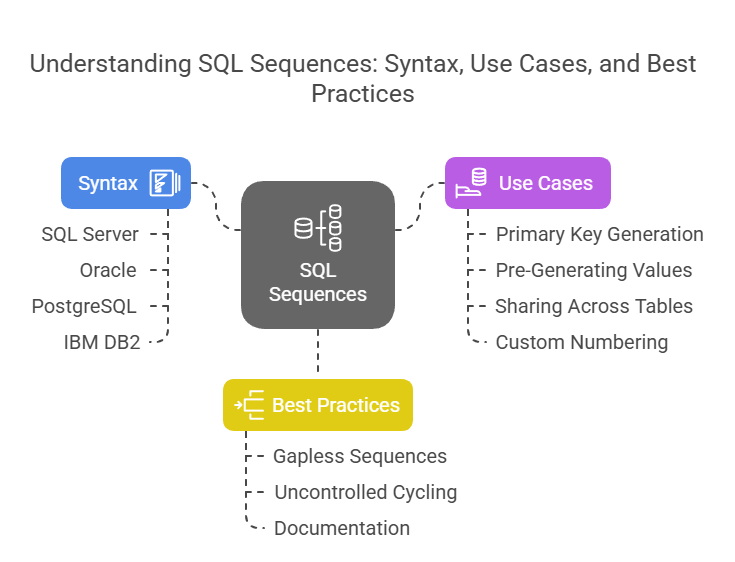
Summary: A sequence in SQL is a schema-bound object that generates unique numeric values, commonly used for primary keys or custom identifiers. Sequences offer flexibility, allowing values to be pre-generated, shared across tables, and customized for increments, cycling, and limits. They enhance data integrity and support advanced database design requirements.
Introduction
Sequences are powerful and flexible database objects used to generate unique numeric values, often for primary keys or other unique identifiers. Unlike auto-increment or identity columns, sequences are independent schema-level objects that can be shared across tables and customized for a variety of scenarios.
This article explores the syntax, use cases, and best practices for using sequences in SQL, with practical examples and guidance for different database systems.
Key Takeaways
- Sequences generate unique numbers, ideal for auto-incrementing primary keys.
- They are independent objects, usable across multiple tables and columns.
- Customizable for increment, start, min/max values, and cycling options.
- Sequence values can be pre-generated before inserting table rows.
- Not gapless-rollbacks and caching may introduce unused numbers
What is a Sequence in SQL?
A sequence in SQL is a database object that generates a series of unique numeric values, typically used to ensure each row in a table has a unique identifier.
Sequences are available in most major relational database management systems (RDBMS), including Oracle, SQL Server, PostgreSQL, and IBM DB2. MySQL, however, uses the AUTO_INCREMENT attribute instead of sequences for most use cases.
Key characteristics:
- Generates unique integers (ascending or descending)
- Not tied to a specific table or column
- Can be accessed and incremented manually
- Supports customization (start value, increment, min/max, cycling)
Syntax of Sequences in SQL
The syntax for creating and using sequences varies slightly between database systems, but the core concepts remain consistent.
General Syntax

- sequence_name: Name of the sequence object.
- START WITH: The initial value to start the sequence.
- INCREMENT BY: The value by which the sequence increases (or decreases).
- MINVALUE / MAXVALUE: The minimum and maximum values for the sequence.
- CYCLE / NOCYCLE: Whether the sequence restarts when it reaches its max/min value.
SQL Server Example

To get the next value:

Or use in an insert:

Oracle Example

To get the next value:

PostgreSQL Example

To use in a table:

IBM DB2 Example

Core Use Cases for Sequences
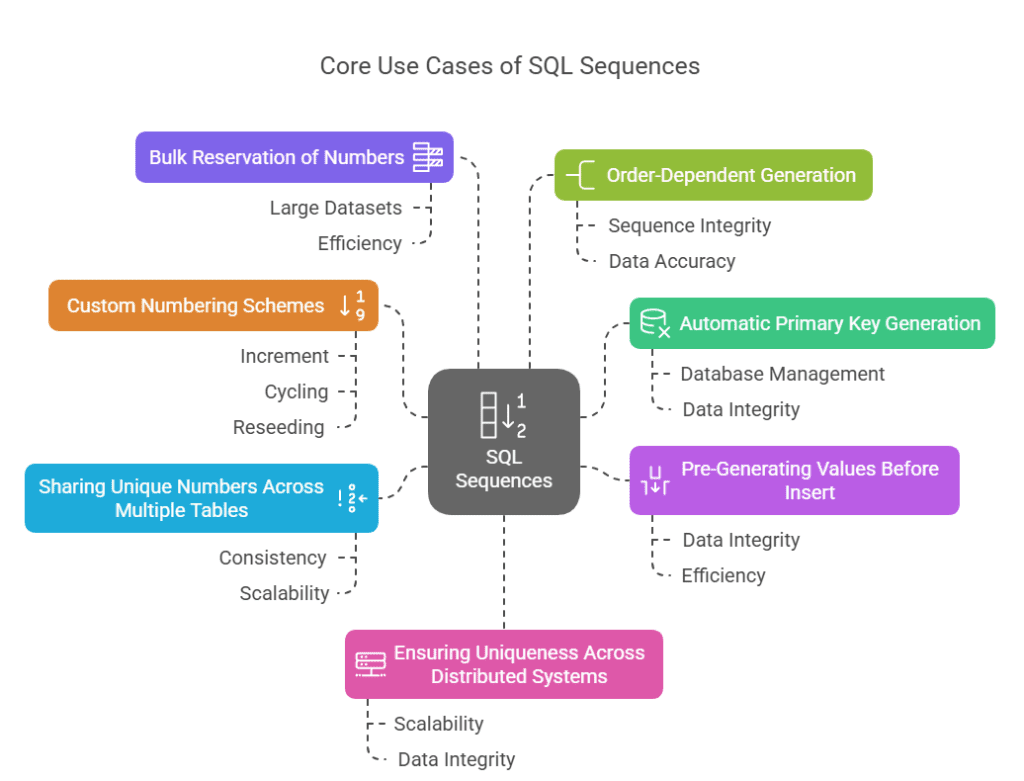
Sequences in SQL are versatile tools designed to generate unique numeric values, supporting a variety of application needs. Here are the core use cases:
Automatic Primary Key Generation
Sequences are commonly used to automatically generate unique primary key values for database tables, ensuring each row is uniquely identifiable without manual intervention. This is especially useful in systems where the primary key must be an integer and needs to be generated outside the table definition
Pre-Generating Values Before Insert
Unlike identity columns, sequences allow applications to generate a unique number before inserting a row into a table. This is valuable when the identifier is needed in application logic or as a foreign key in related tables before the actual insert occurs.
Sharing Unique Numbers Across Multiple Tables
A single sequence can be referenced by multiple tables or columns, providing a global unique identifier across different entities. This is ideal for scenarios like event tracking or audit logs, where events from different sources need a unified, sequential identifier.
Custom Numbering Schemes (Increment, Cycling, Reseeding)
Sequences can be configured to increment by any value, cycle back to a start value after reaching a maximum, or be reseeded as needed. This flexibility supports use cases such as ticket numbers, batch numbers, or business-specific numbering requirements.
Bulk Reservation of Numbers
Some systems allow reserving a range of sequence numbers in advance, which is useful for batch inserts or distributed systems that require a block of unique identifiers to minimize contention and improve performance.
Order-Dependent Generation
Sequences can be used in conjunction with ordering clauses to generate numbers in a specific order, which is useful for applications that require sorted sequence values based on another field.
Ensuring Uniqueness Across Distributed Systems
When a unique identifier must be guaranteed across multiple tables, databases, or even servers, sequences provide a reliable mechanism, although high contention may require careful management or alternatives like GUIDs for distributed environment.
Common Pitfalls When Using Sequences
Alt Text: Image showing how to avoid common pitfalls when using Sequence
While sequences are powerful and flexible, improper usage or misunderstanding of their behavior can lead to unexpected issues. Here’s an expanded look at the most common pitfalls:
Assuming Gapless Sequences
A frequent misconception is that sequence-generated values will be perfectly sequential and gapless. In reality, sequences are designed to guarantee uniqueness and order of generation, not continuity. Several factors can introduce gaps:
- Transaction Rollbacks: If you generate a sequence value during a transaction that is later rolled back, the value is not returned to the pool. That number is lost, resulting in a gap.
- Failed Transactions: Similar to rollbacks, any failed insert or operation that consumes a sequence value but does not persist data will leave a gap.
- Caching: Many databases cache sequence values in memory for performance reasons. If the database crashes or is restarted, any unused cached values are lost, creating additional gaps.
- Explicit Skipping: Some applications or scripts might intentionally or accidentally increment a sequence without using the value, causing further discontinuities.
Best Practice
If your application requires strictly gapless numbering (for example, invoice numbers mandated by law), you should not rely solely on sequences. Instead, implement additional logic at the application or database level to control numbering and handle exceptions.
Uncontrolled Cycling
Sequences can be configured to cycle, meaning they restart from the minimum value after reaching their maximum (or vice versa for descending sequences). While this feature is useful in certain scenarios, it can be dangerous if not managed properly:
- Duplicate Values: If a sequence cycles and the previous values are still in use, generating the same number again can lead to primary key violations, data corruption, or loss of data integrity.
- Business Logic Errors: Applications that assume sequence values are always unique and never reused may malfunction or produce incorrect results when cycling occurs.
- Unexpected Behavior: Developers or DBAs may not realize a sequence is set to cycle, leading to subtle bugs that surface only after a large number of values have been generated.
Best Practice
Use the CYCLE option only when you are certain that reusing values will not cause conflicts. For most primary key or unique identifier scenarios, always use NOCYCLE to prevent accidental duplication.
Lack of Documentation
Sequences are often created and used without sufficient documentation, which can lead to several problems:
- Accidental Reuse: Without clear documentation, developers might unknowingly use the same sequence for unrelated tables or purposes, causing confusion or data integrity issues.
- Misconfiguration: Lack of clarity about a sequence’s intended increment, min/max values, or cycling behavior can result in misconfiguration during schema changes or migrations.
- Maintenance Challenges: When troubleshooting or updating database schemas, unclear sequence usage makes it difficult to assess the impact of changes, increasing the risk of errors.
Best Practice
Always document each sequence’s purpose, configuration, and usage. Include comments in the database schema, maintain up-to-date documentation, and ensure all developers and DBAs understand the role of sequence in your system.
Conclusion
Sequences are a robust and flexible mechanism for generating unique values in SQL databases. They offer significant advantages over identity columns and auto-increment fields, particularly in complex or distributed systems. By understanding their syntax, use cases, and best practices, you can harness sequences to ensure data integrity, scalability, and maintainability in your database applications.
Frequently Asked Questions
What Is the Main Difference Between a Sequence and an Identity Column In SQL?
A sequence is a standalone object that can generate unique numbers for any table or application, while an identity column is tied to a specific table column and generates values only during row insertion.
Can a Sequence Be Shared Across Multiple Tables In SQL?
Yes, a sequence can serve multiple tables to ensure unique values, useful for audit logs or event tracking.
Are Sequence-Generated Values Guaranteed to Be Gapless?
No, sequence-generated values may have gaps due to rollbacks, failed transactions, or caching. If gapless numbering is required, additional logic must be implemented at the application level.
Authors
-

Written by:
Neha SinghReviewed by: