Summary: Skewness in statistics measures the asymmetry of data distributions, impacting analysis and decision-making. This blog explains types of skewness, calculation methods, interpretation, and its significance in various fields. Real-world examples and a comparison with kurtosis provide a comprehensive understanding, helping analysts make informed choices and improve data-driven strategies.
Introduction to Skewness
In the world of statistics, understanding the shape and spread of data is crucial for accurate analysis and interpretation. One of the most important aspects of a dataset’s shape is its skewness. Skewness in statistics refers to the degree of asymmetry observed in a probability distribution. While a perfectly symmetrical distribution is rare in real-world data, skewness helps us understand how data deviates from this ideal.
A distribution can be skewed to the left (negative skewness), skewed to the right (positive skewness), or perfectly symmetrical (zero skewness). Recognizing and measuring skewness is essential because many statistical methods assume normality (symmetry), and deviations can affect the validity of these methods.
Understanding skewness in statistics allows analysts, researchers, and decision-makers to:
- Identify outliers and anomalies
- Choose appropriate statistical models
- Interpret data more accurately
- Make informed business or policy decisions
In this comprehensive guide, we’ll explore the types of skewness in statistics, how to calculate it, its importance, and real-world examples, along with a comparison to kurtosis and answers to common questions.
Key Takeaways
- Skewness measures distribution asymmetry, impacting statistical analysis and modelling accuracy.
- Positive skewness has a long right tail; negative skewness, a long left tail.
- Skewness can be calculated using Pearson’s or moment-based formulas.
- High skewness often signals outliers or data requiring transformation.
- Understanding skewness aids in risk assessment and informed decision-making.
Types of Skewness
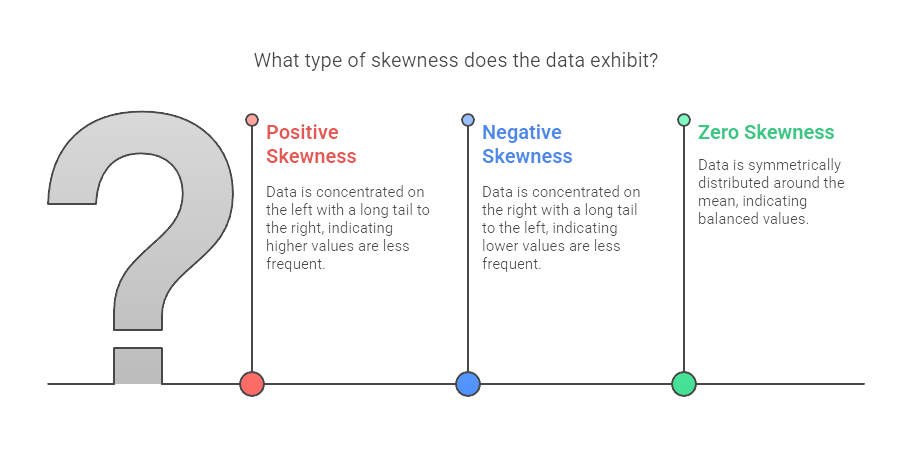
Skewness in statistics is generally classified into three main types, each with distinct characteristics and implications for Data Analysis.
Positive Skewness (Right-Skewed Distribution)
A distribution is said to be positively skewed or right-skewed when the tail on the right side is longer or fatter than the left side. In this case:
- The mean is greater than the median, which is greater than the mode (Mean > Median > Mode).
- Most data points are concentrated on the left, with a few large values stretching the distribution to the right.
Example
Income distribution is a classic example of positive skewness in statistics. Most people earn average or below-average incomes, but a small number of high earners pull the mean to the right, creating a long right tail.
Negative Skewness (Left-Skewed Distribution)
A negatively skewed or left-skewed distribution has a longer or fatter tail on the left side. Here:
- The mean is less than the median, which is less than the mode (Mean < Median < Mode).
- Most data points are concentrated on the right, with a few small values stretching the distribution to the left.
Example
Consider exam scores where most students perform well, but a few receive very low scores. These outliers create a long left tail, resulting in negative skewness.
Zero Skewness (Symmetrical Distribution)
A distribution with zero skewness is perfectly symmetrical. In such cases:
- The mean, median, and mode are all equal (Mean = Median = Mode).
- The left and right sides of the distribution are mirror images.
Example
The heights of adult men and women in a large population often approximate a symmetrical, normal distribution with zero skewness.
How to Calculate Skewness
Quantifying skewness in statistics involves mathematical formulas. The two most common approaches are Pearson’s coefficient and the standardized moment coefficient.
Pearson’s First Coefficient of Skewness
This is a straightforward formula, especially useful for quick assessments:
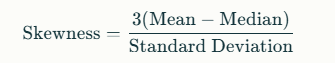
Alt text: Image showing Pearson’s First Coefficient of Skewness
- If the result is positive, the data is right-skewed.
- If it’s negative, the data is left-skewed.
- A value close to zero indicates symmetry.
Fisher’s Moment Coefficient of Skewness (Standardized)
For a more rigorous and widely accepted calculation, especially in statistical software, use the moment-based formula:

Where:
- EE denotes the expected value (mean)
- XX is a data point
- μμ is the mean of the distribution
- σσ is the standard deviation
This formula measures the third standardized moment of the distribution, providing a normalized value that allows comparison across different datasets.
Example Calculation
Suppose you have the following test scores:
45, 55, 61, 65, 70, 75, 90
- Mean = 67.3
- Median = 65
- Standard Deviation ≈ 15.3
Using Pearson’s formula
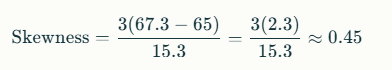
This indicates a slight positive skew.
Interpretation of Skewness Values
Interpreting skewness in statistics involves understanding what the calculated value means in practical terms:
- Skewness ≈ 0: The distribution is nearly symmetrical.
- Skewness > 0: The distribution is positively skewed (right tail longer).
- Skewness < 0: The distribution is negatively skewed (left tail longer).
Magnitude Interpretation
- Between -0.5 and 0.5: Approximately symmetric
- Between -1 and -0.5 or 0.5 and 1: Moderately skewed
- Less than -1 or greater than 1: Highly skewed
Important Note:
A high skewness value (positive or negative) suggests that the data may need transformation (e.g., logarithmic or square root) before applying statistical models that assume normality.
Why Skewness Matters in Data Analysis
Understanding why skewness matters in Data Analysis is crucial for accurate interpretation and effective decision-making. Skewness reveals data asymmetry, highlights potential outliers, and influences the choice of statistical methods.
Recognizing skewness ensures that analysts select appropriate models and draw reliable conclusions from their datasets, improving overall analytical outcomes.The importance of skewness in statistics cannot be overstated. Here’s why:
Model Selection and Accuracy
Many statistical techniques, such as linear regression, t-tests, and ANOVA, assume that the data is normally distributed. Skewed data can violate these assumptions, leading to inaccurate results or misleading conclusions. Recognizing skewness allows analysts to:
- Apply data transformations to reduce skewness
- Choose non-parametric methods that don’t assume normality
Risk Assessment and Decision Making
In finance, skewness is a critical risk measure. For instance:
- Negative skewness in investment returns signals a higher risk of extreme losses (left tail events).
- Positive skewness suggests a higher chance of extreme gains.
Understanding skewness helps investors and risk managers prepare for rare, impactful events.
Outlier Detection
Extreme skewness often indicates the presence of outliers or anomalies. Identifying these can:
- Improve data quality
- Reveal important trends or rare events
- Prevent skewed results in predictive modeling
Business and Policy Implications
In fields like healthcare, education, and marketing, skewness informs resource allocation, policy design, and customer segmentation. For example, knowing that healthcare costs are right-skewed helps insurers design better plans and set premiums appropriately.
Real-World Examples of Skewed Data
Real-world examples of skewed data include income distribution, where most earn moderate amounts but a few earn much more, and healthcare costs, where most expenses are low but some are extremely high, creating right-skewed distributions. Gestational age of births is a common example of left-skewed data. Let’s explore some skewness in statistics examples from various domains:
Income Distribution
Most people earn average or below-average incomes, but a few individuals earn extremely high salaries, bonuses, or inheritances. This creates a long right tail, resulting in positive skewness. Policymakers use this knowledge to design progressive tax systems and welfare programs.
Healthcare Costs
A majority of patients incur low to moderate healthcare expenses, but a small percentage require costly treatments (e.g., surgery, intensive care). This leads to a right-skewed distribution, influencing insurance premiums and healthcare funding.
Social Media Engagement
Most social media posts receive a modest number of likes or shares, but a few go viral, accumulating thousands or millions of engagements. The distribution of engagement per post is thus positively skewed.
Exam Scores
In some exams, most students perform well, but a few score very low. This creates a left-skewed (negative) distribution, which can prompt educators to review exam difficulty or support struggling students.
Real Estate Prices
In many cities, the majority of homes are priced within a certain range, but luxury properties can cost many times more, producing a right-skewed distribution. Real estate analysts use this information for market segmentation and pricing strategies.
Skewness vs Kurtosis
While skewness measures the asymmetry of a distribution, kurtosis describes the tailedness or the propensity for extreme values (outliers).
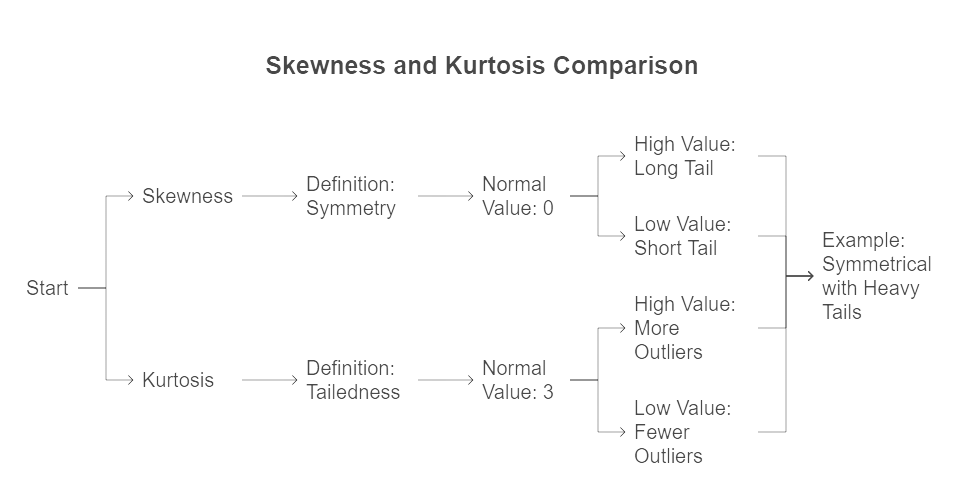
Example:
A distribution can be perfectly symmetrical (zero skewness) but have heavy tails (high kurtosis), indicating a higher probability of extreme values.
Conclusion
Skewness in statistics is a vital measure for understanding the shape and characteristics of data distributions. By identifying whether data is symmetrical, right-skewed, or left-skewed, analysts can make informed decisions, select appropriate models, and interpret results more accurately. Whether you’re working in finance, healthcare, education, or business, recognizing and addressing skewness ensures robust and reliable analysis.
Frequently Asked Questions
How Can Skewed Data be Corrected?
Skewed data can often be corrected using transformations such as logarithmic, square root, or Box-Cox transformations. These methods help normalize the distribution, making it more suitable for statistical analysis and modeling.
Does Zero Skewness Imply Normality?
No. Zero skewness only indicates symmetry. A distribution can be symmetric but not normal; for example, a uniform distribution is symmetric but not bell-shaped like a normal distribution.
Why is Skewness Important in Finance?
Skewness helps investors and analysts assess the risk of extreme returns. Negative skewness signals a higher likelihood of large losses, while positive skewness suggests the potential for large gains, influencing investment decisions and risk management strategies.
Authors
-

Written by:
Versha RawatReviewed by: