
Summary: The Pandas corr() method calculates the correlation coefficients between DataFrame columns, revealing linear relationships. It supports Pearson, Kendall, and Spearman methods, aiding in insightful Data Analysis.
Introduction
Pandas is a powerful Python library widely used for Data Analysis. It offers flexible and efficient data manipulation tools. Central to Pandas is the DataFrame, a versatile structure that allows you to organise and analyse data in tabular form. Understanding relationships between variables is crucial in Data Science, and correlation analysis is an essential technique.
The Pandas correlation method, corr(), provides an easy way to calculate correlation coefficients, helping identify patterns and insights within your data. This article explores using Pandas’s corr() method for effective Data Analysis.
Read: The Power of Pandas: Mastering the concat Function in Python.
What is the corr() Method in Pandas?
The corr() method in Pandas is a powerful tool used to compute a pairwise correlation between the columns of a DataFrame. This method returns a correlation matrix, quantifying the linear relationship between different variables in the data.
The primary purpose of the corr() method is to help analysts understand the degree to which two variables are related, providing insights into patterns and potential relationships within the dataset.
See: Discovering the Basics of Pandas DataFrame LOC Method.
Definition and Purpose of the corr() Method
The corr() method is essential for performing correlation analysis in Pandas. It calculates the correlation coefficient, a statistical measure that describes the strength and direction of a linear relationship between variables.
The output is a DataFrame showing the correlation coefficients for each pair of columns. This method is widely used in Data Analysis, especially in the preliminary stages, where identifying relationships between variables is crucial.
Overview of Correlation and Its Role in Data Analysis
Correlation is a fundamental concept in statistics and Data Analysis that measures how two variables move about each other. The value of the correlation coefficient ranges from -1 to 1. A value closer to 1 indicates a strong positive relationship, while a value closer to -1 suggests a strong negative relationship.
A value around 0 implies little to no linear relationship. Understanding these correlations is vital for making informed decisions, especially in finance, economics, and social sciences.
How the corr() Method Helps in Understanding Relationships
Pandas correlation analysis, facilitated by the corr() method, allows data scientists to assess the relationships between multiple variables quickly. By generating a correlation matrix, one can identify which variables have strong positive or negative correlations, which can then inform feature selection, risk management, and predictive modelling.
This method is a foundational tool in exploratory Data Analysis, enabling analysts to uncover hidden patterns and make data-driven decisions.
Check: Understanding the Basics of Pandas Dataframe.append().
Syntax of the corr() Method
Pandas’s corr() method is straightforward and versatile, making it a go-to tool for calculating correlations within a DataFrame. Using this method, you can quickly generate a correlation matrix highlighting the relationships between various columns in your dataset.
General Syntax of the corr() Method in a DataFrame
The general syntax for using the corr() method in a DataFrame is as follows:

In this syntax, DataFrame refers to the Pandas DataFrame on which you want to perform the correlation analysis. The method calculates the correlation coefficient for each pair of columns in the DataFrame and outputs a new DataFrame that displays these coefficients.
Explanation of Different Parameters in the corr() Method
The corr() method offers several parameters that allow you to customise the correlation analysis according to your needs:
- method: This parameter determines the type of correlation coefficient to be calculated. You can choose from three options:
- ‘pearson’: The default method calculates the Pearson correlation coefficient suitable for linear relationships.
- ‘kendall’: Computes the Kendall Tau correlation, which benefits ordinal data or non-linear relationships.
- ‘spearman’: Calculates the Spearman rank correlation, ideal for monotonic relationships.
- min_periods: This parameter specifies the minimum number of observations required to compute a valid correlation. If the number of non-NA observations is below this threshold, the result will be NA. This is particularly useful when dealing with datasets containing missing values.
Examples of Using the corr() Method with Different Parameters
Here’s how you can use the corr() method with different parameters to perform Pandas correlation analysis:
- Default Pearson Correlation:

This command calculates the Pearson correlation coefficient for each pair of columns.
- Spearman Correlation:

By specifying method=’spearman’, you calculate the Spearman rank correlation.
- Handling Missing Data with min_periods:

This example sets min_periods to 3, ensuring that correlations are only calculated if at least three non-NA observations exist.
Using the corr() method with these parameters provides flexibility in how you perform and interpret your Pandas correlation analysis, enabling you to tailor the analysis to the specific characteristics of your dataset.
Further Explore:
Ultimate Pandas Cheat Sheet: Mastering Pandas.
Let’s Understand the Difference Between Data and Information.
Why Python is Essential for Data Analysis.
Types of Correlation Methods Supported by corr()
Pandas’s corr() method supports three primary types of correlation methods: Pearson, Kendall, and Spearman. Each method provides a different approach to measuring the strength and direction of the relationship between variables. Understanding these methods is crucial for accurate Data Analysis, as each has strengths and use cases.
Pearson Correlation Coefficient
The Pearson correlation coefficient is the most widely used measure of linear correlation between two variables. It calculates the degree to which two variables move in tandem, offering insights into whether an increase in one variable leads to an increase (or decrease) in another. The Pearson correlation value ranges from -1 to 1, where:
- 1 indicates a perfect positive linear relationship.
- -1 indicates a perfect negative linear relationship.
- 0 indicates no linear relationship.
A Pearson correlation close to 1 suggests that as one variable increases, the other also increases nearly proportionally. Conversely, a value close to -1 indicates that as one variable increases, the other decreases proportionally.
How to Use the method=’pearson’ Parameter
In Pandas, the corr() method uses Pearson correlation as the default option. To explicitly specify this method, you can set the method parameter to ‘pearson’. This method is appropriate when you assume a linear relationship between the variables and when both are continuous and normally distributed.
Example Code Demonstrating Pearson Correlation
Here’s how you can calculate the Pearson correlation coefficient in Pandas:
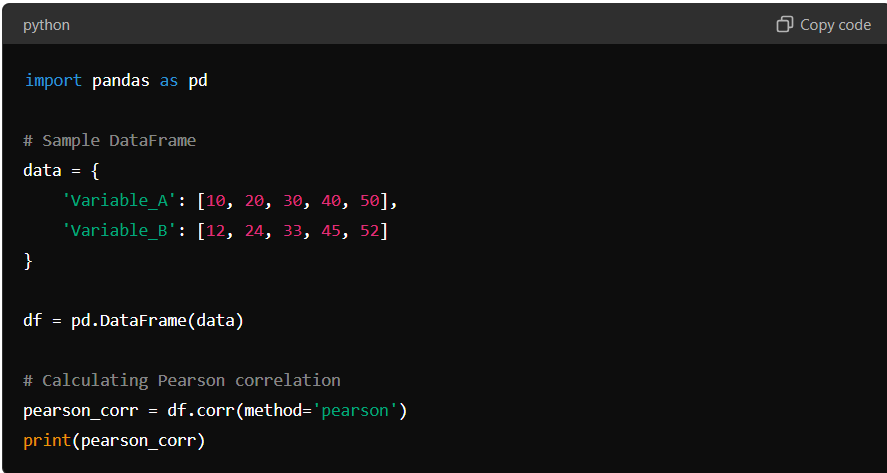
In this example, Variable_A and Variable_B have a strong positive linear relationship, as indicated by a Pearson correlation value close to 1. The corr() method calculates this by default using the Pearson method, making it straightforward to understand the linear relationship between variables.
Kendall Correlation
The Kendall correlation coefficient, or Kendall’s Tau, measures the ordinal association between two variables. Unlike Pearson, which measures linear relationships, Kendall correlation assesses the strength of association based on the data’s ranks. It is handy for datasets that do not satisfy the assumptions of normality or linearity.
Kendall’s Tau ranges from -1 to 1:
- 1 indicates perfect agreement between the rankings of the two variables.
- -1 indicates perfect disagreement.
- 0 suggests no association between the rankings.
This method is robust to outliers and is preferred when dealing with ordinal data or when the relationship between variables is not necessarily linear.
How to Use the method=’kendall’ Parameter
To use the Kendall correlation in Pandas, you simply set the method parameter to ‘kendall’. This approach is beneficial when your data involves ranks or when you expect a non-linear relationship between variables.
Example Code Demonstrating Kendall Correlation
Below is an example of how to calculate Kendall’s Tau in Pandas:
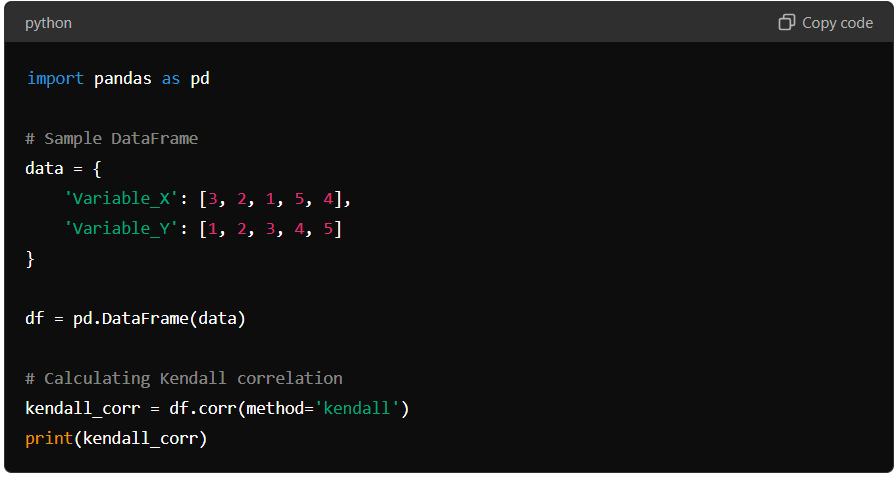
In this case, Variable_X and Variable_Y have a moderate positive association, according to Kendall’s Tau, which considers the data’s relative ordering rather than the specific values.
Spearman Correlation
The Spearman correlation coefficient, or Spearman’s rank correlation, is another non-parametric measure of correlation that assesses the strength and direction of association between two ranked variables. Like Kendall’s Tau, Spearman correlation does not require the data to be normally distributed and is based on the rank order of the data.
Spearman correlation is beneficial when the relationship between variables is monotonic but not necessarily linear. A monotonic relationship means that as one variable increases, the other variable consistently increases or decreases, but not necessarily at a constant rate.
The Spearman correlation coefficient also ranges from -1 to 1:
- 1 indicates a perfect positive monotonic relationship.
- -1 indicates a perfect negative monotonic relationship.
- 0 indicates no monotonic relationship.
How to Use the method=’spearman’ Parameter
To calculate Spearman correlation in Pandas, you can set the method parameter to ‘spearman’. This method is appropriate when the data does not meet the assumptions of normality and linearity or when dealing with ordinal data.
Example Code Demonstrating Spearman Correlation
Here’s how you can calculate the Spearman correlation coefficient:
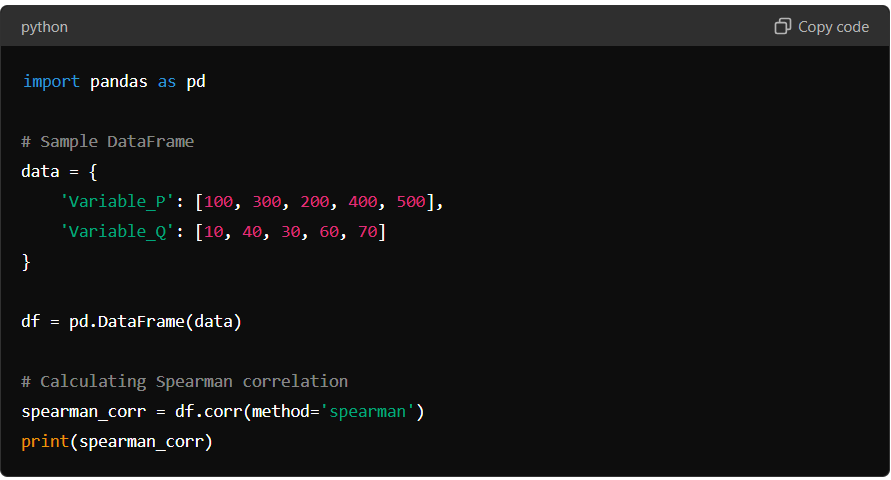
In this example, Variable_P and Variable_Q may exhibit a monotonic relationship, as reflected by the Spearman correlation value. This method is particularly advantageous when the relationship between variables is not strictly linear, making it a versatile tool in Pandas correlation analysis.
Check: Discovering The Basics of Linear Data Structure: Features and Fundamentals.
Working with the corr() Method: Practical Examples
Pandas’s corr() method is a versatile tool that allows you to explore relationships between variables in a DataFrame. You can extract meaningful insights from your data by effectively understanding how to use this method.
Basic Example: Calculating Correlation Between Columns in a Simple DataFrame
Let’s look at a basic example to begin using the corr() method. Suppose you have a DataFrame with columns representing different variables. Using the corr () method, you can easily calculate the correlation between these columns.
Here’s an example:
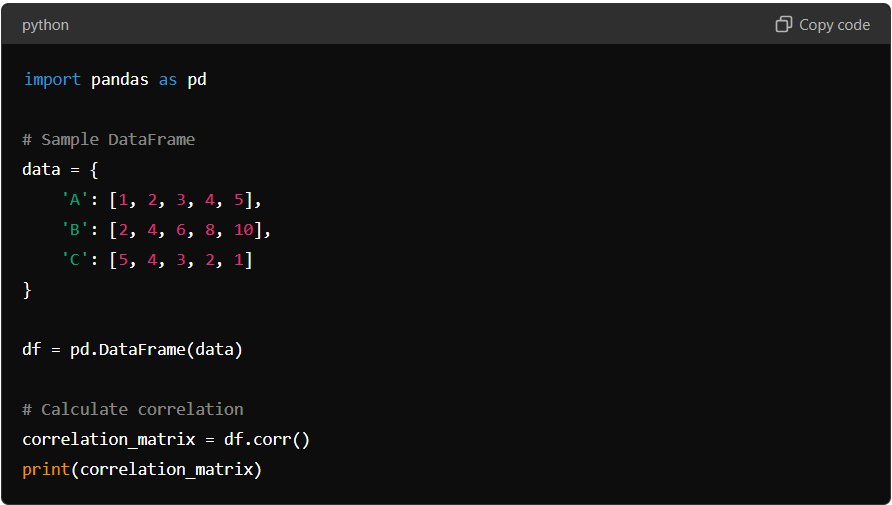
In this example, the Pandas correlation matrix reveals the relationships between the columns. For instance, columns A and B have a perfect positive correlation of 1, indicating a strong linear relationship, while columns A and C have a perfect negative correlation of -1.
Handling Missing Data: How corr() Deals with NaN Values
Real-world datasets often contain missing values, which can affect correlation calculations. By default, the corr() method in Pandas automatically excludes NaN values when computing correlations. However, managing these missing values appropriately depends on your analysis needs is important.
If you want to fill missing values before calculating correlation, you can use the fillna() method:

This approach ensures that missing data does not skew your Pandas correlation results.
Customising Output: Using the min_periods Parameter
The min_periods parameter in the corr() method allows you to specify the minimum number of observations required to calculate a valid correlation. This is particularly useful when dealing with incomplete data. For example, you might want to ensure that at least three valid data points are available before calculating the correlation:

By setting min_periods, you can control the robustness of your correlation calculations and ensure that the results are based on sufficient data.
Understanding these practical examples of using the Pandas correlation method helps you make more informed decisions when analysing your data, especially when dealing with real-world datasets that may include missing values or require specific analysis conditions.
Interpreting the Results of corr()

Understanding the results from the corr() method in Pandas is crucial for extracting meaningful insights from your data. The correlation matrix provides a detailed view of how variables relate to one another, which can guide your Data Analysis and decision-making process. Let’s explore how to interpret these results effectively.
Understanding the Correlation Matrix
The correlation matrix is a table that displays correlation coefficients between multiple variables. Each cell in the matrix represents the correlation value between two variables, ranging from -1 to 1.
A matrix with high absolute values (close to -1 or 1) indicates a strong relationship, while values close to 0 suggest a weak or no linear relationship.
Positive vs. Negative Correlation
In the correlation matrix, a positive correlation means that as one variable increases, the other variable also tends to grow.
For example, if both variables show higher values, their correlation coefficient will be positive. Conversely, a negative correlation indicates that the other variable tends to decrease as one variable increases. A negative correlation coefficient reflects this inverse relationship.
Strong vs. Weak Correlation
Correlation coefficients close to 1 or -1 denote a strong correlation, implying that the variables are highly related.
For instance, a coefficient of 0.9 signifies a strong positive correlation. On the other hand, coefficients around 0 suggest a weak or no correlation, meaning that changes in one variable have little to no predictable impact on the other.
Visualising Correlation Matrices Using Heatmaps
Visualising the correlation matrix using a heatmap is highly effective for better interpreting it. Heatmaps use colour gradients to represent correlation values, making it easier to identify patterns and relationships at a glance.
Darker colours typically indicate stronger correlations, while lighter colours represent weaker correlations. This visualisation can quickly reveal trends and associations, facilitating a clearer understanding of your data’s dynamics.
See More: Seaborn vs Matplotlib: A Comprehensive Comparison for Data Visualisation.
Use Cases of corr() in Data Analysis
The corr() method in Pandas is a valuable tool for data analysts, offering insights into how different variables relate. Understanding these relationships is crucial for making informed decisions and refining Data Analysis strategies. Here are some key use cases of the corr() method in Data Analysis:
Identifying Multicollinearity in Regression Analysis
Multicollinearity occurs when two or more independent variables in a regression model are highly correlated. This can lead to unreliable coefficient estimates and inflated standard errors, ultimately affecting the model’s performance.
Using the corr() method, analysts can identify which variables are highly correlated, allowing them to address multicollinearity issues. A correlation matrix can reveal which variables have high correlation coefficients, guiding decisions on variable selection or transformation to improve model stability.
Feature Selection Based on Correlation
Feature selection is a critical step in building effective machine learning models. The corr() method helps select features by identifying the most relevant variables to the target variable. A high correlation between a feature and the target suggests that the feature will likely be valuable for prediction.
Conversely, features that are highly correlated with each other can be redundant. By examining the correlation matrix, analysts can choose features that provide unique information and exclude those that contribute little to the model’s predictive power.
Exploring Relationships in Exploratory Data Analysis (EDA)
In Exploratory Data Analysis, understanding relationships between variables is essential for generating hypotheses and insights. The corr() method provides a straightforward way to explore these relationships by producing a correlation matrix highlighting how variables interact.
This matrix can reveal trends, patterns, and potential areas of interest, guiding further analysis. For instance, identifying solid correlations between variables can suggest places for deeper investigation or inform the development of new features.
By effectively leveraging the corr() method, analysts can enhance their Data Analysis process, leading to more accurate models and actionable insights.
Common Pitfalls and Best Practices
When using the corr() method in Pandas for correlation analysis, it’s crucial to navigate common pitfalls and adhere to best practices to ensure accurate and meaningful results. Correlation analysis can provide valuable insights but also requires careful interpretation and understanding of the underlying data.
Misinterpretation of Correlation
One of the most frequent pitfalls in correlation analysis is confusing correlation with causation. The corr() method measures the strength and direction of a linear relationship between two variables but does not imply that one variable causes the other to change.
For instance, a high correlation between ice cream sales and drowning incidents does not mean that buying ice cream causes drowning; instead, both might be influenced by a third factor, such as hot weather.
Importance of Understanding the Data Context
Before concluding correlation analysis, it’s essential to understand the context of your data. Correlation coefficients provide insights into relationships but don’t account for external factors or underlying mechanisms.
For example, two variables may strongly correlate due to an external influence or data anomalies. Ensuring you clearly understand the data’s context helps avoid misleading conclusions and supports more accurate interpretations.
Best Practices When Using corr() for Accurate Analysis
When using the corr() method in Pandas for correlation analysis, adhering to best practices ensures accurate and meaningful results. Here are some key best practices to consider:
Handle Missing Values
The corr() method automatically excludes NA/null values from the calculations. However, it’s crucial to understand how missing data can affect your analysis. Before calculating correlations, consider:
Imputing Missing Values: Fill in missing values using techniques such as mean, median, or mode imputation, or more advanced methods like K-nearest neighbours (KNN) imputation.
Dropping Missing Values: If the amount of missing data is small, you may choose to drop those rows or columns to maintain the integrity of your analysis.
Specify min_periods
The min_periods parameter specifies the minimum number of observations required per pair of columns to produce a valid result. Setting this parameter appropriately can prevent misleading results caused by insufficient data. For example, if you set min_periods=5, the correlation will only be calculated for pairs of columns that have at least five non-null observations.
Use numeric_only Parameter
By default, the corr() method considers all data types. However, if your DataFrame contains non-numeric data, you may want to set the numeric_only parameter to True. This ensures that only numeric columns are included in the correlation calculation, leading to more accurate results.
Visualise Correlation Matrices
Visualising the correlation matrix can provide insights that raw numbers might not convey. Use heatmaps to represent the correlation coefficients visually. Libraries like Seaborn and Matplotlib can be helpful for this purpose. A heatmap can quickly highlight strong correlations and help identify patterns in the data.
By being mindful of these pitfalls and best practices, you can effectively leverage the corr() method in Pandas, gaining valuable insights while avoiding common errors in data interpretation.
Bottom Line
The Pandas corr() method is an essential tool for Data Analysis, providing valuable insights into the relationships between variables in a DataFrame. Calculating correlation coefficients can uncover patterns, assess variable interdependencies, and enhance your Data Analysis strategy.
Understanding the different correlation methods—Pearson, Kendall, and Spearman—allows for more nuanced interpretations and better decision-making in your data projects.
Frequently Asked Questions
What is the Pandas Correlation Method Used For?
The Pandas correlation method calculates the pairwise correlation coefficients between columns in a DataFrame. It helps identify the strength and direction of linear relationships between variables.
How Do You Use the corr() Method in Pandas?
To use the corr() method in Pandas, call it on a DataFrame object. For example, df.corr() computes the correlation matrix, displaying relationships between columns based on the chosen correlation method.
What Are The Types of Correlation Methods Supported by Pandas?
Pandas support three correlation methods: Pearson for linear relationships, Kendall for ordinal data, and Spearman for monotonic relationships. Use the method parameter in corr() to specify the desired method.
Authors
-

Written by:
Smith AlexReviewed by:



