
Summary: The confusion matrix in Machine Learning is a powerful tool for evaluating classification models. It breaks down predictions into true positives, true negatives, false positives, and false negatives, offering valuable insights into model performance. Derived metrics like accuracy and precision guide model improvement, making the confusion matrix essential in Machine Learning.
Introduction
In Machine Learning, evaluating model performance is crucial for developing effective algorithms. This evaluation often hinges on understanding various metrics, with the confusion matrix being a fundamental tool. A confusion matrix in Machine Learning provides a detailed breakdown of how well a model predicts each class, highlighting areas of success and failure.
This blog aims to introduce the concept of the confusion matrix, explain its components, and demonstrate how it aids in assessing model accuracy and effectiveness. By mastering the confusion matrix, you will gain valuable insights into model performance and improve your Machine Learning projects.
What is a Confusion Matrix in Machine Learning?
A confusion matrix is a fundamental tool in Machine Learning for evaluating the performance of classification models. It provides a detailed breakdown of how well a model’s predictions align with actual outcomes.
Specifically, it displays the counts of true positive, true negative, false positive, and false negative predictions, offering insight into the model’s accuracy and error types.
Visualisation of a Confusion Matrix
Typically, the confusion matrix appears as a 2×2 grid for binary classification problems. Each cell in the grid represents the count of predictions made by the model. For instance, the top-left cell shows TP, while the bottom-right cell shows TN.
The top-right and bottom-left cells represent FP and FN, respectively. This matrix allows quick visualisation of how many predictions were correct versus incorrect and helps diagnose specific model issues.
Components of the Confusion Matrix
Understanding the components of a confusion matrix is crucial for evaluating the performance of a classification model. The confusion matrix breaks down the predictions made by the model into four distinct categories. These categories are True Positives, False Positives, True Negatives, and False Negatives.
True Positives (TP)
True Positives (TP) represent the number of instances where the model correctly predicted the positive class. In other words, these are the cases where the actual class was positive, and the model also predicted it as positive.
For example, in a medical test for a disease, a True Positive would be a case where the test correctly identifies a patient as having the disease when they indeed have it. TP is an indicator of the model’s ability to correctly identify positive cases.
False Positives (FP)
False Positives (FP) occur when the model incorrectly predicts the positive class for an instance that is actually negative. This means the model’s prediction is positive, but the true class is negative.
Continuing with the medical test example, a False Positive would be a test result that incorrectly identifies a healthy person as having the disease. FP highlights the model’s tendency to make incorrect positive predictions, which can be particularly problematic in scenarios where false positives are costly or undesirable.
True Negatives (TN)
True Negatives (TN) are instances where the model correctly predicts the negative class. Here, both the actual class and the model’s prediction match, indicating a correct identification of the negative cases.
In the medical test scenario, a True Negative would be a correct result showing that a healthy individual is accurately identified as not having the disease. TN helps in understanding how well the model is at identifying the negative class and contributes to assessing overall model performance.
False Negatives (FN)
False Negatives (FN) occur when the model incorrectly predicts the negative class for an instance that is actually positive. This means the model fails to recognise a positive case and instead classifies it as negative.
In our example, a False Negative would be a result where a person who actually has the disease is wrongly identified as healthy. FN points to the model’s shortcomings in detecting positive instances and is crucial for evaluating the model’s sensitivity and ability to avoid missing positive cases.
Each component of the confusion matrix plays a vital role in understanding and improving the performance of a classification model. By analysing True Positives, False Positives, True Negatives, and False Negatives, you can gain a clearer picture of how well your model performs and where adjustments may be needed.
How to Construct a Confusion Matrix
Constructing a confusion matrix is a crucial step in evaluating the performance of a Machine Learning model. It allows you to visualise the classification outcomes by comparing the actual and predicted labels.
In this section, we’ll walk you through a step-by-step process to create a confusion matrix, provide an example using a simple binary classification problem, and demonstrate how to generate a confusion matrix using Python‘s scikit-learn library.
Step-by-Step Process
- Identify Actual and Predicted Labels
Begin by obtaining the actual labels (ground truth) and the predicted labels from your model. These labels are essential to build the confusion matrix, as they will help you determine the accuracy of the model’s predictions. - Create the Confusion Matrix Structure
The confusion matrix is a table with two dimensions: one representing the actual labels and the other representing the predicted labels. For a binary classification problem, this matrix will have four cells, each corresponding to one of the following outcomes: True Positive (TP), False Positive (FP), True Negative (TN), and False Negative (FN). - Populate the Confusion Matrix
Populate the cells of the confusion matrix by counting the number of instances that fall into each category:- True Positives (TP): The number of correct positive predictions.
- False Positives (FP): The number of incorrect positive predictions.
- True Negatives (TN): The number of correct negative predictions.
- False Negatives (FN): The number of incorrect negative predictions.
Explore: Scikit-Learn Cheat Sheet: A Comprehensive Guide.
Example with a Simple Binary Classification Problem
Consider a scenario where you have trained a model to classify whether an email is spam or not. You tested the model on 10 emails, and the actual and predicted labels are as follows:
- Actual Labels: [Spam, Not Spam, Spam, Spam, Not Spam, Not Spam, Spam, Not Spam, Spam, Not Spam]
- Predicted Labels: [Spam, Not Spam, Not Spam, Spam, Not Spam, Spam, Spam, Not Spam, Spam, Not Spam]
Using these labels, you can construct the confusion matrix:
- True Positives (TP): 4 (Emails correctly predicted as Spam)
- False Positives (FP): 1 (Emails incorrectly predicted as Spam)
- True Negatives (TN): 4 (Emails correctly predicted as Not Spam)
- False Negatives (FN): 1 (Emails incorrectly predicted as Not Spam)
The resulting confusion matrix will look like this:
| Predicted Spam | Predicted Not Spam | |
| Actual Spam | 4 | 1 |
| Actual Not Spam | 1 | 4 |
Code Snippet for Creating a Confusion Matrix Using Python
You can easily create a confusion matrix using Python’s scikit-learn library. Here’s a code snippet to do this:
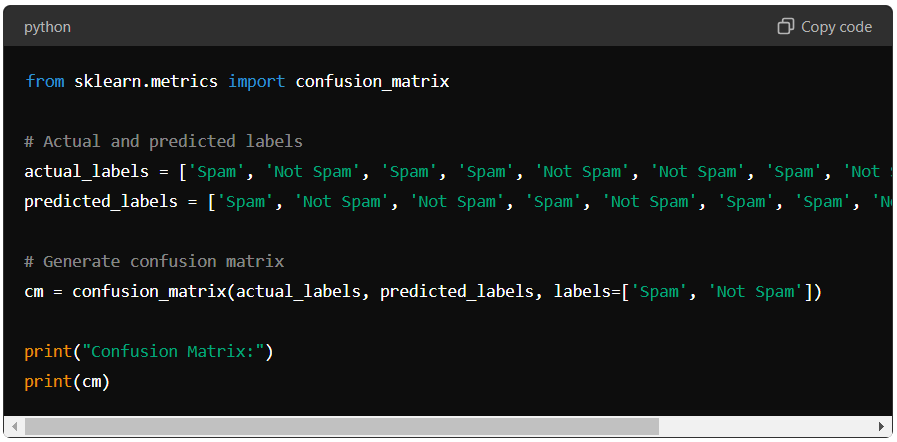
This code will generate the confusion matrix for the provided labels, helping you evaluate your model’s performance effectively.
Read Blogs:
Importance of Python Programming: Real-Time Applications.
Types of Programming Paradigms in Python You Should Know.
Performance Metrics Derived from the Confusion Matrix
A confusion matrix provides a powerful tool for evaluating the performance of Machine Learning models, especially in classification tasks. Let’s explore the essential metrics derived from the confusion matrix: Accuracy, Precision, Recall (Sensitivity), F1 Score, and Specificity. Each metric provides a unique perspective on the model’s effectiveness.
Accuracy
Accuracy is the most straightforward metric derived from the confusion matrix. It measures the proportion of correctly classified instances (both positives and negatives) out of the total instances. In other words, it tells you how often the model is correct overall.
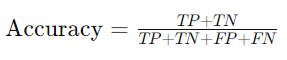
While accuracy is useful, it can be misleading in cases where the classes are imbalanced. For instance, if 95% of your data belongs to one class, a model that predicts only that class will still have high accuracy, despite failing to identify the minority class. Therefore, accuracy should be used cautiously and in conjunction with other metrics.
Precision
Precision, also known as Positive Predictive Value (PPV), focuses on the model’s performance in predicting positive cases. It answers the question: “Of all the instances predicted as positive, how many were actually positive?”
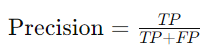
High precision indicates a low rate of false positives, meaning the model is not often wrong when predicting positive outcomes. Precision is particularly important in scenarios where the cost of false positives is high, such as in spam detection or disease diagnosis.
Recall (Sensitivity)
Recall, or Sensitivity, measures the model’s ability to identify all actual positive instances. It answers the question: “Of all the actual positive cases, how many did the model correctly identify?”
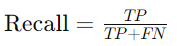
High recall indicates that the model is effective at capturing most of the positive instances, which is crucial in situations where missing a positive case could have severe consequences, such as in medical diagnoses.
F1 Score
The F1 Score combines Precision and Recall into a single metric, providing a balance between the two. It is the harmonic mean of Precision and Recall, offering a more comprehensive evaluation, especially when there is an uneven class distribution.
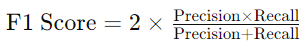
A high F1 Score indicates that the model maintains a good balance between Precision and Recall, making it a preferred metric in cases where both false positives and false negatives are critical.
Specificity
Specificity, or True Negative Rate (TNR), measures the model’s ability to correctly identify negative instances. It answers the question: “Of all the actual negative cases, how many did the model correctly identify?”
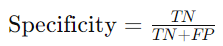
High specificity is essential in scenarios where false positives can lead to significant issues, such as in fraud detection or security systems.
Each of these metrics plays a vital role in understanding and improving the performance of Machine Learning models. By carefully analysing them, you can gain insights into your model’s strengths and weaknesses, leading to more informed decisions and better model performance.
Applications and Use Cases
The confusion matrix is a powerful tool in Machine Learning, widely used to evaluate the performance of classification models. It finds applications across various domains, providing insights that help refine and improve model accuracy.
Examples of Confusion Matrix Applications
In medical diagnostics, confusion matrices are crucial for evaluating models that predict the presence or absence of diseases. For instance, in cancer detection, the matrix helps distinguish between true positives (correctly identified cases) and false negatives (missed cases). This aids in understanding the reliability of the model and its potential risks in a clinical setting.
In spam detection, confusion matrices are used to evaluate email classification systems. By analysing the true positives (correctly identified spam) and false positives (legitimate emails incorrectly marked as spam), developers can fine-tune algorithms to minimise errors and improve user experience.
How Confusion Matrices Help in Model Selection and Tuning
Confusion matrices play a significant role in model selection by enabling a detailed comparison of different models. By examining metrics such as accuracy, precision, and recall, derived from the confusion matrix, you can identify the model that best suits your specific needs.
In model tuning, confusion matrices help you adjust parameters to optimise performance. By observing changes in the matrix as you tweak your model, you can ensure it performs well across various scenarios, leading to a more robust and reliable system.
Limitations of the Confusion Matrix
While the confusion matrix is a powerful tool for evaluating Machine Learning models, it has certain limitations that can make it less informative in specific scenarios. Understanding these limitations is crucial for accurate model evaluation and decision-making.
One significant limitation of the confusion matrix is its reduced effectiveness in multiclass classification problems. In binary classification, the confusion matrix clearly displays the relationship between true positives, false positives, true negatives, and false negatives.
However, when dealing with multiple classes, the matrix becomes more complex and harder to interpret. Each class requires its own row and column, leading to a larger matrix that may not easily reveal the model’s performance nuances.
Additionally, the confusion matrix provides no insight into the costs or importance of different types of errors. In some applications, such as medical diagnostics, a false negative might be more critical than a false positive. The confusion matrix treats all errors equally, which can be misleading in contexts where the cost of different errors varies.
Scenarios where confusion matrices might be less informative:
- Imbalanced datasets: The confusion matrix can give a skewed impression of model performance when one class significantly outweighs the others.
- Multiclass classification: Interpretation becomes challenging due to the complexity of the matrix structure.
Limitations in multiclass classification problems:
- Complexity: More classes lead to a larger and more difficult-to-interpret matrix.
- Misclassification understanding: It becomes harder to discern where the model is making specific errors.
Conclusion
The confusion matrix is an essential tool in Machine Learning for evaluating classification models. By breaking down predictions into true positives, true negatives, false positives, and false negatives, it provides a clear picture of the model’s performance. This detailed analysis helps identify areas where the model excels and where it needs improvement.
Additionally, derived metrics like accuracy, precision, and recall offer further insights, guiding model selection and tuning. Although it has limitations in multiclass and imbalanced datasets, the confusion matrix remains a fundamental component for developing robust and reliable Machine Learning models.
Frequently Asked Questions
What is a Confusion Matrix in Machine Learning?
A confusion matrix in Machine Learning is a tool used to evaluate the performance of classification models. It provides a detailed breakdown of predictions, showing the counts of true positives, true negatives, false positives, and false negatives. This matrix helps in understanding the model’s accuracy and error distribution.
Why is a Confusion Matrix important in Machine Learning?
A confusion matrix is crucial in Machine Learning because it provides a comprehensive evaluation of a model’s performance. It highlights the model’s strengths and weaknesses by displaying the counts of correct and incorrect predictions, helping data scientists refine models, reduce errors, and make informed decisions on model improvements.
How Do You Interpret the Components of a Confusion Matrix?
To interpret a confusion matrix, focus on its four components: True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN). TP and TN represent correct predictions, while FP and FN indicate errors. Analysing these components provides insights into a model’s precision, recall, and overall effectiveness.
Authors
-

Written by:
Sam WaterstonReviewed by:



