Summary: Data partitioning is the process of splitting large datasets into smaller, independent partitions to optimize performance, scalability, and data management. It enables faster queries, efficient resource utilization, and improved availability by distributing data across multiple nodes or storage. Partitioning is essential for modern data engineering, analytics, and regulatory compliance.
Introduction to Data Partitioning
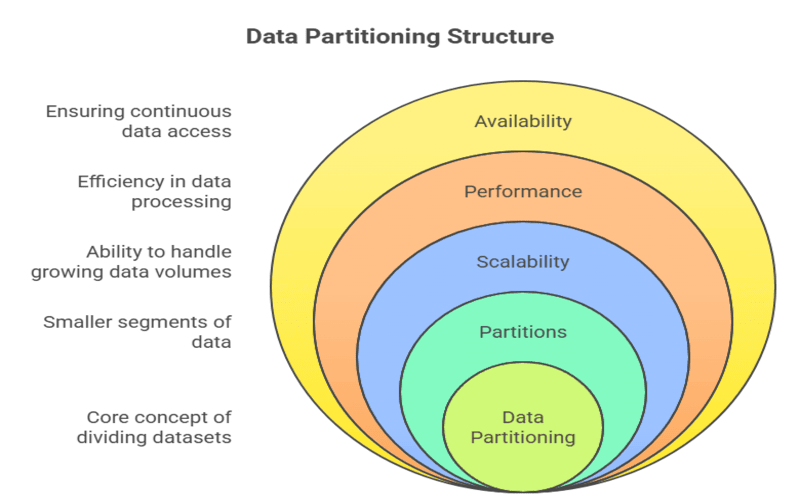
Data partitioning is a foundational concept in data engineering, enabling organizations to manage, process, and analyze massive datasets efficiently. At its core, data partitioning involves dividing large datasets into smaller, more manageable segments called partitions.
Each partition contains a subset of the overall data, which can be stored, queried, and managed independently, yet still logically belongs to the same dataset.
With the explosion of big data and the adoption of distributed systems, data partitioning has become essential for ensuring scalability, optimizing performance, and maintaining high availability.
Whether you are working with traditional relational databases, modern NoSQL systems, or advanced machine learning pipelines, understanding data partitioning is crucial for building robust and efficient data architectures.
Key Takeaways
- Data partitioning improves query speed by reducing data scanned per request.
- It enables horizontal scalability by distributing data across multiple servers or nodes.
- Partitioning increases system availability and isolates failures to specific partitions.
- Data management tasks like backup and archiving are simplified with partitions.
- Proper partitioning supports compliance and security for sensitive or regional data
Types of Data Partitioning

Data partitioning isn’t a one-size-fits-all solution. There are several techniques, each suited to different use cases and data access patterns. The main types include:
Horizontal Partitioning
Also known as sharding, horizontal partitioning involves splitting a table’s rows into multiple partitions, each containing a subset of the records. For example, a customer table might be horizontally partitioned by region, so each partition holds customers from a specific area.
Vertical Partitioning
Vertical partitioning divides a table’s columns into separate partitions. Frequently accessed columns can be stored in one partition, while less-used columns are stored elsewhere. This is useful when certain columns are queried more often than others, optimizing storage and access speed.
Range Partitioning
Data is divided based on a range of values in a specific column. For instance, sales data might be partitioned by date, with each partition representing a month or year. This makes time-based queries highly efficient.
Hash Partitioning
A hash function is applied to a column’s value (such as user ID), and the output determines the partition. This approach helps distribute data evenly and avoid hot spots, especially in distributed systems.
List Partitioning
Data is assigned to partitions based on a predefined list of values. For example, orders might be partitioned by product category, with each category mapped to a specific partition.
Composite Partitioning
Combines two or more partitioning methods, such as range-hash or range-list, to handle complex data distribution requirements.
Use Cases of Data Partitioning
Data partitioning is widely adopted across industries and data systems to address scalability, performance, and compliance needs. Here are some of the most common and impactful use cases:
E-commerce and Retail Analytics
Large e-commerce platforms often partition sales or invoice data by year or month, enabling faster queries for recent transactions and efficient historical analysis. For example, a sales table with millions of rows can be partitioned by the “sale_year” column, so queries for a specific year only scan relevant partitions, greatly improving performance.
Geographical and Regulatory Compliance
Organizations may partition customer data by region or country using list partitioning. This approach supports compliance with data residency laws and local regulations, such as GDPR, by ensuring that data remains within specific geographic boundaries.
Example: A retailer partitions customer data by region and then applies hash partitioning on customer_id within each region to balance load and meet compliance requirements.
Time-Series and IoT Data
Time-series databases and IoT platforms commonly use range partitioning by timestamp or date. This allows for efficient storage, retrieval, and archiving of massive volumes of sensor or event data, supporting both real-time analytics and historical reporting.
Example: IoT readings are partitioned by day and then hashed by device_id, supporting time-window queries and distributing data spikes
Benefits of Data Partitioning

Data partitioning delivers a range of advantages that are crucial for managing and scaling modern data systems. Here are the key benefits, supported by industry best practices and expert guidance:
Improved Scalability
Partitioning allows data to be split across multiple servers or storage units. This enables systems to scale horizontally, handling growing data volumes without hitting hardware limits. As data grows, new partitions can be added, ensuring continued performance and availability.
Optimized Performance
By dividing data into partitions, queries and operations can target only the relevant subset of data rather than scanning entire tables or datasets. This reduces I/O operations and significantly improves query response times, especially for large-scale data analytics and real-time reporting.
Enhanced Data Availability
Partitioning helps isolate failures. If one partition becomes unavailable due to hardware or network issues, the rest of the data remains accessible. This reduces the risk of total system downtime and improves overall data availability.
Easier Data Management
Smaller, more manageable partitions simplify routine maintenance tasks such as backups, restores, and index rebuilds. Administrators can operate on individual partitions without affecting the entire dataset, reducing downtime and operational complexity.
Increased Concurrency
Partitioned data allows for parallel processing and concurrent queries. Different users or applications can access separate partitions simultaneously, reducing contention and improving throughput in multi-user environments.
Operational Flexibility and Cost Optimization
Partitioning enables organizations to apply different storage, security, and management policies to different data segments. For example, frequently accessed or sensitive data can be placed on high-performance or secure storage, while archival data can be moved to cost-effective storage solutions.
Challenges and Considerations
Data partitioning is a powerful technique for managing large datasets, but it introduces several challenges and important considerations that must be addressed for effective implementation.
Partition Skew (Uneven Data Distribution)
One of the most significant challenges is partition skew, where data is unevenly distributed across partitions. This can lead to some partitions becoming overloaded (hotspots) while others remain underutilized, causing performance bottlenecks and increased latency.
Skew often arises when partition keys are not chosen carefully, such as when certain values dominate (e.g., users from a major city in a social app).
Resource Contention
As partitions grow and interact, multiple processes may compete for the same resources, such as CPU, memory, or network bandwidth. This contention can reduce overall system efficiency and cause significant slowdowns, especially in distributed systems with high concurrency.
Maintenance Overhead
Partitioned systems require ongoing maintenance, including monitoring, rebalancing, and optimizing partition boundaries as data evolves. Maintenance tasks such as migrating data, ensuring consistency, managing schema changes, and handling backups become more complex and resource-intensive.
Complexity in System Design
Partitioning adds architectural complexity. Designing, implementing, and maintaining partitioned systems requires careful planning, a deep understanding of data access patterns, and sometimes custom tooling.
Modifying data access logic, migrating existing data, and ensuring uninterrupted service during changes can be challenging.
Consistency and Data Integrity
Ensuring data consistency across partitions, especially in distributed environments, is complex. Replicating data for high availability can introduce synchronization delays, leading to temporary inconsistencies between partitions.
Regular validation needs to prevent overlaps or gaps in partition ranges, which could compromise data integrity.
Query Performance and Optimization
Queries that span multiple partitions may incur higher latency and require more complex logic, potentially negating the benefits of partitioning if not managed properly. Unoptimized queries that do not leverage partition elimination can result in full table scans and degraded performance.
Data Partitioning in DBMS
In database management systems, data partitioning used to split large tables into smaller partitions, each stored and accessed separately. This can dramatically improve query speed and simplify maintenance tasks like backups and archiving.
For example, in SQL databases, you can create partitions using commands like:

This example demonstrates range partitioning in SQL, where sales data is partitioned by year.
Data Partitioning in Machine Learning
In machine learning, data partitioning typically refers to splitting a dataset into training, validation, and test sets. This ensures that models trained and evaluated on different subsets, reducing the risk of overfitting and providing a more accurate assessment of model performance.
Data Partitioning in SQL
SQL databases support various partitioning techniques, such as range, hash, and list partitioning. These features enable efficient data management and query optimization, especially for very large tables.
Data Partitioning Techniques
Some of the most common data partitioning techniques include:
- Horizontal Partitioning (Sharding): Splitting rows across partitions.
- Vertical Partitioning: Splitting columns across partitions.
- Range Partitioning: Dividing data based on value ranges.
- Hash Partitioning: Using a hash function to distribute data.
- List Partitioning: Assigning data based on a list of values.
- Composite Partitioning: Combining multiple techniques for complex scenarios.
Data Partitioning Examples
- E-commerce: Orders table partitioned by order date for faster historical queries.
- Banking: Customer data partitioned by region to comply with data residency regulations.
- Healthcare: Patient records partitioned by department or treatment type for improved access control and performance.
Conclusion
Data partitioning is a powerful technique in data engineering, enabling organizations to handle massive datasets with greater efficiency, scalability, and resilience. By understanding the different types of data partitioning, their use cases, benefits, and challenges, you can design data architectures that are robust, high-performing, and future-proof.
Whether you’re optimizing a database, building a machine learning pipeline, or architecting a big data platform, mastering data partitioning is essential for success in today’s data-driven world.
Frequently Asked Questions
What Is Partitioning and Types?
Partitioning is the process of dividing a large dataset or database table into smaller, independent segments called partitions. The main types include horizontal partitioning (sharding), vertical partitioning, range partitioning, hash partitioning, list partitioning, and composite partitioning.
What Is an Example of Partitioning?
A common example is partitioning a sales table by year using range partitioning, so each year’s data is stored in a separate partition. This makes time-based queries much faster and simplifies data management.
What is Partitioning in ETL?
In ETL (Extract, Transform, Load) processes, partitioning refers to dividing data into segments that can be processed in parallel. This accelerates data loading and transformation by allowing multiple ETL jobs to run simultaneously on different partitions.
What Is Database Partitioning In SQL?
Database partitioning in SQL involves splitting large tables into smaller partitions using techniques like range, hash, or list partitioning. This improves query performance, simplifies maintenance, and enhances scalability in SQL databases.
Authors
-

Written by:
Versha RawatReviewed by: