Summary: The transformer model is a revolutionary deep learning architecture that leverages self-attention to process sequential data efficiently. Widely used in NLP and generative AI, transformers enable advanced applications like ChatGPT and BERT. Their scalability, parallel processing, and adaptability make them foundational to modern artificial intelligence across multiple domains.
Introduction – What Is a Transformer Model?
The transformer model has become the gold standard in deep learning for handling sequential data, especially in natural language processing (NLP). First introduced by Vaswani et al. in 2014, the transformer model broke away from the limitations of previous architectures like RNNs and CNNs by relying entirely on a self-attention mechanism.
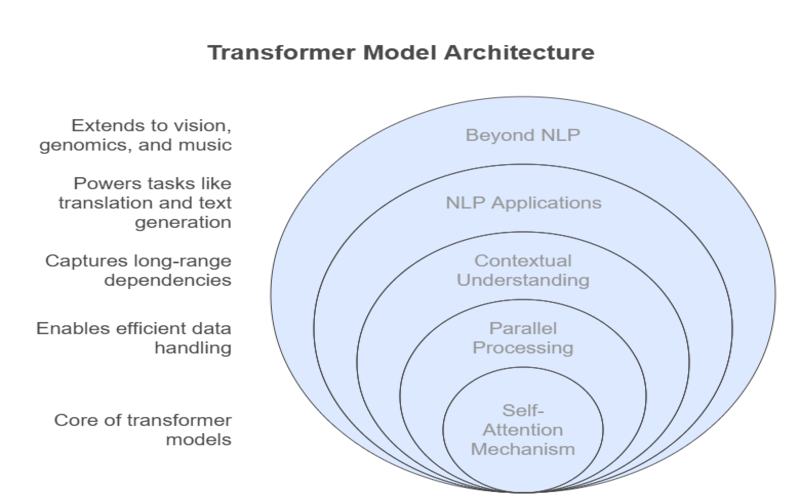
This innovation enables the transformer model to process entire sequences in parallel, capturing long-range dependencies and contextual relationships with unprecedented efficiency.
A transformer model is a type of neural network architecture that learns context and meaning by tracking relationships in sequential data, such as words in a sentence or tokens in a code snippet.
For example, in language translation, a transformer model can take an English sentence as input and generate its Spanish equivalent, understanding the context of each word regardless of its position in the sequence. Today, transformer models power advanced applications like ChatGPT, BERT, and Google Translate, and are increasingly used in fields beyond NLP, including computer vision, genomics, and even music generation.
Key Takeaways
- Transformer models excel at capturing long-range dependencies in sequential data.
- Their self-attention mechanism enables parallel processing and improved efficiency.
- Transformers drive state-of-the-art results in NLP and generative AI.
- Architecture variants like BERT and GPT address diverse AI challenges.
- Despite strengths, transformers require significant computational resources and large datasets.
Key Components of a Transformer Model
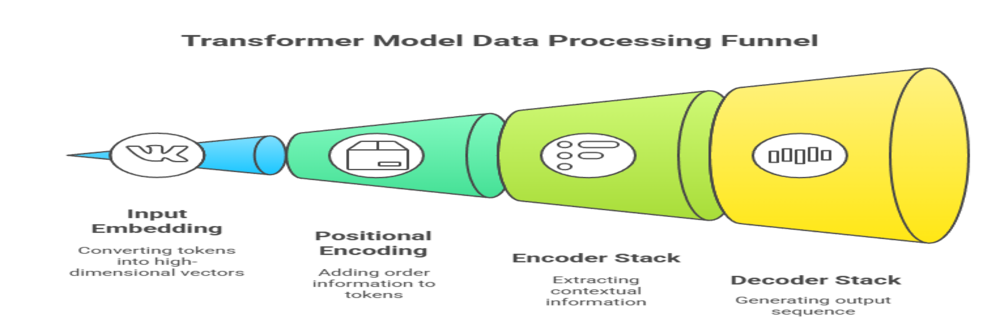
The transformer model’s architecture is both elegant and powerful, consisting of several key components that work together to process and generate sequential data:
- Input Embedding: Converts input tokens (words, subwords, or characters) into high-dimensional vectors that the model can process.
- Positional Encoding: Adds information about the order of tokens, since the model itself doesn’t inherently understand sequence order.
- Encoder Stack: A series of identical layers that process the input embeddings and extract contextual information using self-attention and feedforward neural networks.
- Decoder Stack: Another series of identical layers that generate the output sequence, attending to both previous outputs and the encoder’s representations.
- Self-Attention Mechanism: The core innovation, allowing each token to focus on other relevant tokens in the sequence, regardless of their distance.
- Feedforward Networks: Applied to each position separately, further transforming the data after self-attention.
- Layer Normalization and Residual Connections: Ensure stable training and help the model learn more effectively.
How the Transformer Model Works
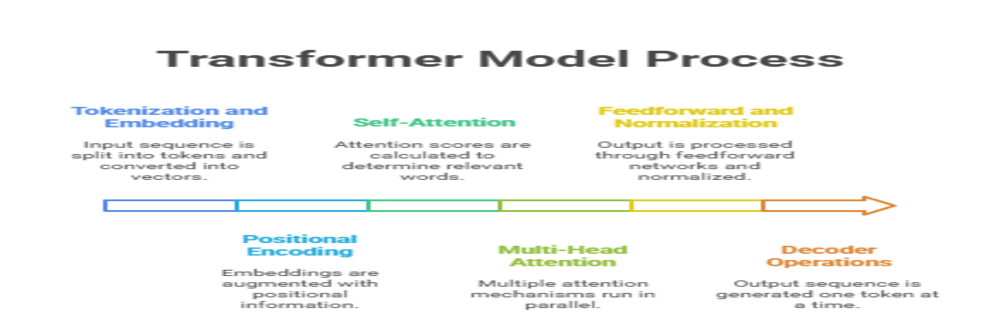
The transformer model operates through an encoder-decoder structure, but its most revolutionary aspect is the attention mechanism, particularly self-attention
- Tokenization and Embedding: The input sequence is split into tokens and converted into vectors (embeddings).
- Positional Encoding: These embeddings augmented with positional information to retain the order of the sequence.
- Self-Attention: For each token, the model calculates attention scores with every other token, determining which words are most relevant for understanding context. This is achieved using query, key, and value vectors derived from the embeddings.
- Multi-Head Attention: Multiple attention mechanisms run in parallel, allowing the model to capture different types of relationships simultaneously.
- Feedforward and Normalization: The output from attention layers is passed through feedforward networks and normalized, with residual connections added to facilitate learning.
- Decoder Operations: In tasks like translation, the decoder stack generates the output sequence one token at a time, attending to both the encoder’s output and previously generated tokens.
This architecture enables the transformer model to process sequences in parallel, dramatically speeding up training and inference compared to sequential models like RNNs.
Applications of Transformer Models
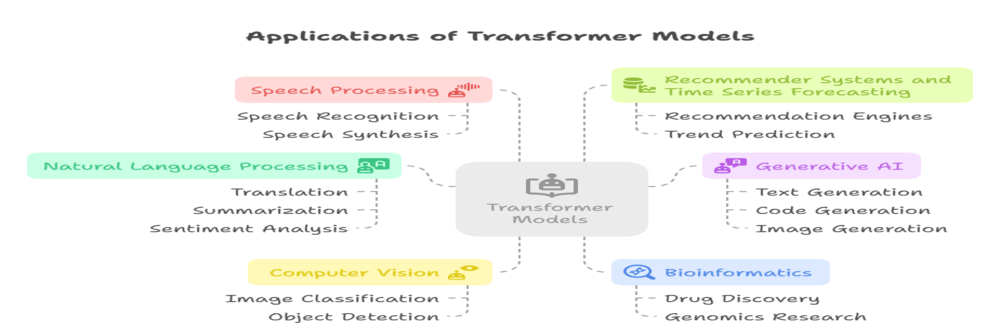
The transformer model’s versatility has led to its adoption in a wide range of applications:
- Natural Language Processing (NLP): Tasks like translation, summarization, question answering, and sentiment analysis dominated by transformer models such as BERT, GPT, and T5.
- Generative AI: Transformer models are the backbone of generative AI systems, including large language models like ChatGPT and DALL-E, capable of generating text, code, and even images.
- Computer Vision: Vision Transformers (ViT) adapt the transformer model for image classification and object detection.
- Bioinformatics: Transformers analyze DNA and protein sequences, aiding in drug discovery and genomics research.
- Speech Processing: Used for speech recognition, synthesis, and translation.
- Recommender Systems and Time Series Forecasting: Transformers are increasingly use for recommendation engines and predicting trends in sequential data.
Transformer-Based Architectures and Variants
The original transformer model has inspired a host of variants and specialized architectures, often referred to as the “Transformer Model Kit”:
- BERT (Bidirectional Encoder Representations from Transformers): Excels at understanding context in both directions for tasks like question answering and sentiment analysis.
- GPT (Generative Pre-trained Transformer): Focuses on text generation and completion, using only the decoder portion of the transformer model.
- T5 (Text-to-Text Transfer Transformer): Treats every NLP task as a text-to-text problem.
- Vision Transformer (ViT): Applies transformer principles to images for classification and detection.
- Longformer, Reformer, and others: Designed for handling longer sequences or improving efficiency.
Each transformer model example demonstrates the architecture’s adaptability to different data types and problem domains.
Advantages of the Transformer Model
The transformer model has fundamentally changed the landscape of deep learning and artificial intelligence. Here’s an in-depth look at its most significant advantages:
Parallelization
Traditional sequence models like RNNs and LSTMs process data one step at a time, making training and inference slow, especially with long sequences. The transformer model, in contrast, processes entire input sequences simultaneously. This parallelization made possible by the self-attention mechanism, which does not depend on previous computations to process the next token.
Long-Range Context
One of the most groundbreaking features of the transformer model is its ability to capture relationships between distant elements in a sequence. The self-attention mechanism allows every token to “attend” to every other token, regardless of their position.
Scalability
The transformer model architecture is highly modular, making it easy to scale up by simply adding more layers or increasing the size of each layer. This scalability has enabled the creation of today’s most powerful AI models, such as GPT-4 and BERT, which contain billions of parameters.
Versatility
While transformers were originally designed for NLP, their architecture has proven adaptable to a wide range of domains and data types.
Limitations and Challenges
Despite their transformative impact on deep learning and natural language processing, transformer models face several significant limitations and challenges that affect their scalability, accessibility, and reliability.
Computational Cost and Resource Demands
Transformer models, especially large-scale ones like GPT-3, require immense computational resources for both training and inference. Training such models can cost millions of dollars and consume vast amounts of energy, making them accessible primarily to well-funded organizations and tech giants.
Data Hunger
To achieve high performance and generalization, transformer models need training on massive datasets. This data hunger poses challenges for domains where large, high-quality datasets are not readily available. The need for extensive data also increases the risk of inheriting biases present in the training data, which can affect model fairness and reliability.
Interpretability and Explainability
The complexity of the self-attention mechanism and the sheer number of parameters make transformer models difficult to interpret. Understanding why a model made a particular decision or tracing the influence of specific input tokens is challenging, which can hinder trust and transparency in critical applications like healthcare, finance, or law
The Future of Transformers in AI
The transformer model has fundamentally reshaped the field of artificial intelligence. Research continues to push the boundaries, with innovations focused on making transformers more efficient, interpretable, and adaptable to new domains. As the “Transformer Model Kit” expands, expect to see even more powerful models driving advances in language, vision, science, and beyond.
Frequently Asked Questions
What is a Transformer Model?
A transformer model is a neural network architecture that uses self-attention to process sequential data, excelling at tasks like language translation and text generation.
What is The Transformer Model in Generative AI?
In generative AI, transformer models power systems like ChatGPT, generating human-like text, code, and even images by learning context and relationships in data.
What is a Transformer Model in NLP?
In NLP, the transformer model is used for tasks such as translation, summarization, and question answering, outperforming previous models thanks to its self-attention mechanism.
Is ChatGPT a Transformer Model?
Yes, ChatGPT is built on the transformer model architecture, specifically the decoder-based GPT variant, enabling it to generate coherent and contextually relevant text
Authors
-

Written by:
Versha RawatReviewed by: