In the world of Machine Learning and Data Analysis, decision trees have emerged as powerful tools for making complex decisions and predictions. These tree-like structures break down a problem into smaller, manageable parts, enabling us to make informed choices based on data. One critical aspect of using it is how decision trees handle missing values, ensuring the accuracy and reliability of the model. In this article, we’ll delve into the process of how decision trees handle missing values, examining both their advantages and disadvantages.
What is a Decision Tree?
Decision trees are a visual representation of decision-making processes. They mimic human decision-making by breaking down a problem into a series of binary choices. Each internal node represents a decision or a test on an attribute, and each branch corresponds to an outcome of that test. Decision trees are widely used for classification and regression tasks due to their simplicity and interpretability.
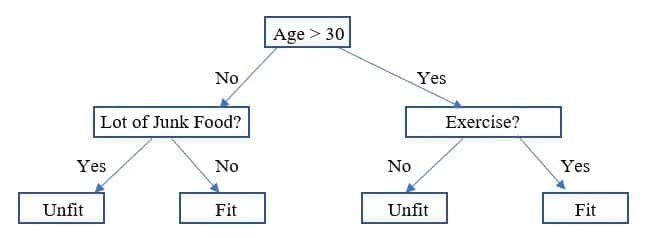
Advantages of Decision Trees
- Interpretability: Decision trees are easy to understand and interpret, making them a valuable tool for both beginners and experts in the field of machine learning.
- Handle Non-Linearity: Decision trees can handle non-linear relationships between features, which many other algorithms struggle with.
- Feature Importance: Decision trees allow us to identify the most important features that contribute to the decision-making process.
- Robust to Outliers: Decision trees are robust to outliers and can still make accurate predictions even in the presence of extreme values.
Disadvantages of Decision Trees
- Overfitting: Decision trees are prone to overfitting, especially when the tree is deep and complex. This can lead to poor generalization on unseen data.
- Instability: A small change in the data can lead to a completely different tree structure, making decision trees unstable.
- Limited Expressiveness: Decision trees may struggle to capture complex relationships in the data, leading to underperformance in certain scenarios.
- High Variance: Small variations in the data can result in significantly different decision trees, contributing to high variance.
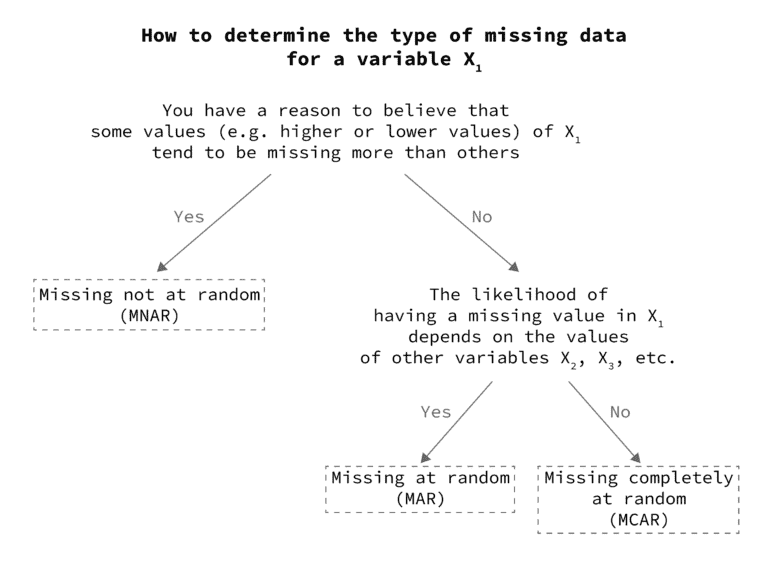
How Decision Trees Handle Missing Values
Handling missing values is a crucial step in data preprocessing to ensure the accuracy of Machine Learning models. Decision trees have a natural way of dealing with missing values during the tree-building process:

A step-by-step explanation of how decision trees handle missing values:
Step 1: Attribute Splitting
When building a decision tree, the algorithm starts by selecting the attribute that best separates the data based on a chosen criterion, such as Gini impurity or entropy. If a data point has a missing value for the selected attribute, the decision tree algorithm will consider the available data to make the split.
Step 2: Weighted Impurity Calculation
Decision tree algorithms calculate impurity measures like Gini impurity or entropy to evaluate the quality of a split. In the presence of missing values, the algorithm adjusts the impurity calculation by considering the weights of the instances. This means that instances with missing values are given a weight that reflects their proportion in the dataset, ensuring that the impurity calculation accounts for their contribution.
Step 3: Surrogate Splits
To handle missing values effectively, decision trees use surrogate splits. These surrogate splits act as backup choices when the primary attribute for a split has missing values. The algorithm identifies the next best attribute that can provide a similar separation as the primary attribute. This allows the tree to make accurate predictions even when the primary attribute is missing.
Here’s a simple example to illustrate the process:
Suppose we’re building a decision tree to predict whether a flight will be delayed based on attributes like weather, time of day, and airline. If the “weather” attribute is missing for some flights, the algorithm will:
- Choose the best attribute (e.g., time of day) for the initial split.
- Calculate impurity (Gini impurity or entropy) while considering weights of instances with missing “weather” values.
- Identify surrogate splits (e.g., airline) to handle missing “weather” values in subsequent nodes.
By following these steps, decision trees can effectively handle missing values while making decisions and predictions.
Decision Tree Missing Values in Python
In Python, decision tree algorithms, such as those provided by the sci-kit-learn library, have built-in mechanisms to handle missing values during the tree-building process. Here’s how it works:
Data Preparation
Start by importing the necessary libraries and loading your dataset. Ensure that your dataset contains missing values in some of the attributes.
Handling Missing Values
Decision tree algorithms in sci-kit-learn handle missing values automatically during the tree-building process. You don’t need to perform any explicit preprocessing for missing values.
Building the Decision Tree
Create an instance of the DecisionTreeClassifier (or DecisionTreeRegressor for regression tasks) and fit it to your training data.
Making Predictions
Once the decision tree is trained, you can use it to make predictions on new data (including data with missing values).
The key takeaway is that decision trees handle missing values naturally by making splits based on the available data. The algorithm calculates impurity measures while considering instance weights, which helps in accommodating missing values. Additionally, surrogate splits are automatically considered during the tree-building process, ensuring accurate predictions even when certain attributes have missing values.
Read the Blog: How Business Intelligence Helps in Decision Making
 Conclusion
Conclusion
In conclusion, decision trees are powerful tools in the realm of Machine Learning, offering a transparent and understandable way to make predictions and decisions. Despite their drawbacks, decision trees can effectively handle missing values through attribute splitting, weighted impurity, and surrogate splits. Understanding how decision trees handle missing values is essential for building accurate and reliable models that can be applied to various domains.
FAQs
A decision tree is a graphical representation of decision-making processes that break down a problem into smaller, manageable parts.
Why are Decision Trees Prone to Overfitting?
Decision trees can become overly complex, fitting the training data too closely and failing to generalize well to new data.
How do Decision Trees Handle Missing Values?
Decision trees handle missing values through attribute splitting, weighted impurity calculations, and surrogate splits.
Are Decision Trees Suitable for Handling Non-linear Relationships?
Yes, decision trees can effectively handle non-linear relationships between features.
What is The Main Advantage of Decision Trees?
The main advantage of decision trees is their interpretability, allowing users to understand and explain the decision-making process easily.
Author
-

Written by:
Aishwarya Kurre



