Summary: Vision language models integrate computer vision and natural language processing to understand and generate text from images. Using vision and language encoders with fusion mechanisms, they enable applications such as image captioning, visual question answering, and retrieval. These models are transforming AI by bridging visual and textual data.
Introduction
Vision language models (VLMs) are a groundbreaking type of artificial intelligence that combines the power of computer vision and natural language processing (NLP) into a single system. These models can understand and generate meaningful text based on images or videos, bridging the gap between visual data and human language.
By simultaneously processing images and their textual descriptions, VLMs learn to associate visual elements with corresponding words, enabling applications like image captioning, visual question answering, and cross-modal retrieval. This fusion of visual understanding and natural language comprehension makes vision language models a key technology for multimodal AI.
Key Takeaways
- VLMs combine visual and textual data for multimodal AI tasks.
- Vision encoders extract features; language encoders process text context.
- Fusion mechanisms align and integrate image and text embeddings.
- Popular VLMs include GPT-4 Vision, CLIP, and LLaVA.
- VLMs enable applications like captioning, question answering, and content moderation.
How Vision Language Models Work
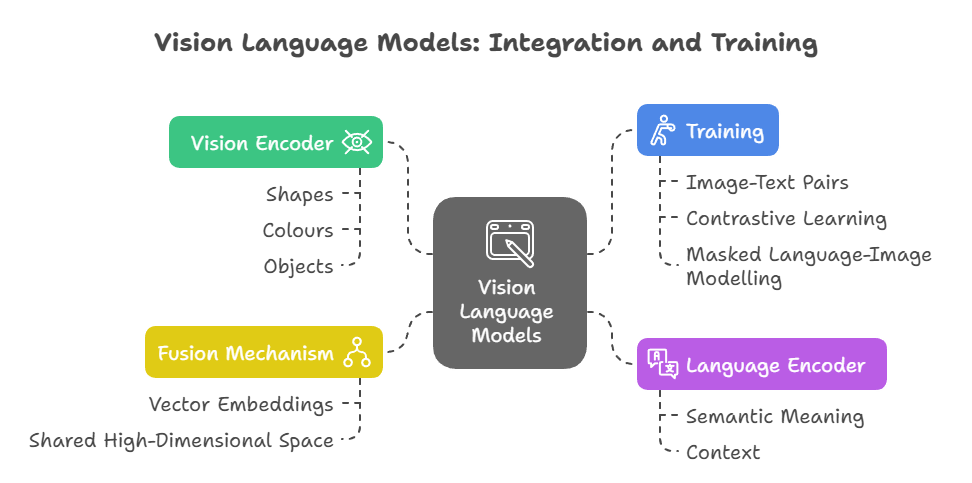
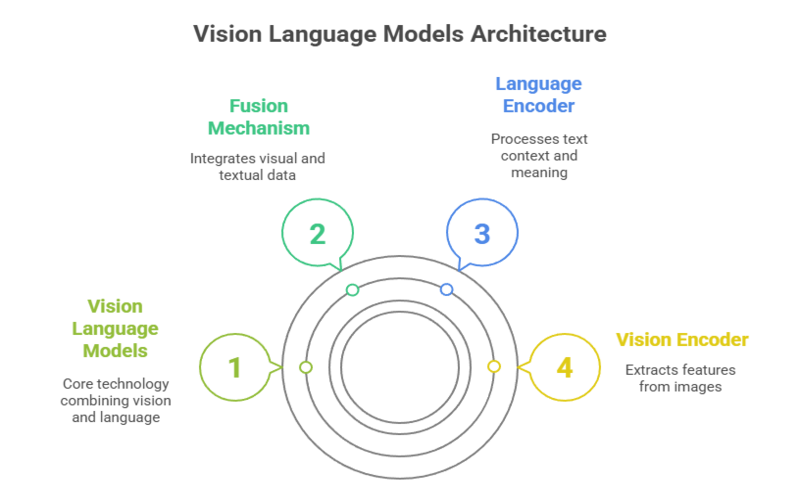
At their core, vision language models integrate two main components: a vision encoder and a language encoder. The vision encoder extracts meaningful features from images or videos, such as shapes, colours, and objects, often using advanced architectures like Vision Transformers (ViTs).
The language encoder processes text data, capturing semantic meaning and context through transformer-based models like BERT or GPT.
These two encoders convert their inputs into vector embeddings—numerical representations in a shared high-dimensional space. A fusion mechanism then aligns and combines these embeddings, allowing the model to understand the relationships between visual and textual data.
Training involves large datasets of image-text pairs, where the model learns to correlate images with their descriptions through techniques such as contrastive learning and masked language-image modelling.
Key Components of VLMs
Together, these components enable VLMs to perform tasks that require joint reasoning over images and text, making them versatile tools in AI.
Vision Encoder
This component processes images or videos to extract visual features. Modern VLMs often use Vision Transformers, which treat image patches like tokens in a language model, applying self-attention mechanisms to capture complex visual relationships.
Language Encoder
Utilizing transformer architectures, the language encoder converts text into embeddings that capture context and semantics. It enables the model to understand and generate natural language related to the visual input.
Fusion Mechanism
This is the strategy that combines the outputs of the vision and language encoders. Fusion can be single-stream (processing combined inputs together) or dual-stream (processing separately then aligning). This mechanism allows cross-modal interaction essential for multimodal understanding.
Popular Applications of Vision Language Models

Vision language models (VLMs) have become essential in bridging the gap between visual data and natural language, enabling a wide range of innovative applications across industries. Here are some of the most popular and impactful uses of VLMs today:
- Image Captioning: Generating descriptive text for images, useful for accessibility and content creation.
- Visual Question Answering (VQA): Answering questions about the content of an image, enhancing interactive AI systems.
- Image-Text Retrieval: Finding images based on textual queries or vice versa, improving search engines and databases.
- Content Moderation: Automatically detecting inappropriate or harmful content by understanding both visuals and text.
- Medical Imaging: Assisting diagnosis by interpreting medical images and related textual data.
- Robotics and Autonomous Systems: Enabling robots to understand instructions and environments through combined visual and language inputs.
These applications highlight the transformative potential of vision language models in making AI more intuitive and context-aware.
Notable Vision Language Models in Use Today
Several vision language models have gained prominence due to their advanced capabilities and open-source availability. These models exemplify the state-of-the-art in vision language modeling and serve as foundations for many downstream applications.
- OpenAI’s GPT-4 Vision: Extends the GPT-4 architecture to process images alongside text, enabling complex multimodal interactions.
- Google Gemini: Combines large language models with vision encoders for versatile AI applications.
- LLaVA (Large Language and Vision Assistant): An open-source model that integrates vision and language understanding for research and practical use.
- CLIP (Contrastive Language-Image Pretraining): Developed by OpenAI, CLIP learns to match images and text using contrastive learning, enabling zero-shot classification.
- BLIP (Bootstrapping Language-Image Pre-training): A model designed for image captioning and VQA with strong performance on multimodal benchmarks.
Challenges in Vision Language Modeling
Despite impressive progress, vision language models face several challenges. Addressing these challenges is crucial for advancing the reliability and ethical use of vision language models.
- Data Requirements: Training VLMs demands massive datasets with paired images and text, which can be costly and difficult to curate.
- Multimodal Alignment: Effectively fusing visual and textual information remains complex, especially when modalities have different structures and noise.
- Bias and Fairness: VLMs can inherit biases present in training data, leading to unfair or harmful outputs.
- Computational Resources: Large VLMs require significant computational power for training and deployment.
- Generalization: Ensuring models perform well across diverse domains and unseen data is an ongoing research focus.
Future of Vision Language Models
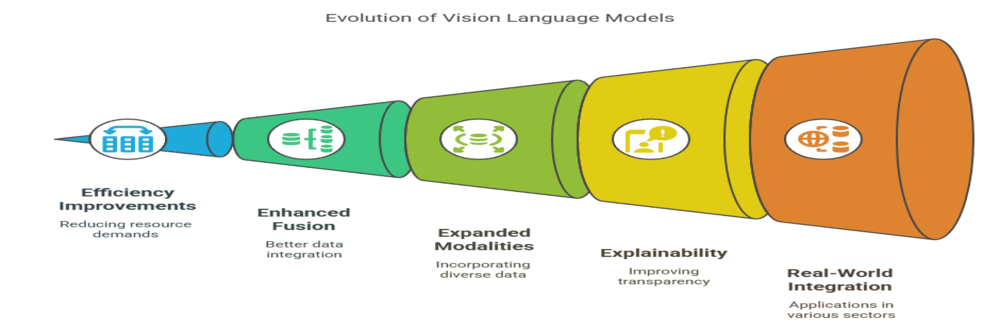
The future of vision language models looks promising, with ongoing research aimed at improving efficiency, accuracy, and ethical considerations. As vision language models evolve, they will continue to transform how AI systems perceive and interact with the world. Innovations include:
- Smaller, More Efficient Models: Techniques like parameter-efficient fine-tuning (PEFT) aim to reduce resource demands.
- Better Multimodal Fusion: New architectures will enhance how models integrate and reason over combined data.
- Expanded Modalities: Beyond images and text, future VLMs may incorporate audio, video, and sensor data for richer understanding.
- Explainability: Improving transparency to help users understand model decisions.
- Real-World Integration: More applications in healthcare, education, robotics, and creative industries.
Conclusion
Vision language models (VLMs) represent a significant breakthrough in artificial intelligence by seamlessly integrating visual perception with natural language understanding. These models enable machines to interpret and generate text based on images, bridging the gap between two traditionally separate modalities.
As VLMs continue to evolve, they promise to revolutionize applications across industries—from enhancing accessibility and content creation to improving human-computer interaction—unlocking new possibilities for smarter, more intuitive AI systems that understand the world as humans do
Frequently Asked Questions
What is VLM vs LLM?
Vision Language Models (VLMs) combine visual data processing with natural language understanding, while Large Language Models (LLMs) focus solely on text. VLMs handle images and text together, enabling multimodal tasks like image captioning, whereas LLMs generate or understand text without visual input.
Is ChatGPT a Vision Language Model?
Standard ChatGPT is primarily a Large Language Model focused on text. However, OpenAI’s GPT-4 Vision variant extends ChatGPT’s capabilities to process images alongside text, making it a vision language model capable of multimodal understanding.
What Are the Use Cases of Vision Language Models?
VLMs are used for image captioning, visual question answering, image-text retrieval, content moderation, medical imaging analysis, and enhancing robotics through combined visual and language understanding.
Authors
-

Written by:
Versha RawatReviewed by: