
Summary: Hash tables in Python provide efficient data storage using key-value pairs. This guide explains hashing, how to create hashes, common applications, and hash table programs in Python. It covers Python’s built-in hash function and the hashlib library for secure hashing, with practical examples and use cases.
Introduction
In this blog, we will explore the concept of a hash table in Python, a key data structure used to store key-value pairs efficiently. We’ll explain what hashing is in Python and its inner workings and provide an example of a hash table in Python.
Learn how to create a hash in Python and explore a hash table program in Python that demonstrates practical usage. We’ll also discuss hash table applications and their importance in solving complex problems.
Python has shown surprising growth in the last five years, making understanding a hash table data structure in Python even more crucial for modern development.
Key Takeaways
- Python hash tables enable efficient data storage and fast access via key-value pairs.
- The built-in hash() function creates unique hash values for immutable types.
- For secure hashing, use Python’s hashlib library with algorithms like SHA-256.
- Hash tables are used in applications like data integrity checks and password storage.
- While efficient, hash tables may face challenges like collisions and unordered data.
Understanding Hash Table in Python
A hash table in Python is a unique way to store and retrieve data quickly. It uses a unique identifier, called a hash, for each piece of data. What is hashing in Python?
Hashing is turning data, like a name or number, into a unique code (the hash) that helps the program find it easily in an extensive collection. Think of it like organising a large library where each book has its spot, and you can find any book just by knowing its title.
You can create a hash table program in Python using dictionaries, which work like hash tables. Python’s hash table data structure allows for fast lookups, additions, and deletions, making it very efficient.
It’s a powerful tool when you need to work with large amounts of data and want to access it quickly without having to search through everything.
Why Use Hashing in Python?
Hashing has several practical applications. Here are some common reasons why you might want to create a hash in Python:
- Data Integrity: Hashing is often used to ensure that data hasn’t been altered. For example, when downloading a file, a hash can be used to verify that the file hasn’t been tampered with.
- Efficient Data Retrieval: Hashing is used in data structures like hash tables (dictionaries in Python) to access and store data quickly.
- Password Storage: When storing passwords, you don’t want to save them as plain text. Instead, you can hash the password and store the hash. Later, when the user logs in, you hash the entered password and check if it matches the stored hash.
How to Create a Hash in Python
Creating a hash in Python might initially seem complex, but it’s quite simple once you break it down. In Python, we can create a hash of a piece of data using built-in functions and libraries. We can also create a hash using other methods. Let’s dive into how to do that.
Using Python’s Built-In Hash Function
Python’s built-in hash() function is a quick and convenient way to create a hash of various immutable objects. This function generates an integer hash value that is unique (or nearly unique) to the object passed into it. When you call the hash() function, it computes a hash value based on the object’s contents and returns it as an integer.
The hash() function works best with immutable data types like strings, integers, and tuples. It’s commonly used in scenarios where you need to quickly check whether two objects are equal or for storing objects in hash tables (like Python dictionaries).
However, it is essential to note that the hash value can change between Python sessions due to security measures to prevent attacks. This makes it unsuitable for persistent storage (e.g., file integrity verification or cryptographic applications).
Let’s take a deeper look at how the hash() function works in Python with various examples:
Example 1: Hashing a String
Strings in Python are immutable, so we can directly hash a string to generate its unique hash value.

Example 2: Hashing an Integer
You can also hash integers. Since integers are immutable in Python, they work seamlessly with the hash() function.

Example 3: Hashing a Tuple
Tuples, unlike lists, are immutable and can be hashed using the hash() function. This property makes tuples an ideal choice for use as keys in dictionaries.

While the hash() function is efficient and easy to use, it should not be used for storing sensitive data or cryptographic purposes. It’s intended for internal use, such as in hash tables for efficient data retrieval. Still, it isn’t suitable for cases needing a secure, irreversible hash (such as password storage).
Using the hashlib Library for Stronger Hashing
For more secure and robust hashing, Python provides the hashlib library, which allows the creation of cryptographic hashes using various algorithms such as MD5, SHA-1, and SHA-256. These algorithms are widely used in security applications where data integrity and confidentiality are essential.
The hashlib library provides a simple interface to generate hashes securely and irreversibly. Let’s break down how we can use hashlib to create secure hashes.
Example 1: Using SHA-256 for Secure Hashing
One of the most commonly used hashing algorithms is SHA-256. It produces a 64-character hexadecimal hash value, which is widely used in security protocols like SSL/TLS for data encryption.
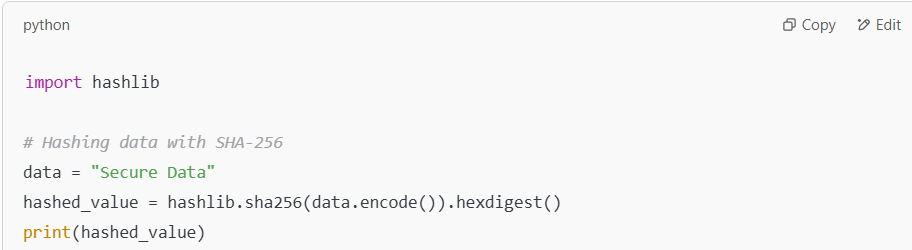
Here’s what’s happening in this example:
- data.encode(): This converts the string “Secure Data” into a byte object, which is required by the hashlib functions.
- hashlib.sha256(): This initializes the SHA-256 hashing algorithm.
- hexdigest(): This returns the hash as a hexadecimal string (a readable format of the hash).
The result is a 64-character hash string representing the “Secure Data” data. SHA-256 is particularly useful because it is designed to be collision-resistant, meaning it is doubtful that two different inputs will produce the same hash.
Example 2: Using MD5 for Quick Hashing
While SHA-256 is more secure, the MD5 algorithm is faster and has been used for various non-security-sensitive applications. However, it is now considered cryptographically broken and should be avoided for storing passwords or sensitive data. Still, it can be helpful for quick data integrity checks.

In this example, MD5 generates a 32-character hexadecimal hash value. While MD5 is faster, its vulnerabilities make it unsuitable for secure applications.
Why Use hashlib?
- Security: Hashes created with hashlib are much more secure than those made with Python’s built-in hash() function. These algorithms are designed to resist attacks and collisions.
- Versatility: Depending on your needs, you can choose from different hashing algorithms like SHA-1, SHA-256, and MD5.
- Reversibility: While hashing is by design irreversible, cryptographic hashes like SHA-256 are secure enough that reversing them is practically impossible.
In conclusion, when security is a concern, the hashlib library is the way to generate strong, irreversible hashes resistant to attacks.
Hashing Complex Data Types in Python
In Python, you can hash simple strings, integers, and complex data types such as tuples, lists, and custom objects. However, not all types of data can be hashed. Python only allows immutable types to be hashed.
This is because hash values are designed to remain constant, and mutable objects (like lists or dictionaries) could change their content, leading to incorrect hash values.
Let’s explore how to hash more complex types, such as tuples, and how to hash custom objects.
Example 1: Hashing a Tuple
A tuple is an immutable data type, which makes it hashable. This means you can safely use tuples as keys in dictionaries or store them in sets.

In this case, we’re hashing the tuple (1, 2, 3). Since tuples are immutable, they can safely be hashed, and Python will generate a unique hash value based on the tuple’s contents.
Example 2: Hashing a List (With Caution)
Unlike tuples, lists are mutable, meaning their content can change. Therefore, lists are not directly hashable in Python. Attempting to hash a list will result in a TypeError. However, you can convert a list into an immutable object like a tuple before hashing.
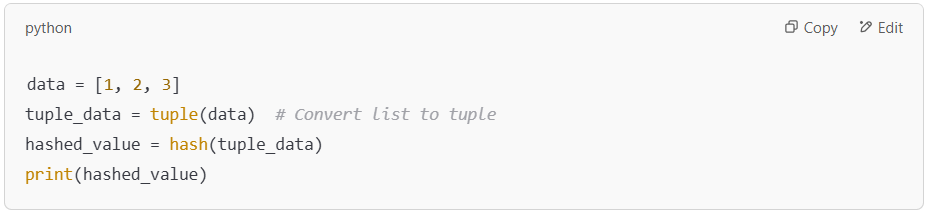
Here, we convert the list [1, 2, 3] into a tuple (1, 2, 3) before hashing it. This allows us to generate a hash for what was originally a list.
Example 3: Hashing Custom Objects
You can also hash your own custom objects, but they must be immutable. In Python, you can define the __hash__() method in your custom class to specify how the object should be hashed.

In this example, the custom class Person defines a __hash__() method, which combines the hashes of the name and age attributes. Now, the object person can be hashed.
Advantages of Hash Tables in Python
Hash tables offer several benefits, making them a powerful tool for efficient data storage and retrieval in Python. They allow quick access to data, reduce search time, and improve overall performance.
- Fast Lookups: Hash tables offer constant time (O(1)) for accessing data, making searches much quicker than other data structures.
- Efficient Insertion and Deletion: Adding or removing data is fast, as it directly accesses the location based on the key.
- Flexible Keys: You can use various keys, like strings, numbers, and even tuples.
- Memory Efficient: Hash tables only store the needed data, saving memory.
Disadvantages of Hash Tables in Python
While hash tables in Python are highly efficient, they come with some disadvantages you should be aware of. These limitations can impact performance and usability in certain situations.
- Collisions: When two different keys hash to the same index, it can slow down performance as the table needs to handle the collision.
- Unordered Data: Hash tables don’t maintain the order of elements, which can be a problem if order matters in your application.
- Memory Overhead: Hash tables consume more memory than simpler data structures like lists due to the underlying array and collision handling mechanisms.
Closing Words
Hash tables in Python are an efficient way to store and retrieve data using key-value pairs, making data access faster with constant time complexity. By utilising Python’s built-in dictionary or the hashlib library for secure hashing, developers can create optimised solutions for handling large datasets.
While hash tables excel in performance, they may face challenges like collisions and unordered data. Understanding hash tables and how to create hashes is crucial for effective data manipulation in Python, with broad applications in various fields, from password storage to data integrity verification.
If you are interested in learning Python, I recommend enrolling in Pickl.AI. This trusted platform provides hands-on experience in Python and other essential Data Science concepts. Visit the website today to learn more.
Frequently Asked Questions
What is Hashing in Python?
Hashing in Python converts data (such as strings or numbers) into a unique hash code. This allows for fast data retrieval in hash tables, ensuring efficient searches and operations.
How do You Create a Hash in Python?
To create a hash in Python, you can use the built-in hash() function for simple data types like strings, integers, and tuples. For stronger hashes, use the hashlib library, supporting algorithms like SHA-256 for security-critical applications.
What are Hash Table Applications in Python?
Hash tables are widely used for quick data lookups, storing unique database values, password storage (using secure hashing), and optimising algorithms. They are key in handling large datasets efficiently.
Authors
-

Written by:
Versha RawatReviewed by:



