Summary: Model parameters are the internal variables learned from data that define how machine learning models make predictions. Distinct from hyperparameters, they are optimized during training to capture data patterns. Proper initialization and optimization of parameters are crucial for model accuracy, generalization, and efficient learning in AI applications.
Introduction – Understanding Model Parameters
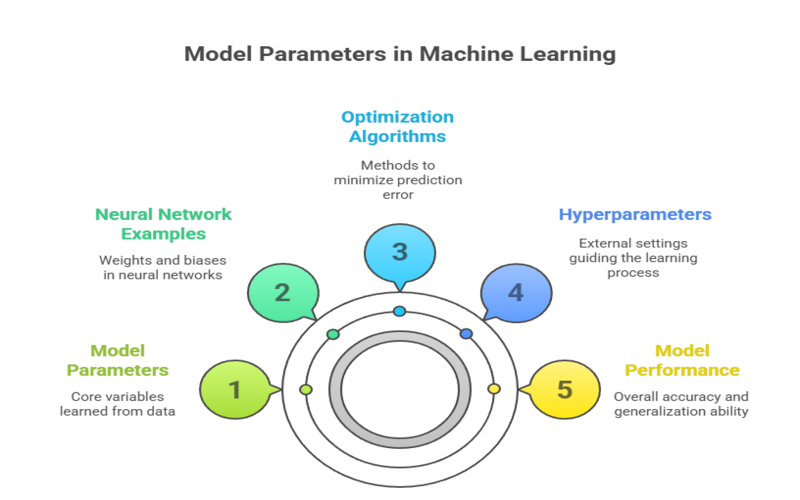
In machine learning, model parameters are the internal variables of a model that are learned from data during the training process. These parameters control how the model processes input data and generates predictions or outputs. Essentially, they define the model’s behavior and its ability to map inputs to accurate results.
For example, in a neural network, parameters include weights and biases that adjust how signals flow through the network layers to produce an output. The values of these parameters are optimized iteratively to minimize prediction error, allowing the model to capture complex patterns in data.
Model parameters are distinct from hyperparameters, which are set externally before training and guide the learning process itself. Understanding model parameters is crucial because they directly influence the model’s performance and generalization ability on unseen data.
Key Takeaways
- Model parameters are learned variables that directly influence prediction accuracy.
- Hyperparameters control the training process and are set before learning begins.
- Proper parameter initialization prevents issues like vanishing or exploding gradients.
- Optimization algorithms like Adam and SGD iteratively update parameters during training.
- Effective parameter management is essential for building robust, generalizable machine learning models.
Examples of Model Parameters in Common Algorithms
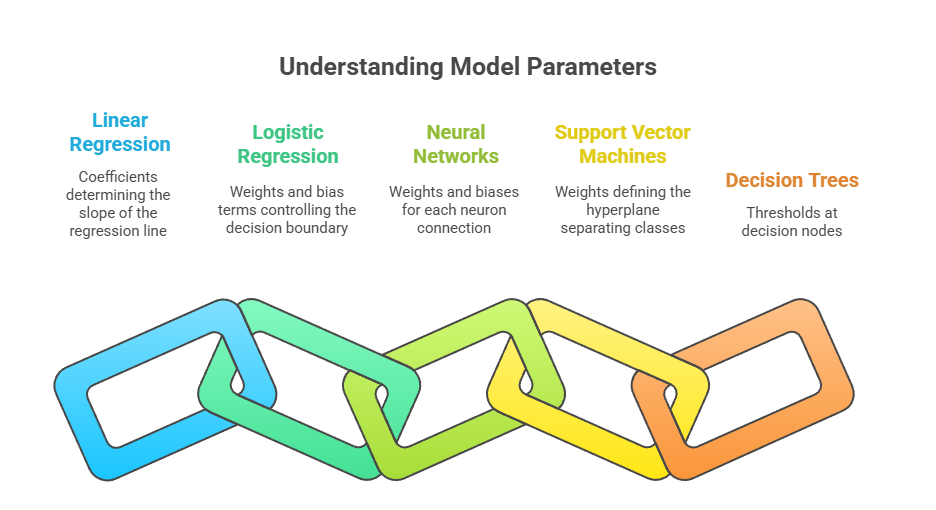
Model parameters are the internal variables that a machine learning model learns from data to make predictions. These parameters differ depending on the type of algorithm but fundamentally control how input data is transformed into outputs. Here are examples of model parameters in some common machine learning algorithms:
- Linear Regression: The coefficients (weights) assigned to each feature are parameters that determine the slope of the regression line.
- Logistic Regression: Similar to linear regression, the weights and bias terms are parameters that control the decision boundary.
- Neural Networks: Parameters include weights and biases for each neuron connection. These parameters determine how input features are transformed through layers to produce outputs.
- Support Vector Machines (SVMs): Parameters include the weights defining the hyperplane that separates classes.
- Decision Trees: Parameters can be the thresholds at decision nodes, though these are often considered part of the model structure rather than parameters learned by optimization.
In all these cases, the parameters are learned from the training data to minimize a loss function that measures prediction error.
How Model Parameters Are Learned
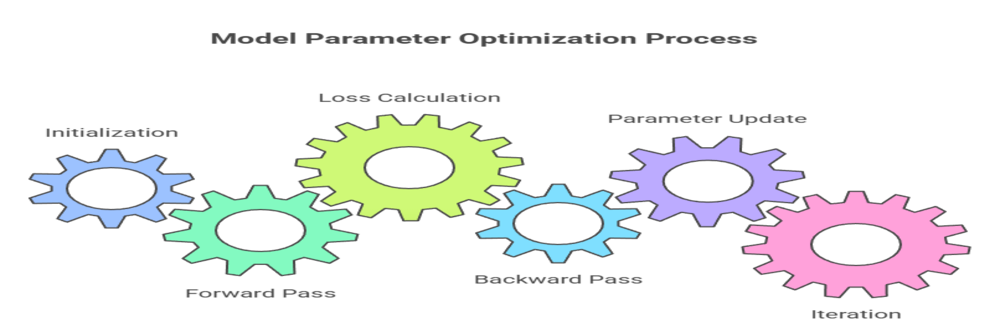
Model parameters are not set manually but are estimated automatically during training by optimization algorithms. This iterative optimization allows the model to find parameter values that best fit the training data, enabling it to generalize to new data. The training process involves:
- Initialization: Parameters are initialized, often randomly or using specific initialization methods (e.g., He or Xavier initialization for neural networks) to break symmetry and ensure effective learning.
- Forward Pass: The model processes input data using current parameter values to produce predictions.
- Loss Calculation: A loss or cost function quantifies the difference between predictions and true labels.
- Backward Pass (Gradient Computation): Using algorithms like gradient descent, the model computes gradients of the loss with respect to each parameter.
- Parameter Update: Parameters are updated in the direction that reduces the loss, typically by subtracting a fraction (learning rate) of the gradient.
- Iteration: Steps 2-5 are repeated over many epochs until convergence or satisfactory performance.
Parameters vs Hyperparameters – What’s the Difference?
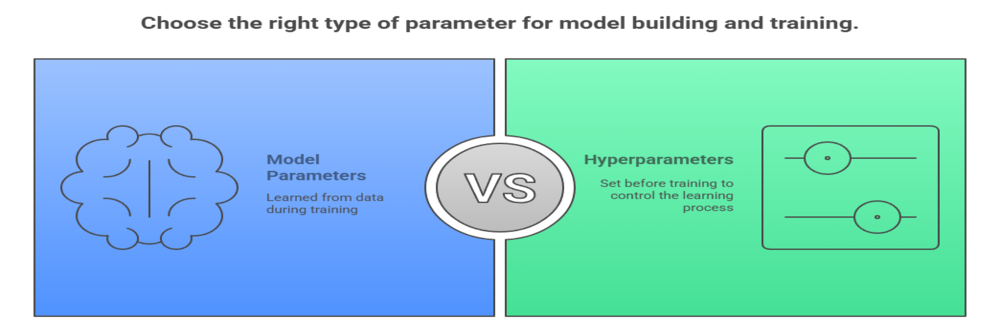
In machine learning, parameters and hyperparameters are two fundamental concepts that serve different roles in building and training models.
What Are Model Parameters?
- Model parameters are the internal variables of a model that are learned automatically from the training data during the learning process.
- Examples include weights and biases in neural networks, coefficients in linear regression, and support vectors in SVMs.
- These parameters define how the model transforms input data into predictions.
- They are not set manually by the practitioner but estimated through optimization algorithms like gradient descent.
- Once learned, parameters are saved as part of the trained model and are essential for making predictions.
What Are Hyperparameters?
- Hyperparameters are external configurations set manually before training begins.
- They control the learning process and the model architecture, such as the number of hidden layers in a neural network, learning rate, number of epochs, or kernel type in SVMs.
- Hyperparameters are not learn from data but are often tuned through trial, error or systematic search methods like grid search or random search to improve model performance.
- They influence how parameters are learned but are distinct from the parameters themselves
Importance of Model Parameters
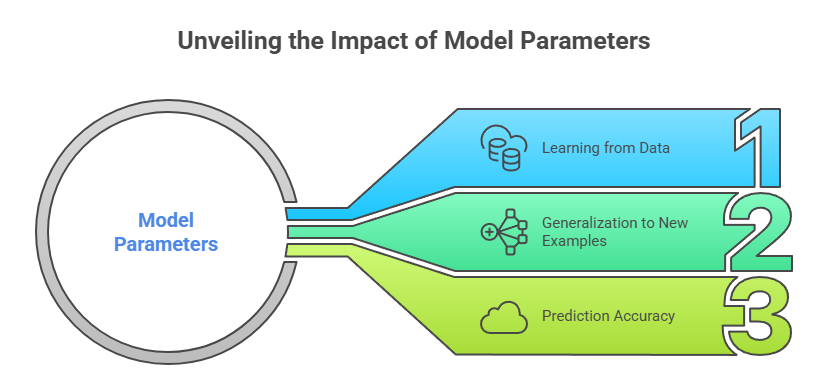
Model parameters are the internal configuration variables of a machine learning model that control how it processes input data and generates predictions. Their importance lies in the fact that they directly determine the model’s ability to learn from data, generalize to new examples, and produce accurate outputs.
Control of Data Processing
Parameters such as weights and biases decide how input features are combined and transformed within the model. For example, in neural networks, weights determine the strength of connections between neurons, emphasizing relevant features while suppressing less important ones. This selective emphasis enables the model to capture meaningful patterns in the data.
Prediction Accuracy
Properly learned parameters minimize the difference between the model’s predictions and actual outcomes by optimizing a loss function during training. This optimization ensures the model’s outputs reflect real-world relationships, improving its predictive power.
Generalization to Unseen Data
Parameters shape how the model reacts to new, unseen inputs after deployment. Well-tuned parameters allow the model to generalize beyond the training data rather than simply memorizing it. This balance is crucial to avoid overfitting, where a model fits the training data too closely but performs poorly on new data.
Impact on Model Complexity and Capacity
Model parameters play a crucial role in determining a machine learning model’s complexity and capacity, which directly affect its ability to learn from data and generalize to new examples.
Model Complexity
The number and nature of parameters determine a model’s capacity to learn complex patterns. Models with more parameters can represent more nuanced relationships in data, enabling them to tackle sophisticated tasks. However, an excessive number of parameters can lead to overfitting and increased computational demands.
Overfitting Risk
Larger models with many parameters are prone to overfitting, where they capture noise or specific details of the training data rather than general patterns. Techniques such as regularization, dropout, and cross-validation are used to mitigate this risk by controlling parameter values during training.
Practical Considerations
When working with model parameters in machine learning, several practical factors influence successful model development and deployment:
Computational Resources
Models with many parameters require more memory and processing power to train and deploy. For instance, state-of-the-art generative AI models like ChatGPT have billions of parameters, demanding significant computational resources and energy.
Optimization Process
Parameters are adjusted iteratively through training algorithms like gradient descent, involving forward and backward propagation steps. Proper initialization and optimization of parameters are essential for efficient and effective learning.
Without well-learned parameters, even the best model architecture cannot perform well. Thus, parameter optimization is central to model training and effectiveness.
Techniques for Parameter Initialization and Optimization
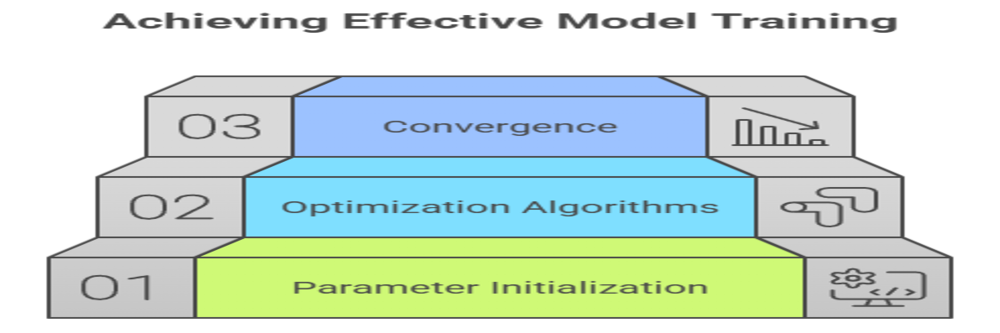
Effective training of machine learning models, especially deep neural networks, relies heavily on how model parameters are initialized and optimized. Proper initialization accelerates convergence and helps avoid problems like vanishing or exploding gradients, while optimization algorithms iteratively adjust parameters to minimize prediction error.
Parameter Initialization Techniques
Parameter initialization refers to setting the initial values of weights and biases before training begins. This step is crucial because poor initialization can prevent the model from learning effectively.
Zero Initialization
All weights are initialized to zero, and biases typically to zero as well.
- Drawbacks: Causes symmetry where all neurons learn the same features, preventing effective training. Therefore, zero initialization is generally not used for weights but can be used safely for biases.
- Use case: Rarely used for weights; biases can be zero-initialized.
Random Initialization
Weights are initialized with small random values, often drawn from a Gaussian (normal) distribution scaled by a small factor (e.g., 0.01). Biases are usually set to zero.
- Advantages: Breaks symmetry so that different neurons learn different features.
- Challenges: If values are too large or too small, gradients may vanish or explode, especially in deep networks.
Xavier/Glorot Initialization
Suitable for sigmoid or tanh activations, weights initialized to keep the variance of activations uniform across layers. The scaling factor is based on the average of the number of input and output neurons.
- Advantages: Balances variance to avoid gradient issues in networks with bounded activations.
Orthogonal Initialization
Weight matrices are initialized as semi-orthogonal matrices, which can help maintain stable gradients in deep linear networks.
- Use case: Useful in recurrent neural networks and deep architectures.
Parameter Optimization Techniques
Once parameters are initialized, optimization algorithms iteratively update them to minimize a loss function, improving the model’s predictions.
Gradient Descent
The fundamental algorithm that updates parameters by moving them in the direction opposite to the gradient of the loss function.
Stochastic Gradient Descent (SGD)
Uses mini-batches of data to compute gradients, balancing computational efficiency and convergence stability.
Adaptive Methods
- Adam: Combines momentum and adaptive learning rates, adjusting parameter updates based on first and second moments of gradients. Widely used for faster convergence.
- RMSProp, Adagrad: Other adaptive optimizers that adjust learning rates during training.
Challenges Related to Model Parameters
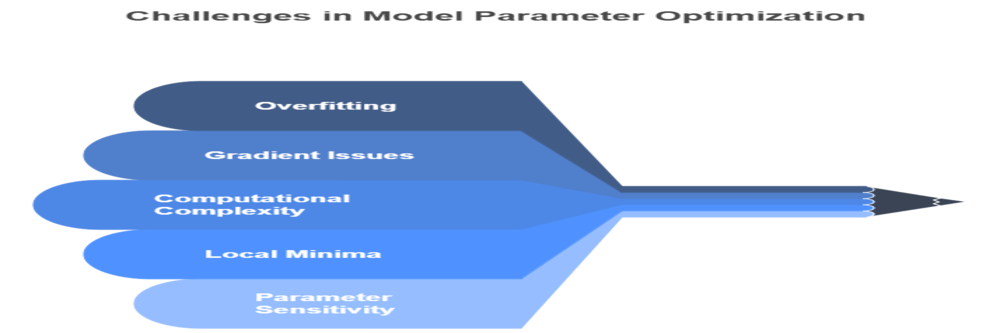
Optimizing model parameters involves several challenges. Addressing these challenges requires careful initialization, choice of optimization algorithm, regularization, and sometimes architectural adjustments.
- Overfitting: Parameters may fit training data too closely, failing to generalize.
- Vanishing/Exploding Gradients: Poor initialization or deep networks can cause gradients to vanish or explode, hindering learning.
- Computational Complexity: Large models with millions of parameters require significant computational resources and time to train.
- Local Minima and Saddle Points: Optimization algorithms may get stuck in suboptimal points.
- Parameter Sensitivity: Some parameters have a large impact on performance, requiring careful tuning.
Tools and Frameworks for Parameter Tracking
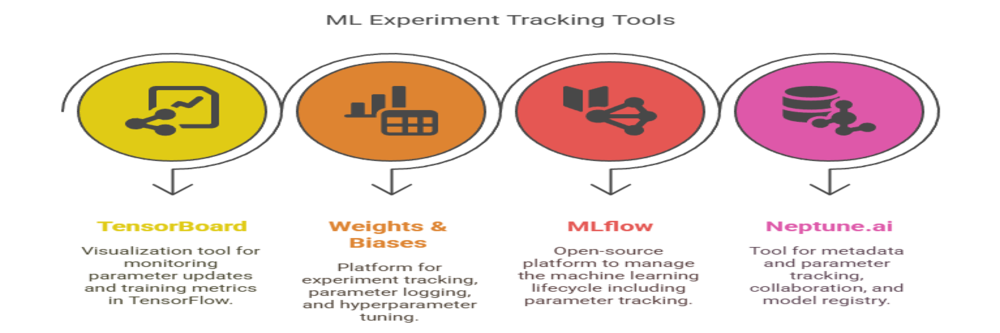
Tracking and managing model parameters during development and deployment facilitated by various tools. These tools help data scientists understand model behaviour, reproduce results, and optimize parameters effectively.
- TensorBoard: Visualization tool for monitoring parameter updates and training metrics in TensorFlow.
- Weights & Biases: Platform for experiment tracking, parameter logging, and hyperparameter tuning.
- MLflow: Open-source platform to manage the machine learning lifecycle including parameter tracking.
- Neptune.ai: Tool for metadata and parameter tracking, collaboration, and model registry.
Conclusion
Model parameters are the core components that enable machine learning models to learn from data and make accurate predictions. By adjusting these internal variables, models capture complex patterns and relationships within the input data.
Properly optimized parameters ensure that models generalize well to new, unseen data, balancing accuracy and robustness. Understanding and effectively managing model parameters is essential for building reliable and efficient AI systems that perform well across diverse real-world applications.
Frequently Asked Questions
What Is an Example of a Model Parameter?
An example is the weight assigned to a feature in a linear regression model or the weights and biases in a neural network layer. These parameters are learned during training to minimize prediction error.
What Is Modal Parameters?
This seems to be a typo or confusion with “model parameters.” Model parameters are the internal variables of a machine learning model learned from data that control its predictions.
What Are Model Parameters In AI?
In AI, model parameters are the internal configuration variables such as weights, biases, and scaling factors that a model learns from training data to capture patterns and make accurate predictions.
What Are Model Parameters and Hyperparameters?
Model parameters are learned internal variables adjusted during training, while hyperparameters are external settings defined before training that control the learning process and model structure. Parameters affect predictions directly; hyperparameters influence how parameters are learned.
Authors
-

Written by:
Neha SinghReviewed by: