Summary: Information Retrieval (IR) in NLP helps systems efficiently fetch relevant data using indexing, ranking algorithms, and contextual understanding. It powers search engines, chatbots, and recommendation systems, enhancing user experience with accurate and timely results. Modern IR systems continuously adapt using feedback and machine learning for improved precision and personalisation.
Introduction
Information Retrieval in NLP helps computers find the correct information from vast amounts of data. It works behind search engines, chatbots, and recommendation systems, ensuring users get relevant answers quickly.
Instead of matching keywords, it understands meaning, context, and user intent. This guide explains how these systems work, from organising data to ranking results based on relevance.
You’ll also learn how they improve over time using feedback and advanced techniques. Whether you’re curious about how Google finds answers or how Netflix suggests movies, this guide simplifies the key concepts of Information Retrieval in NLP.
What is an Information Retrieval System?
An Information Retrieval (IR) system is a software-based framework designed to efficiently and effectively retrieve relevant information from a collection of data or documents in response to user queries.
These systems are integral to various applications, such as search engines, recommendation systems, document management systems, and chatbots. The primary goal of an IR system is to bridge the gap between the user’s information needs and the available data by providing timely and accurate results.
Unlike simple keyword-based searches, modern IR systems employ advanced techniques from Natural Language Processing (NLP), machine learning, and data mining to understand user intent, context, and the semantics of queries and documents. This enables them to retrieve documents that match the exact keyword and answer the user’s query.
Critical features of the IR System
Understanding the critical features of an IR system is essential for effective data searching, retrieval accuracy, and relevance ranking. Knowledge in this area enhances system usability, improves user experience, and supports efficient decision-making, making it a vital skill for professionals in data-driven fields.
- Indexing: It creates an organised structure that maps terms (words or phrases) to the documents in which they appear. This structure allows for efficient lookup and retrieval of records based on specific terms.
- Query Processing: The system analyses and processes user queries to identify the most relevant terms and concepts. This often involves techniques to handle synonymy (different words with the same meaning) and polysemy (a word with multiple meanings).
- Relevance Ranking: Documents retrieved from the index are ranked based on their perceived relevance to the user’s query. Various ranking algorithms, such as TF-IDF (Term Frequency-Inverse Document Frequency) and BM25, are used to determine the order in which documents are presented to the user.
- User Interaction and Feedback: Some IR systems learn from user interactions to improve their performance over time. For instance, if a user clicks on a particular search result, the system might know that similar results are likely relevant.
- Information Presentation: The retrieved documents are typically presented to the user with additional information, such as document snippets, titles, and links, to help users quickly assess the relevance of each result.
- Query Expansion: This technique automatically enhances user queries with additional terms related to the original query. Accounting for different ways of expressing ideas can help retrieve more relevant results.
- Evaluation Metrics: IR systems are often evaluated using precision, recall, and F1-score metrics, which measure how accurately the system retrieves relevant documents and avoids irrelevant ones.
- Scalability: Given today’s vast data, modern IR systems must be scalable to handle large datasets efficiently.
Objectives of Information Retrieval System

The objectives of the IR system are centred around providing efficient and accurate access to relevant information from a vast collection of data or documents. These objectives go beyond simple keyword matching and focus on enhancing the user’s experience by delivering meaningful and contextually appropriate results. The primary goals of an IR system include:
Relevance
The foremost objective of an IR system is to retrieve information directly relevant to the user’s query. This means the system should consider exact keyword matches, understand the user’s intent, and provide documents that address the user’s information needs.
Relevance ensures that users receive the most pertinent information, which enhances their overall satisfaction. By focusing on relevance, IR systems can significantly improve the quality of the search results, making it easier for users to find the information they need quickly and efficiently.
Efficiency
IR systems aim to retrieve relevant documents quickly, even from large datasets. Speed and efficiency are critical to providing a satisfactory user experience, especially when users expect rapid responses to their queries.
An efficient IR system processes vast amounts of data in real time, ensuring users do not experience delays. This efficiency is achieved through advanced algorithms and optimised data structures that enable the system to search and retrieve information rapidly, enhancing the overall user experience.
Ranking
Once relevant documents are retrieved, the IR system ranks relevant documents in order of perceived relevance. This ranking helps users prioritise their focus on the most relevant documents and saves them time by not having to sift through irrelevant results.
Users can quickly find what they seek by presenting the most pertinent information. Ranking involves sophisticated algorithms that consider keyword frequency, document popularity, and user preferences, ensuring that the most helpful information appears at the top of the search results.
Accuracy
IR systems strive to minimise false positives (irrelevant documents retrieved) and false negatives (relevant documents not retrieved). Accurate retrieval ensures that users receive trustworthy and appropriate information.
An accurate IR system meticulously evaluates the relevance of documents, reducing the chances of irrelevant details appearing in the search results. This accuracy is crucial for maintaining the credibility and reliability of the IR system, as users depend on it to provide precise and valuable information.
Contextual Understanding
Beyond literal keyword matching, IR systems aim to comprehend the context and semantics of both user queries and document content. This allows the system to provide results that align with the user’s intended meaning.
Contextual understanding involves analysing the relationships between words and phrases within the query and documents, ensuring the search results are relevant and contextually appropriate. This deep understanding of language nuances significantly enhances the accuracy and relevance of the information retrieved.
User Interaction
Many modern IR systems incorporate user interactions and feedback to improve future retrieval results. By learning from user behaviour and preferences, the system becomes better at refining its results over time.
User interaction allows the IR system to adapt to individual user needs, making the search process more personalised and effective. Feedback mechanisms such as clicks, ratings, and comments provide valuable insights into user preferences, enabling the system to improve and continuously deliver more accurate and relevant search results.
Personalisation
In some cases, IR systems personalise results based on user profiles, preferences, and historical interactions. This ensures that users receive information most relevant to their needs. Personalisation involves tailoring the search results to match each user’s unique interests and requirements.
By considering factors such as search history, demographic information, and individual preferences, the IR system can deliver a more customised and satisfying search experience, increasing user engagement and satisfaction.
Diversity of Results
While relevance is crucial, IR systems also aim to provide diverse results. This prevents the system from returning multiple highly similar documents and instead offers a well-rounded view of the topic.
Diversity ensures that users are exposed to various perspectives and information sources, enriching their understanding of the subject matter. By incorporating diverse results, the IR system can cater to user needs and preferences, providing a more comprehensive and balanced search experience.
Adaptability
IR systems need to adapt to changes in data and user behaviour. As new documents are added and user preferences evolve, the system should continue to provide accurate and relevant results.
Adaptability involves continuously updating the system’s algorithms and data structures to accommodate new information and changing user behaviours. This ensures that the IR system remains effective and reliable over time, consistently delivering high-quality search results regardless of the dynamic nature of the data and user expectations.
Supporting Complex Queries
The system should handle complex queries involving multiple concepts, logical operators, and facets. It should understand and interpret these queries accurately to provide meaningful results. Supporting complex queries requires sophisticated algorithms capable of parsing and processing intricate search expressions.
By accurately interpreting and addressing complex queries, the IR system can meet users’ diverse and specific information needs, ensuring that even the most detailed and nuanced queries yield accurate and relevant results. This capability enhances the system’s utility and versatility, making it a valuable tool for users with varied and complex search requirements.
Process of Information Retrieval
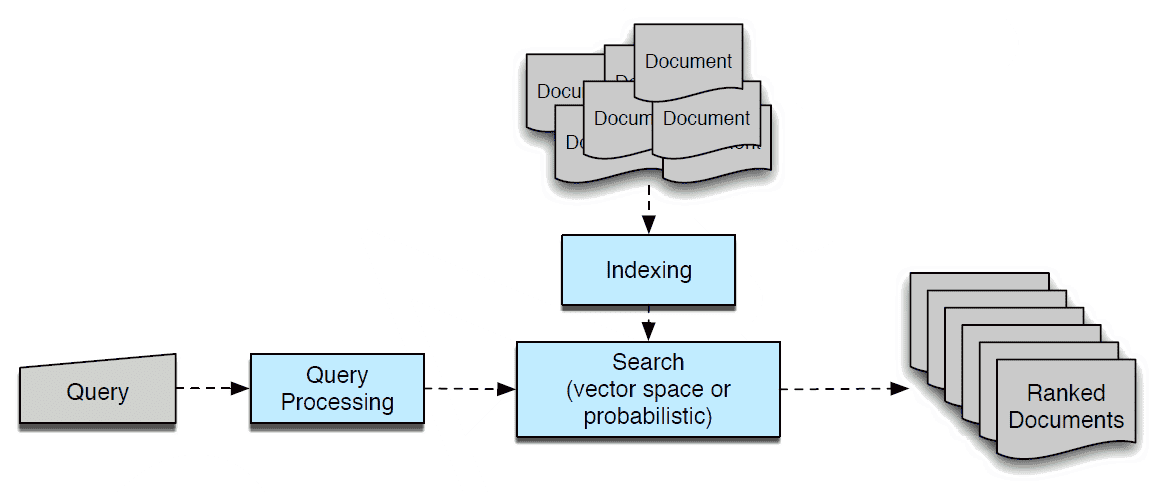
The Information Retrieval (IR) process involves a series of steps that collectively aim to retrieve relevant information from a collection of data or documents based on user queries. This process goes beyond simple keyword matching and employs various techniques to understand user intent, index documents, and rank their relevance.
Here’s a step-by-step breakdown of the typical information retrieval process:
Data Collection and Preprocessing
First, we gather documents or data on how the IR system will operate. This initial step involves collecting vast amounts of raw data from various sources, such as databases, web pages, or text documents.
After gathering the data, we preprocess it by cleaning and tokenising it, breaking it into individual words or phrases. This step also involves removing unnecessary elements like stopwords (common words like “the” or “and”) and punctuation.
Optionally, we apply techniques like stemming or lemmatisation to reduce words to their root forms, ensuring consistency and improving search accuracy.
Indexing
In the indexing phase, we create a data structure that maps terms (words or phrases) to the documents they appear. This index allows for efficient lookup and retrieval of documents containing specific terms. We can facilitate fast and accurate retrieval by using data structures like inverted indexes.
The inverted index is particularly effective because it stores a list of documents for each term, making it quick to find all documents containing a particular word or phrase. This step ensures the IR system can quickly and accurately respond to user queries.
Query Processing
When a user submits a query, the system processes it to identify relevant terms and concepts. This step involves analysing the query to understand the user’s intent and determine the most important words or phrases. We also handle query expansion, adding additional terms related to the user’s query to enhance retrieval accuracy.
For example, if a user searches for “cars,” we might also consider related terms like “automobiles” or “vehicles.” Additionally, we address synonymy (different words with similar meanings) and polysemy (words with multiple meanings) to ensure we capture the user’s intended meaning.
Relevance Ranking
After identifying the relevant documents, we calculate a relevance score for each document using ranking algorithms such as TF-IDF (Term Frequency-Inverse Document Frequency) or BM25. These algorithms consider various factors, such as the frequency of query terms in the document and the overall importance of the terms.
Documents with higher relevance scores are ranked higher and presented to the user first. This ranking process ensures that the most pertinent and useful documents appear at the top of the search results, enhancing the user’s search experience.
Presentation of Results
We then display the retrieved documents to the user in a user-friendly format. This presentation typically includes document titles, text snippets matching the query, and links to the full documents.
Additional information, such as publication dates, authors, and metadata, helps users assess the relevance of each result. By providing a clear and informative presentation, we help users quickly determine which documents will most likely meet their needs and encourage further exploration of the search results.
User Interaction and Feedback
User interaction with the presented results provides valuable feedback for improving the IR system. By observing user actions, such as clicks and the amount of time spent on each document, we gather insights into the relevance of the retrieved documents.
This feedback loop allows us to refine the ranking algorithms and improve future retrieval results. Incorporating user feedback is essential for adapting to users’ changing needs and preferences, ensuring the IR system remains practical and relevant over time.
Iterative Querying
Users often refine their queries based on the initial results. They may modify keywords, add filters, or change their search terms to narrow their search and improve the relevance of the retrieved documents.
Each iteration helps the user get closer to finding the information they need. This iterative querying process is a critical component of the IR system, as it allows users to explore different aspects of their search topic and progressively improve their search results.
Continuous Learning and Adaptation
Finally, the IR system must continuously learn and adapt to remain effective. We update the index and ranking algorithms as new documents are added to the collection. We also adapt to changes in user behaviour and preferences, ensuring the system remains accurate and relevant.
By continuously learning from user interactions and updating the system accordingly, we can maintain high-quality search results and provide a better user experience.
The Information Retrieval process is dynamic and multifaceted. It aims to provide users with the most relevant information efficiently. Following these steps, IR systems can effectively meet user needs and adapt to the ever-changing information landscape.
Information Retrieval Example
Imagine you are searching for “best budget smartphones.” An Information Retrieval (IR) system processes this query by identifying documents that contain the keywords “best,” “budget,” and “smartphones.” It doesn’t stop there; the system goes further to understand the context and nuances of the search.
The IR system evaluates the relevance of the documents, ensuring that the articles it retrieves discuss affordable smartphones with good features. This means it looks for content where the term “budget” is associated with “smartphones;” these devices are rated highly for their value.
Additionally, the IR system considers the user’s intent behind the search. It understands the user wants to find the best options within a specific price range. As a result, it prioritises articles that compare different budget smartphones, reviews that highlight their features, and lists that recommend top choices.
The IR system ensures a more satisfying and accurate search experience by aligning the search results with the user’s intent. This example demonstrates how IR systems go beyond simple keyword matching, employing sophisticated algorithms to deliver relevant and helpful information tailored to the user’s needs.
Information Retrieval and Information Extraction in AI

Information Retrieval (IR) and Information Extraction (IE) are two fundamental pillars of AI’s language understanding capabilities. IR focuses on fetching relevant information from vast datasets. When users enter a query, IR systems scan large data collections, such as documents, databases, and websites, to find the most pertinent information.
This process involves indexing, ranking, and retrieving documents based on their relevance to the query. Effective IR systems, like search engines, ensure users receive accurate and helpful information quickly, enhancing their ability to find what they need from extensive data sources.
In contrast, Information Extraction identifies and extracts structured information from unstructured text. IE systems analyse text to identify specific pieces of information, such as names, dates, locations, and relationships. This structured data can then be organised into databases or knowledge graphs, significantly contributing to AI’s knowledge base.
For instance, an IE system might process news articles to extract data about events, people involved, and their connections, transforming raw text into actionable insights. This capability is crucial for automated summarisation, question answering, and content recommendation tasks.
Together, IR and IE enable AI systems to understand and utilise human language more effectively, driving advancements in natural language processing and contributing to the development of intelligent applications.
Wrapping It Up
Information Retrieval (IR) in NLP is essential for efficiently retrieving relevant information from vast datasets. It powers search engines, chatbots, and recommendation systems by understanding user intent, context, and semantics.
Modern IR systems leverage indexing, query processing, ranking algorithms, and user feedback to improve accuracy and relevance. They continuously adapt to evolving data and user behaviour, ensuring precise and personalised results.
By integrating advanced techniques such as machine learning and contextual understanding, IR systems enhance the search experience, streamline information access, and drive innovations in AI-driven applications, making them indispensable in today’s data-driven digital landscape.
Are you eager to dive into the world of Data Science and AI? Explore our courses at Pickl.AI and embark on a journey to master the technologies shaping the future.
Frequently Asked Questions
What is Information Retrieval in NLP?
Information Retrieval (IR) in NLP is retrieving relevant information from vast datasets using advanced techniques like natural language understanding, indexing, and ranking algorithms. It powers search engines, chatbots, and recommendation systems by understanding user intent and ensuring precise and efficient search results.
How does Information Retrieval Differ from Information Extraction?
Information Retrieval (IR) fetches relevant documents based on user queries, while Information Extraction (IE) identifies and structures specific details from text, such as names or dates. IR focuses on retrieving complete documents, while IE extracts meaningful data from unstructured text for better analysis and knowledge representation.
Why is Relevance Ranking Important in Information Retrieval?
Relevance ranking determines the order in which search results appear based on user queries. Algorithms like TF-IDF and BM25 prioritise documents based on keyword importance, user intent, and contextual meaning. Effective ranking improves search accuracy, ensuring users receive the most useful and relevant results quickly.
Authors
-

Written by:
Versha RawatReviewed by: