
Summary: Activation function in Deep Learning introduce non-linearity, enabling networks to solve complex problems like image recognition. Popular functions include Sigmoid, ReLU, and Softmax, each serving different tasks effectively.
Introduction
Deep Learning, a subset of Artificial Intelligence (AI), is revolutionising industries by enabling machines to learn from large datasets and improve over time. It plays a pivotal role in image recognition, Natural Language Processing, and autonomous systems.
The activation function is a crucial component in Deep Learning models, which helps introduce non-linearity and allows networks to model complex patterns.
This blog explores the significance of activation functions, how they work, and the latest advancements. With the global Deep Learning market projected to grow from USD 24.53 billion in 2024 to USD 298.38 billion by 2032, understanding activation functions is essential for optimising neural network performance.
Key Takeaways
- Activation functions introduce non-linearity, which is crucial for complex data modelling.
- ReLU and its variants address issues like vanishing gradients and training efficiency.
- Softmax is ideal for multi-class classification tasks.
- Tanh is zero-centered, improving learning efficiency.
- Modern functions like Swish and GELU enhance convergence and model performance.
What is an Activation Function?
An activation function in Deep Learning is a mathematical operation applied to a neuron’s output in a neural network. It determines whether the neuron should be activated based on its input.
The primary purpose of an activation function is to introduce non-linearity into the model. Without it, a neural network would essentially be a linear regression model, regardless of the number of layers.
Role in Introducing Non-linearity
Non-linearity is essential in Deep Learning because it enables the network to learn complex patterns and relationships within the data. Real-world data often exhibits non-linear relationships, and the activation function helps the model capture these patterns.
Without a non-linear activation function, neural networks would fail to differentiate between tasks that require more complex decision boundaries, like image recognition or natural language processing.
The activation function helps the model make decisions based on the learned features, turning the linear output from a weighted sum of inputs into a non-linear value. This allows Deep Learning models to approximate any complex function, making them more powerful and capable of handling diverse tasks.
By introducing non-linearity, activation functions are key to the flexibility and effectiveness of Deep Learning models.
Types of Activation Functions

Activation functions play a crucial role in Deep Learning models by introducing non-linearity into the network. This enables neural networks to learn complex patterns and solve problems that cannot be addressed with linear models alone.
Different activation functions have distinct characteristics and are suited for various tasks in neural networks. Below, we explore the most commonly used activation functions: Sigmoid, Tanh, ReLU, Leaky ReLU, and Softmax.
Sigmoid Activation Function
The Sigmoid function, also known as the logistic function, is one of the oldest and most widely recognised activation functions. It maps any input value to a range between 0 and 1, making it ideal for binary classification tasks. The mathematical expression for the Sigmoid function is:
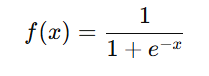
Advantages
- Probabilistic Interpretation: The Sigmoid function outputs values between 0 and 1, which can be interpreted as probabilities, making it useful for binary classification tasks.
- Smooth Gradient: Sigmoid provides a smooth gradient, which helps optimise, especially when applying gradient-based optimisation methods.
- Differentiable: Sigmoid is a smooth and continuous function, which makes it easy to differentiate and use during backpropagation.
Disadvantages
- Vanishing gradients: For very high or very low input values, the gradient of the Sigmoid function becomes very small, leading to the vanishing gradient problem. This can slow down or even halt the learning process.
- Not zero-centered: The Sigmoid function outputs are always positive, which can result in inefficient gradient updates during backpropagation.
- Slow Convergence: The saturation of the Sigmoid function for large input values can result in slower learning, particularly in deep networks.
Tanh (Hyperbolic Tangent) Activation Function
The Tanh function is similar to the Sigmoid function but differs in its output range. It maps input values to a range between -1 and 1. This makes it zero-centred, meaning that the function outputs both positive and negative values, which can improve learning efficiency.
The mathematical expression for the Tanh function is:
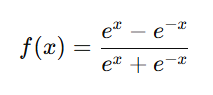
Advantages
- Zero-Centered: Tanh outputs values between -1 and 1, making it zero-centred, improving learning efficiency by allowing for more balanced updates during backpropagation.
- Sharper Gradients: The gradients of Tanh are steeper than those of the Sigmoid function, helping the network converge faster.
- Smooth and Continuous: Like Sigmoid, Tanh is a continuous and differentiable function, facilitating gradient-based optimisation.
Disadvantages
- Vanishing Gradients: Like Sigmoid, Tanh suffers from the vanishing gradient problem for very high or low input values, leading to slow learning in deep networks.
- Computational Cost: Tanh is more computationally expensive than ReLU because it involves exponentials in its computation.
- Saturation for Extreme Inputs: The output values saturate at 1 and -1 for large positive or negative inputs, leading to very small gradients and slow convergence.
ReLU (Rectified Linear Unit) Activation Function
ReLU is one of the most popular activation functions in Deep Learning due to its simplicity and efficiency. It transforms all negative values to zero and keeps all positive values unchanged. The ReLU function is defined as:
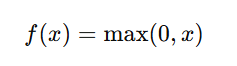
Advantages
- No Vanishing Gradients: ReLU avoids the vanishing gradient problem for positive inputs, allowing the network to train faster and more effectively in deep networks.
- Computational Efficiency: The ReLU function is computationally simple, as it only requires a comparison (is the input positive or negative), resulting in faster training times.
- Sparse Activation: Since ReLU outputs zero for negative inputs, it introduces sparsity in the network, which can help reduce overfitting and make the network more efficient.
Disadvantages
- Dying ReLU Problem: Neurons that output only zeros for negative inputs can “die” and stop learning altogether. This issue arises when the network weights become too negative.
- Non-zero Outputs for Negative Inputs: ReLU has no upper bound on its output, which can result in large values and may cause instability or overflow during training.
- Not Suitable for All Tasks: ReLU is not ideal for tasks where negative values are important or when it needs to model negative correlation, as it always outputs non-negative values.
Leaky ReLU Activation Function
Leaky ReLU is a variation of the standard ReLU function designed to address the dying ReLU problem. Instead of outputting zero for negative values, it allows a small, non-zero gradient. The function is defined as:
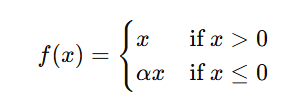
Where α is a small constant (e.g., 0.01).
Advantages
- Prevents Dying ReLU Problem: Leaky ReLU allows a small gradient for negative values, preventing neurons from becoming inactive during training.
- Computational Efficiency: Like ReLU, Leaky ReLU is simple to compute, resulting in faster training times and low computational overhead.
- Improves Gradient Flow: The small, non-zero slope for negative inputs helps maintain gradient flow, making it effective for training deep networks.
Disadvantages
- Choice of Slope (α): The performance of Leaky ReLU heavily depends on the choice of the slope (α) for negative inputs. A small value of α\alphaα can still lead to slow convergence.
- Not Zero-Centered: Like ReLU, Leaky ReLU is not zero-centred, which can lead to inefficient gradient updates and slower convergence.
- Still Can Have Dead Neurons: While Leaky ReLU reduces the problem, it does not eliminate dead neurons. Some neurons may still not contribute meaningfully to the model.
Softmax Activation Function
The Softmax function is primarily used in the output layer of multi-class classification problems. Unlike the other activation functions, which map inputs to a specific range, Softmax normalises the outputs of a neural network into a probability distribution across multiple classes. The function is defined as:
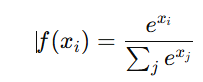
Where xi is the input for class i, and the denominator is the sum of the exponentials of all inputs.
Advantages
- Multi-class Classification: Softmax is designed for multi-class classification problems, converting raw outputs into probability distributions over multiple classes.
- Probabilistic Outputs: The outputs of the Softmax function are probabilities, which are easier to interpret and work well in tasks requiring probability estimates for different classes.
- Differentiability: Softmax is differentiable, allowing for effective backpropagation during the training process, especially when used in the final layer of a neural network.
Disadvantages
- Sensitive to Large Values: Softmax is sensitive to large input values, which can cause numerical instability and overflow. This requires careful normalisation or scaling of inputs.
- Requires Multiple Outputs: Softmax is designed for multi-class classification tasks, making it unsuitable for binary or regression tasks.
- Not Suitable for Hidden Layers: Softmax is generally not used in hidden layers, as it outputs a probability distribution, which does not add much value to intermediate computations in a network.
Characteristics of Good Activation Functions
A well-designed activation function is crucial for a neural network’s effective training and performance. A good activation function enables the network to learn complex patterns and ensure efficient backpropagation during training. The following characteristics define a high-quality activation function:
Non-linearity
Non-linearity is a fundamental property of activation functions. Without non-linearity, neural networks would behave like a linear model, regardless of the number of layers. This would limit their capacity to learn complex patterns in data.
Non-linear activation functions allow neural networks to model intricate relationships and accurately predict tasks like image recognition and natural language processing.
Differentiability
A good activation function must be differentiable to facilitate the optimisation process. During backpropagation, the gradients of the error function concerning the weights need to be computed.
If the activation function is not differentiable, the network won’t be able to update its weights, resulting in poor effective learning. Smooth, continuous differentiability helps ensure proper gradient flow and stable training.
Avoiding Vanishing and Exploding Gradients
A robust activation function should prevent the vanishing and exploding gradient problems. The vanishing gradient problem occurs when gradients become too small, halting learning in deeper layers.
On the other hand, exploding gradients cause excessively large updates to weights, leading to instability. Activation functions like ReLU help mitigate these issues by maintaining gradient flow without allowing values to grow uncontrollably.
Common Issues with Activation Functions

Activation functions are crucial for the performance of neural networks, but they come with certain challenges. Understanding these issues can help choose the right activation function and optimise model training.
Vanishing Gradients
The vanishing gradient problem occurs when the activation function’s gradient (or slope) becomes very small, especially in deep networks. This leads to minor weight updates during training, causing the model to learn slowly or even stop entirely.
Dying ReLU Problem
In the Dying ReLU problem, ReLU activation units output zero for all negative input values. This results in some neurons becoming inactive during training and never contributing to learning.
Recent Advances
Recent advancements in activation functions have introduced new methods like Swish and GELU (Gaussian Error Linear Unit), providing enhanced performance for Deep Learning models. These modern functions aim to address the limitations of older ones, improving both training efficiency and model accuracy.
Swish
Swish is a self-gated activation function, defined as x * sigmoid(x). It allows better gradient flow, helping with the vanishing gradient problem. Studies show that Swish outperforms ReLU on various benchmarks, especially in deeper networks.
GELU
GELU combines ReLU and Gaussian distribution properties, offering smoother non-linearity and faster convergence. It is particularly effective in large-scale transformer models, like GPT-3, enhancing their robustness and performance.
In The End
The activation function in Deep Learning is pivotal for enabling neural networks to model complex patterns. It introduces non-linearity, improving the model’s ability to learn from diverse data. Various functions like Sigmoid, ReLU, and Softmax are key to solving different tasks. Ongoing advancements ensure that these functions continue to optimise Deep Learning model performance.
Frequently Asked Questions
What is the Role of the Activation Function in Deep Learning?
Activation functions introduce non-linearity to Deep Learning models, allowing them to capture complex data patterns. They enable neural networks to perform tasks such as image recognition, natural language processing, and classification by transforming linear outputs into non-linear results.
What are the Common Types of Activation Functions in Deep Learning?
Common activation functions in Deep Learning include Sigmoid, Tanh, ReLU, Leaky ReLU, and Softmax. Each function has specific advantages, such as probabilistic interpretation (Sigmoid) or faster convergence (ReLU), depending on the task and the network architecture.
How does the ReLU Activation Function Improve Deep Learning Models?
ReLU activation improves Deep Learning models by preventing the vanishing gradient problem, ensuring faster training times, and enabling better performance in deeper networks. It transforms all negative values to zero and keeps positive values, promoting sparsity and reducing overfitting.
Authors
-

Written by:
Smith AlexReviewed by:



