Summary: Multimodal AI is an advanced artificial intelligence approach that processes and integrates multiple data types, such as text, images, audio, and video—simultaneously. This capability allows AI systems to better understand complex scenarios, provide context-rich outputs, and solve a wider variety of problems than unimodal models, making them highly versatile across industries.
Introduction – What is Multimodal AI?
Multimodal AI is a transformative branch of artificial intelligence that enables machines to process, understand, and synthesize information from multiple data types—such as text, images, audio, and even sensor data—simultaneously.
Unlike traditional AI systems that operate on a single modality (for example, only text or only images), multimodal AI can “see,” “hear,” and “read” at the same time, allowing it to interpret the world more like a human does.
This capability is crucial in today’s data-rich environment, where information is rarely confined to a single format. For instance, a social media post may include text, images, and video; a medical diagnosis may require interpreting written records, X-rays, and spoken patient histories.
Multimodal AI’s strength lies in its ability to integrate these diverse data streams, yielding deeper insights, more accurate predictions, and more natural interactions between humans and machines.
Key Takeaways
- Multimodal AI simultaneously processes multiple data types for deeper understanding.
- It enables richer, more context-aware responses than unimodal AI systems.
- Fusion modules integrate features from text, images, audio, and video.
- Applications span healthcare, security, customer service, and autonomous vehicles.
- Requires diverse, well-labelled data and advanced neural network architectures
How Multimodal AI Works
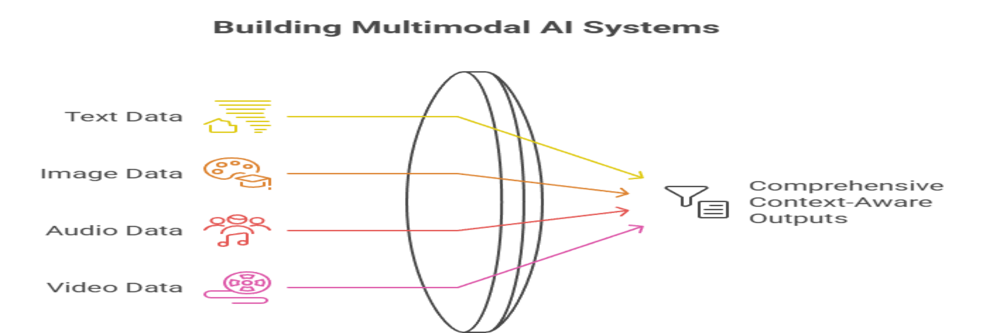
Multimodal AI systems are designed to process and integrate information from multiple data types—such as text, images, audio, and video—to produce more comprehensive and context-aware outputs than traditional, single-modality AI. This is achieved through a carefully structured architecture comprising several specialized components and processes
Data Collection and Preprocessing
Multimodal AI starts by collecting data from various sources. These could include:
- Text (documents, chat logs, social media posts)
- Images (photos, medical scans, satellite imagery)
- Audio (speech, environmental sounds, music)
- Video (combining images and audio over time)
- Sensor data (temperature, motion, location)
Each data type is preprocessed using specialized techniques: natural language processing (NLP) for text, computer vision for images, and audio signal processing for sound.
Feature Extraction
Each modality is passed through a dedicated neural network to extract relevant features. For instance, a convolutional neural network (CNN) might analyze images, while a transformer model processes text. These networks convert raw data into high-level representations or “embeddings” that capture essential information.
Fusion and Alignment
The heart of multimodal AI is the fusion step, where features from different modalities are combined. There are several approaches:
- Early fusion: Data is combined at the input level before feature extraction.
- Late fusion: Separate features are extracted from each modality, then merged for decision-making.
- Hybrid fusion: Combines both early and late fusion for maximum flexibility.
Advanced models use attention mechanisms to align information across modalities, ensuring, for example, that a caption refers to the correct part of an image or that spoken instructions are linked to visual elements.
Decision and Output
The fused data is processed by downstream models to generate predictions, classifications, or generative outputs. The result could be a diagnosis, a product recommendation, a synthesized image, or a conversational response—often in a modality different from the input (e.g., generating text from an image).
Real-World Applications of Multimodal AI

Multimodal AI is revolutionizing industries by enabling smarter, more context-aware solutions. Here are some leading examples and use cases:
Healthcare
- Diagnosis and Treatment: Combines electronic health records, medical imaging, and physician notes for comprehensive patient analysis, improving diagnostic accuracy and enabling personalized care.
- Virtual Health Assistants: Integrate speech recognition, text analysis, and image interpretation to provide real-time support to clinicians and patients.
E-commerce and Retail
- Product Recommendations: Analyze customer reviews (text), product images, and purchase history to suggest relevant products.
- Visual Search: Shoppers can upload images to find similar products, powered by computer vision and NLP (e.g., Amazon’s StyleSnap).
- Inventory Management: Combine shelf camera feeds, RFID data, and sales logs for real-time stock optimization (e.g., Walmart).
Autonomous Vehicles
- Navigation and Safety: Fuse data from cameras, radar, lidar, and GPS for real-time decision-making, enabling safer and more reliable self-driving cars.
- Driver Assistance: Systems like automated emergency braking and adaptive cruise control rely on multimodal sensor integration.
Finance
- Fraud Detection: Merge transaction logs, user behavior patterns, and document analysis to identify suspicious activities and prevent fraud (e.g., JP Morgan’s DocLLM).
- Document Processing: Automate the extraction and analysis of data from contracts, invoices, and statements using OCR and NLP.
Customer Service
- Conversational AI: Virtual agents interpret voice tone, facial expressions, and text to deliver more empathetic, effective support.
- Sentiment Analysis: Analyze multimodal customer feedback to gauge satisfaction and improve service quality.
Manufacturing and Energy
- Predictive Maintenance: Combine visual inspections, sensor data, and operational logs to anticipate equipment failures and optimize maintenance schedules.
- Resource Management: Integrate geological, environmental, and operational data for efficient energy production (e.g., ExxonMobil).
Smart Homes and IoT
- Home Automation: Devices respond to voice commands, gestures, and environmental cues, enabling seamless control of lights, security, and climate.
Social Media and Content Moderation
- Content Analysis: Simultaneously process text, images, and videos to detect harmful or inappropriate content, improve recommendations, and personalize feeds.
Education and Accessibility
- Personalized Learning: Combine student performance data, written assignments, and video interactions for tailored educational experiences.
- Assistive Technologies: Convert speech to text, describe images for the visually impaired, and enable inclusive digital access.
Key Technologies Behind Multimodal AI
Multimodal AI relies on a sophisticated blend of machine learning architectures, data processing methods, and integration techniques to combine and interpret information from diverse data types such as text, images, audio, and video. Below are the core technologies and components that enable multimodal AI to function effectively:
Neural Networks
- Convolutional Neural Networks (CNNs): Extract features from images and video.
- Recurrent Neural Networks (RNNs) and Transformers: Process sequential data like text and audio.
- Multimodal Transformers: Unified architectures (e.g., OpenAI’s GPT-4o, Google Gemini) that handle multiple data types in a single model.
Fusion Techniques
- Joint Embeddings: Map different modalities into a shared space for easier comparison and integration.
- Attention Mechanisms: Dynamically focus on relevant parts of each modality for better alignment and context.
Training Data and Optimization
- Large-Scale Multimodal Datasets: Essential for robust model training; synthetic data and automated labeling are increasingly used to fill gaps and reduce bias.
- Transfer Learning: Pretrained models on one modality can be adapted to multimodal tasks, speeding up development.
Edge Computing
- On-Device Processing: Lightweight multimodal AI models now run on smartphones, drones, and IoT devices, enabling real-time analysis without cloud dependency.
Benefits of Multimodal AI
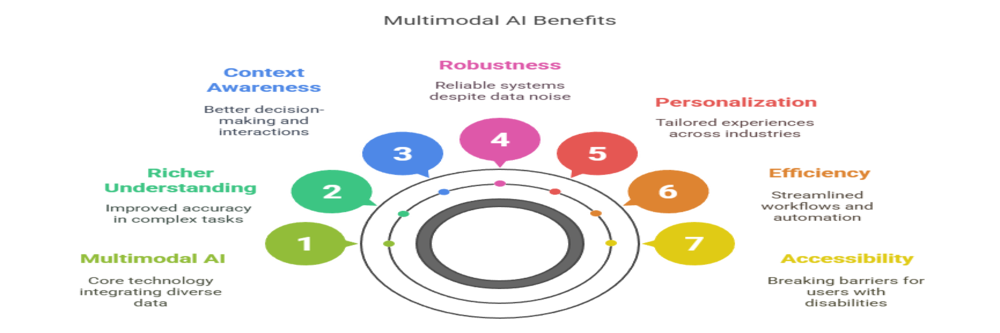
Multimodal AI is rapidly redefining how machines interpret, interact with, and impact the world. By integrating data from multiple sources—such as text, images, audio, and video—multimodal AI delivers a range of benefits that single-modality systems cannot match. Below are the key advantages of multimodal AI, supported by industry examples and expert analysis.
- Richer Understanding: Integrates diverse data for a more holistic view, improving accuracy in complex tasks.
- Context Awareness: Considers multiple sources simultaneously, leading to better decision-making and more human-like interactions.
- Robustness: If one data stream is noisy or missing, others can compensate, making systems more reliable.
- Personalization: Enables tailored experiences in healthcare, retail, education, and beyond.
- Efficiency: Streamlines workflows by automating complex, multi-step processes (e.g., document processing, predictive maintenance).
- Accessibility: Breaks down barriers for users with disabilities by converting and integrating modalities (e.g., speech-to-text, image descriptions).
Challenges in Multimodal AI Development

Developing and deploying multimodal AI systems—those that integrate and process data from multiple modalities such as text, images, audio, and video—offers transformative potential but also presents a complex array of technical, operational, and ethical challenges. Here are the key obstacles organizations and researchers face in this rapidly evolving field:
- Data Collection and Labeling: Gathering and annotating large, high-quality multimodal datasets is resource-intensive.
- Integration Complexity: Aligning and fusing heterogeneous data types requires sophisticated algorithms and careful engineering.
- Model Interpretability: Multimodal systems can be “black boxes,” making it difficult to understand how decisions are made.
- Bias and Fairness: Ensuring that models do not propagate or amplify biases present in any modality is a persistent challenge.
- Scalability: Training and deploying large multimodal models demands significant computational resources and infrastructure.
- Real-Time Processing: Achieving low-latency, on-device inference for applications like autonomous vehicles and smart homes remains technically demanding.
The Future of Multimodal AI

The trajectory of multimodal AI in 2025 and beyond is marked by rapid innovation and industry adoption. Several trends are shaping its evolution:
- Unified Foundation Models: AI giants like OpenAI (GPT-4o), Google (Gemini), and Meta (ImageBind) are developing models that seamlessly handle text, images, audio, and more within a single architecture, streamlining deployment and enhancing performance across use cases.
- Rise of Multimodal AI Agents: Autonomous agents capable of interacting through voice, vision, and text are becoming commonplace in healthcare, finance, retail, and smart devices, offering more natural, human-like experiences.
- Industry-Specific Solutions: Multimodal AI is being tailored for niche applications—precision farming, advanced manufacturing, personalized education, and more—delivering targeted value and operational efficiency.
- Edge AI: Lightweight multimodal models are running on mobile and IoT devices, enabling real-time, offline functionality for autonomous vehicles, wearables, and field sensors.
- Market Growth: The global multimodal AI market is projected to grow exponentially, from $1 billion in 2023 to $4.5 billion by 2028, reflecting its increasing strategic importance across sectors.
Conclusion
Multimodal AI is not just a technological trend—it’s a paradigm shift in how machines interact with the world. By combining text, vision, and sound, they are making machines smarter, more adaptable, and more attuned to the rich complexity of human experience.
As the technology matures, its impact will be felt across every industry, shaping a future where AI understands us—and our world—better than ever before.
Frequently Asked Questions
What is Multimodal AI?
Multimodal AI is a type of artificial intelligence that can process, interpret, and synthesize information from multiple data types—such as text, images, audio, and video, simultaneously. This enables more comprehensive understanding, richer insights, and more natural interactions between humans and machines.
What is the Difference Between Generative AI and Multimodal AI?
Generative AI refers to systems that can create new content (text, images, audio, etc.) based on learned patterns. Multimodal AI, by contrast, focuses on integrating and understanding multiple data types at once.
Some generative AI models are also multimodal (e.g., GPT-4o, which can generate and interpret text, images, and audio), but not all generative AI is multimodal. In summary, generative AI is about creation, while multimodal AI is about integration and holistic understanding.
Is ChatGPT Multimodal?
Early versions of ChatGPT were text-only (unimodal). However, with the release of models like GPT-4o, ChatGPT now has multimodal capabilities, allowing it to process and generate text, images, and audio, making it a true multimodal AI system.
What is Multimodal AI in 2025?
In 2025, multimodal AI stands at the forefront of artificial intelligence innovation. Unified models like Google Gemini, OpenAI GPT-4o, and Meta ImageBind are leading the field, powering applications across healthcare, finance, e-commerce, autonomous vehicles, and more.
These systems are increasingly integrated into everyday technologies, delivering more human-like understanding, improved accessibility, and transformative business value.
Authors
-

Written by:
Versha RawatReviewed by: