Summary: The snowflake schema in data warehouse organizes data into normalized, hierarchical dimension tables to reduce redundancy and enhance integrity. While it optimizes storage and supports complex relationships, it increases query complexity and slows performance. Ideal for large datasets with hierarchical structures but less suitable for simple reporting needs.
Introduction
A snowflake schema is a sophisticated data modeling technique used in data warehousing to efficiently organize and store large volumes of data. It is an extension of the star schema, designed to optimize storage, enhance data integrity, and support complex analytical queries.
In the snowflake schema, dimension tables are normalized into multiple related tables, creating a hierarchical structure that resembles a snowflake. This approach is particularly valuable for organizations aiming to manage highly structured, multi-level data with minimal redundancy and greater consistency.
Example of Snowflake Schema
Consider a sales data warehouse:
- Fact Table:
Sales(sales_id, date_id, customer_id, product_id, store_id, sales_amount)
- Dimension Tables:
- Customer(customer_id, customer_name, region_id)
- Region(region_id, region_name)
- Product(product_id, category_id)
- Category(category_id, category_name)
- Store(store_id, city_id)
- City(city_id, city_name, country_id)
- Country(country_id, country_name)
In this example, the Customer table links to a Region table, and Store links to City and then to Country. This multi-level normalization reduces data redundancy and forms a snowflake-like structure
What is Snowflaking?
Snowflaking is the process of normalizing dimension tables in a data warehouse schema. Instead of storing all attributes in a single dimension table (as in a star schema), snowflaking splits these tables into multiple related sub-tables.
This process increases the number of tables and relationships but reduces data duplication and improves data integrity. Snowflaking is especially useful when dimension data has hierarchical relationships, such as country, region, and city.
Characteristics of Snowflake Schema
Several distinct characteristics define the snowflake schema in data warehousing, setting it apart from other schema designs, especially the star schema. Here are the key characteristics:
Normalization of Dimension Tables
Highly normalized dimension tables split into multiple related sub-tables. This process eliminates data redundancy and organizes data into logical groupings, ensuring that each attribute remains stored only once.
Hierarchical Structure
The schema forms a hierarchical, multi-level structure, where designers break down dimension tables into multiple layers. For example, a single “Location” dimension might divide into separate tables for Country, State, and City, reflecting real-world hierarchies.
Central Fact Table
At the core of the snowflake schema is a central fact table that stores measurable, quantitative data (facts). This table connects to the normalized dimension tables via foreign keys, maintaining the schema’s integrity.
Reduced Data Redundancy
By normalizing the dimension tables, the snowflake schema significantly reduces data duplication. Each piece of information is stored once, optimizing storage and improving consistency.
Complex Joins Required
Queries in a snowflake schema require more table joins because of the multiple levels of dimension tables. This can make querying more complex and may impact performance compared to simpler schemas.
Optimized Storage Usage
Due to the elimination of redundant data, the snowflake schema uses less storage space. Studies show that you can reduce storage requirements by up to 30% compared to denormalized schemas.
High Data Integrity
The normalized design ensures high data integrity, as updates or changes to a single attribute reflect throughout the schema without inconsistencies.
Supports Detailed, Granular Data
The schema is well-suited for representing detailed, multi-level data, supporting drill-down analysis and complex reporting needs
Difference Between Snowflake and Star Schema
The star schema and snowflake schema are two foundational data modelling approaches in data warehousing, each with distinct structures, advantages, and use cases. Here’s a detailed comparison based on the latest industry insights:
Structure
Star Schema
Features a central fact table directly connected to denormalized dimension tables. All dimension tables are one step away from the fact table, resulting in a simple, intuitive structure that resembles a star.
Snowflake Schema
Extends the star schema by normalizing dimension tables into multiple related sub-dimension tables. This creates a multi-level, hierarchical structure that reduces redundancy but increases complexity.
Complexity
Star Schema
Simple and easy to design, with fewer joins required for queries.
Snowflake Schema
More complex due to normalization and additional joins between tables, making query design and maintenance more challenging.
Data Redundancy and Storage
Star Schema
Higher data redundancy because dimension tables are denormalized, leading to repeated information and increased storage requirements.
Snowflake Schema
Lower redundancy as data is normalized. Information is stored only once, reducing storage needs and improving data consistency.
Query Performance
Star Schema
Delivers faster query performance since fewer joins are needed. This makes it ideal for analytical queries and business intelligence reporting where speed is critical.
Snowflake Schema
Queries are generally slower due to the need for multiple joins across normalized tables. The increased complexity can impact performance, especially with large datasets.
Ease of Maintenance
Star Schema
Easier to maintain and update, as changes in dimension tables have limited impact.
Snowflake Schema
More complex to maintain, as changes in one table may affect multiple related tables.
Best Use Cases
Star Schema
Suited for small to medium-sized datasets, OLAP systems, dashboards, and scenarios where query speed and simplicity are priorities.
Snowflake Schema
Ideal for large, complex datasets with hierarchical relationships, where storage efficiency and data integrity are more important than query speed
Advantages and Disadvantages of Snowflake Schema in data warehouse
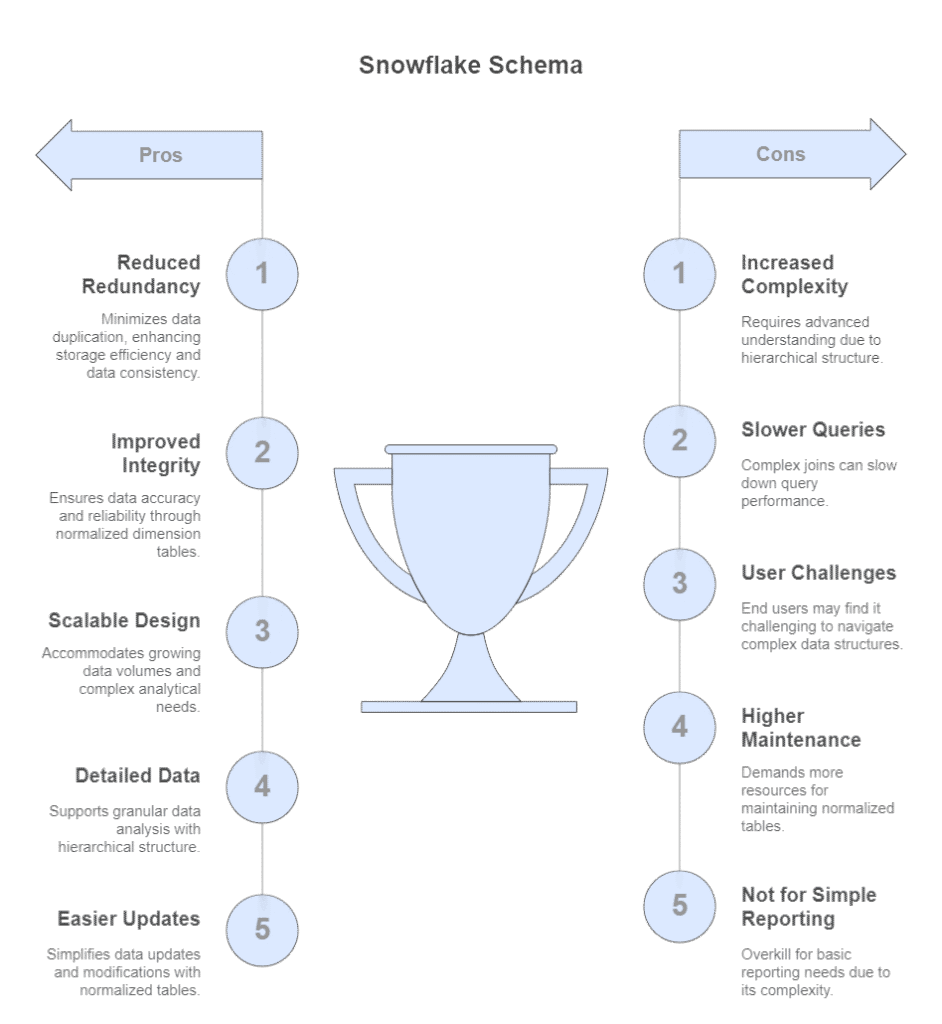
The snowflake schema excels in scenarios where data integrity, storage efficiency, and support for detailed, hierarchical analysis are priorities, but it comes with trade-offs in complexity and query performance. Many experts recommend starting with a star schema and adopting snowflaking only when its specific benefits are need
Advantages
Reduced Data Redundancy
By normalizing dimension tables, the snowflake schema eliminates duplicate data, leading to more efficient storage and less disk space usage.
Improved Data Integrity
Since each piece of information is stored only once, updates and changes are easier to manage, reducing the risk of inconsistencies and improving overall data quality.
Scalable and Flexible
The structure is well-suited for large, complex, and hierarchical datasets, making it easier to adapt to evolving business requirements and support granular analysis.
Optimized for Detailed Data
Supports multi-level relationships and drill-down analysis, allowing users to analyze data at various levels of detail.
Easier Maintenance for Updates
Changes in dimension attributes only need to be made in one place, simplifying maintenance, especially for large data warehouses.
Disadvantages
Increased Complexity
The schema involves more tables and relationships, making it harder to design, understand, and maintain, especially for business users.
Slower Query Performance
Queries require more joins due to normalized tables, which can lead to slower response times and higher resource consumption, particularly with large datasets.
Challenging for End Users
The additional layers and relationships can make it more difficult for end users to write queries or navigate the schema without technical expertise.
Higher Maintenance Overhead
More tables and relationships mean more ETL processes to manage, increasing the workload for data engineers and administrators.
Not Ideal for Simple Reporting
For straightforward analytics and reporting, the added complexity may not provide significant benefits and can hinder performance.
Conclusion
The snowflake schema in data warehouse is a powerful data modeling approach in data warehousing, particularly suited for organizations dealing with complex, hierarchical data and seeking to optimize storage and maintain high data integrity.
While it introduces additional complexity and may slow down queries due to increased joins, its benefits in terms of storage efficiency and data consistency often outweigh the drawbacks in scenarios where data relationships are intricate and normalization is essential.
Choosing between snowflake and star schema depends on your organization’s specific analytical needs, data complexity, and performance requirements.
Frequently Asked Questions
When Should You Use a Snowflake Schema In a Data Warehouse?
Use a snowflake schema when your data has complex, hierarchical relationships and you need to minimize storage space and maintain high data integrity, even if it means slightly slower query performance.
How Does Snowflake Schema Improve Data Integrity?
By normalizing dimension tables and eliminating redundancy, the snowflake schema ensures that each piece of information is stored only once, reducing the risk of inconsistencies and making updates easier and more reliable.
What is the Main Drawback of Using a Snowflake Schema?
The primary drawback is increased query complexity and potentially slower performance, as retrieving data often requires multiple joins across several normalized dimension tables. This can impact response times for large or complex queries.
Authors
-

Written by:
Neha SinghReviewed by: