with high-dimensional vectors. Large dot products can push the softmax function into regions with very small gradients, hindering learning. Scaling helps stabilize the training process.
Authors
-

Written by:
Neha SinghReviewed by: