
Summary: I detailed my journey with Pickl.AI, focusing on a personal project involving health insurance cost prediction. The project utilised Google Cloud Platform for model training and bubble.io for deployment, achieving high accuracy.
Introduction
Embarking on a new journey is always scary and fun, but you learn many new things and gain a ton of experience. In this blog, I will explain and summarise my journey working with TransOrg Analytics in the vast domain of machine learning.
I joined them in March 2022 and had the amazing opportunity to learn and get my hands dirty on different models and projects, especially on the Google Cloud Platform.
Read Blogs:
Data Quality in Machine Learning.
Understanding Ridge Regression in Machine Learning.
How it started
During the initial period, we reviewed many core machine learning concepts and approaches that were necessary to create a deeper understanding of the domain’s workings. At the same time, we helped create a data mindset with the ability to view and analyse datasets.
Later, we were introduced to the Google Cloud Platform, often referred to as GCP, and we had a hands-on session with the platform’s workings and various capabilities. To understand the console, we worked on a simple Natural Language Processing-based chatbot based on Auto ML.
This helped me understand how the machine views and processes the queries and performs sentimental analysis to give the right response to the user and point them in the right direction. Playing around on GCP showed me how this process can be more streamlined and made more.
Accurate and robust with different possible changes.
Getting onto the personal project
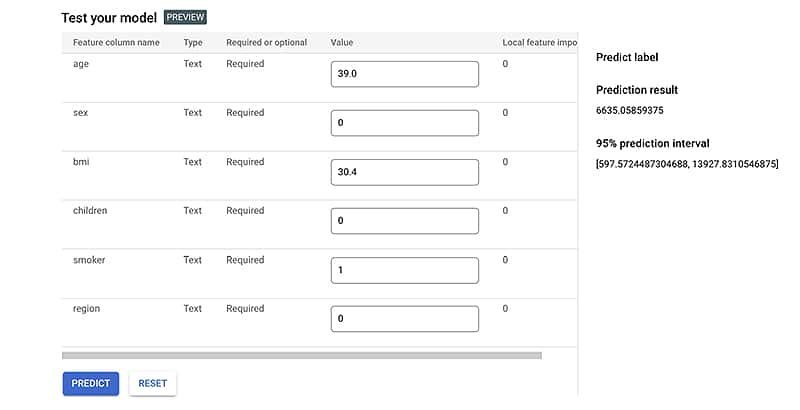
After attaining a good understanding of everything required, I realised that it was time to build a personal project. For this project, I wanted to create something relevant to many users and easy to access and use simultaneously. I started looking at healthcare as a possible application domain relevant to most users.
I came across a dataset that contained an individual’s tax insurance cost based on various factors such as age, sex, BMI, etc. I downloaded this dataset, explored it in Python using multiple tools, and visualised it to better understand the data.
I found some inconsistencies in the data but quickly fixed them and transformed the relevant rows to better suit the linear regression algorithm. The following libraries used for data correction, exploration, visualisation and model fitting:

Explore: Learn about the Probabilistic Model in Machine Learning.
Cleaned Dataset’s Insights

After training the model and some minor tweaks, it consistently performed and gave accurate results. The training data yielded an R-squared value of 0.751505643411174, and I was able to achieve a very close R-squared value of 0.7447273869684077 for the test data, which showed no training bias.

It was now time to shift everything to Google Cloud Platform so it could remotely accessed and run on the cloud itself.
The treated dataset was used for this purpose Vertex AI used to train a brand new model that performed. Similarly to the local machine model predicting the cost of health insurance a person should be looking to pay based on various parameters.
With the help of the built-in tools of GCP. The model was further optimised to each a R-squared score of 0.948 for the cloud model, giving very accurate results to the users when deployed.

Now, to make it accessible to everyone, it needed to be deployed on the Internet. I chose to create a Web Application for this purpose using bubble.io, which takes the user information as input, sends it to the linear regression model, which predicts the cost, and sends it back to the web application to be displayed to the user using an API.
Further Check:
Discover Best AI and Machine Learning Courses For Your Career.
Understanding Radial Basis Function In Machine Learning.
Frequently Asked Questions
What was the focus of the author’s project?
The author’s project focused on predicting health insurance costs using a dataset with factors like age and BMI. The project involved data cleaning, visualisation, and model training on the Google Cloud Platform.
How did the author optimise their model for accuracy?
The author trained the model on the Google Cloud Platform using Vertex AI, optimising it to achieve an R-squared score of 0.948. This improved the model’s accuracy in predicting health insurance costs.
What platform did the author use to deploy their web application?
The author used bubble.io to create and deploy a web application. This app takes user input, predicts insurance costs via a linear regression model, and displays results through an API.
Conclusion
My journey with Pickl.AI has been both challenging and rewarding. From mastering core machine learning concepts to deploying a successful health insurance prediction model on the Google Cloud Platform, I’ve gained valuable experience. This project highlights the practical application of machine learning and cloud technologies, showcasing their potential in real-world scenarios.
Authors
-

Written by:
Shreyansh KumarReviewed by:



