
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions. Together, they power data-driven innovation across industries.
Introduction
In today’s hyper-connected world, you hear the terms “Big Data” and “Data Science” thrown around constantly. They pop up in news articles, job descriptions, and tech discussions. While often used together, and sometimes even interchangeably, they represent different concepts.
It can be confusing! What exactly is Big Data? How is it different from Data Science? And why should you even care?
Think of it like this: imagine a massive, sprawling ocean teeming with undiscovered life and hidden currents. Big Data is the ocean itself – vast, deep, constantly moving, and full of diverse things. Data Science is the practice of exploring that ocean – using tools and techniques to navigate, understand the currents, discover the life within, and map its hidden treasures.
Key Takeaways
- Big Data focuses on collecting, storing, and managing massive datasets.
- Data Science extracts insights and builds predictive models from processed data.
- Big Data technologies include Hadoop, Spark, and NoSQL databases.
- Data Science uses Python, R, and machine learning frameworks.
- Both fields are interdependent for effective data-driven decision-making
What is Big Data?
The Ocean of Information
At its heart, Big Data refers to extremely large, complex datasets that are generated at high speed from various sources. Traditional data processing tools and techniques struggle to handle this kind of data effectively.
It’s not just about more data; it’s about data that’s fundamentally different in its scale and nature. To understand Big Data better, experts often describe it using the “Vs”:
Volume (The Sheer Size)
This is the most obvious characteristic. We’re talking about massive quantities of data – terabytes (TBs), petabytes (PBs), even exabytes (EBs) and beyond.
Simple Example: Think about all the photos and videos uploaded to platforms like Instagram or YouTube every single day. Or consider the transaction data generated by a global credit card company every second. That’s volume!
Real-World Example: The Large Hadron Collider (LHC) at CERN generates petabytes of data from particle collisions in its experiments, requiring immense storage and processing power.
Velocity (The Speed)
Big Data often arrives incredibly fast, sometimes in real-time streams. It needs to be processed quickly to be useful.
Simple Example: Imagine the constant flow of updates on your Twitter or Facebook feed. Or think about real-time GPS signals used by navigation apps like Google Maps or Waze to show current traffic conditions.
Real-World Example: Stock market trading data is generated and processed at lightning speed, where milliseconds can mean millions of dollars. Sensor networks monitoring weather patterns or industrial equipment also produce high-velocity data streams.
Variety (The Different Forms)
Big Data isn’t just neat rows and columns in a spreadsheet. It comes in many different formats.
Structured Data: Highly organized data, typically found in relational databases (like customer records with names, addresses, and purchase history).
Semi-Structured Data: Data that has some organizational properties but doesn’t fit a rigid database structure (like emails, XML files, or JSON data used by websites).
Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos). This makes up the vast majority of data generated today.
Simple Example: A single online retailer might have structured sales data, semi-structured web server logs, and unstructured customer reviews and social media comments.
Real-World Example: Healthcare systems manage a huge variety of data: structured patient demographics, semi-structured lab reports, and unstructured doctor’s notes, medical images (X-rays, MRIs), and even data from wearable health monitors.
Veracity (The Trustworthiness)
Big Data can sometimes be messy, incomplete, inconsistent, or uncertain. Ensuring data quality and accuracy is a major challenge.
Simple Example: Customer data might contain typos in names, multiple entries for the same person with slightly different addresses, or missing phone numbers. Social media sentiment analysis can be skewed by sarcasm or bots.
Real-World Example: Sensor data might be noisy or contain erroneous readings due to equipment malfunction. Survey data can suffer from biases based on how questions are asked or who responds.
Value (The Potential Insight)
This is the ultimate goal. Despite the challenges, Big Data holds immense potential value if we can effectively process and analyze it to uncover insights, patterns, and trends.
Simple Example: Analyzing vast amounts of customer purchase data can help a supermarket optimize stock levels, personalize promotions, and improve store layout.
Real-World Example: Analyzing large-scale genomic data can accelerate the discovery of new drugs and personalized medical treatments.
In a nutshell: Big Data is characterized by its immense volume, high speed, diverse formats, and potential uncertainty. It represents both a challenge (how to store, manage, and process it) and a massive resource (a potential goldmine of information).
What is Data Science?
Exploring the Ocean
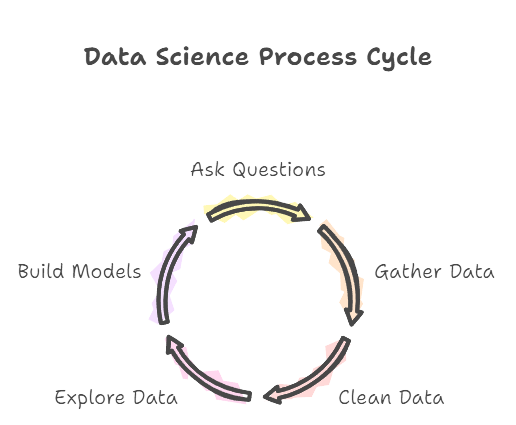
If Big Data is the ocean, Data Science is the multifaceted discipline of extracting knowledge and insights from data, whether it’s big or small. It’s an interdisciplinary field that blends statistics, computer science, and domain expertise to understand phenomena through data analysis. Data Science isn’t just about running numbers; it’s a process that involves:
Asking the Right Questions
It starts with curiosity and defining a clear problem or question that needs answering. What are we trying to figure out? (e.g., “Why are customer renewals dropping?”, “Can we predict machine failure?”)
Getting the Data
Identifying and collecting the necessary data from various sources. This might involve querying databases, scraping websites, accessing APIs, or using existing datasets. This is where Big Data often comes into play as the source material.
Cleaning and Preparing the Data (Data Wrangling)
Raw data is almost always messy. This crucial step involves handling missing values, correcting errors (addressing Veracity issues from Big Data), transforming data into a usable format, and structuring it for analysis. This often takes up a significant chunk of a data scientist’s time.
Exploring the Data (Exploratory Data Analysis – EDA)
Digging into the cleaned data to understand its basic characteristics, find patterns, identify trends, and visualize relationships. Think graphs, charts, and summary statistics.
Building Models (Modelling)
Applying statistical techniques and machine learning algorithms to uncover deeper insights, make predictions, or classify information.
Key Skills for Data Science: A data scientist typically needs a blend of skills:
- Mathematics and Statistics: To understand the theoretical underpinnings of models.
- Programming: Often in languages like Python or R, using libraries for data manipulation, analysis, and machine learning.
- Database Knowledge: Like SQL for retrieving data.
- Machine Learning: Understanding and applying various algorithms.
- Domain Expertise: Understanding the specific field (e.g., finance, healthcare, marketing) to ask relevant questions and interpret results correctly.
- Communication and Visualization: To explain findings effectively.
Big Data vs. Data Science: The Key Differences Summarized
Big Data and Data Science are closely related but fundamentally distinct fields within the data ecosystem. Understanding their differences is essential for anyone interested in data-driven technologies and careers.
| Feature | Big Data | Data Science |
| Primary Focus | Handling the characteristics of data (Volume, Velocity, Variety, Veracity) | Extracting knowledge and insights from data |
| Nature | The data itself and the infrastructure to manage it | The process and methods for analysing data |
| Core Goal | To store, process, and manage massive datasets efficiently | To understand, interpret, predict, and communicate findings |
| Key Challenge | Engineering: Building scalable systems for storage & processing | Analysis: Finding meaningful patterns and building accurate models |
| Main Tools | Hadoop, Spark, NoSQL databases, Cloud platforms (AWS S3, Azure Data Lake) | Python, R, SQL, Pandas, Scikit-learn, TensorFlow, Tableau |
| Output | Processed data ready for analysis; robust data pipelines; scalable storage solutions | Insights, reports, visualizations, predictive models, recommendations |
How They Work Together: The Powerful Synergy
While distinct, Big Data and Data Science are deeply intertwined and often work hand-in-hand. They are more like partners than rivals.
Big Data Fuels Data Science
Big Data provides the raw material – the massive datasets – that Data Science techniques can analyses to uncover insights that wouldn’t be possible with smaller datasets. The scale and variety of Big Data offer unprecedented opportunities for discovery.
Data Science Makes Big Data Valuable
Simply collecting and storing huge amounts of data isn’t useful on its own. Data Science provides the tools, techniques, and expertise to unlock the potential Value hidden within Big Data. It turns the raw ocean of data into actionable intelligence.
Big Data Technologies Enable Data Science at Scale
Tools like Hadoop and Spark were developed specifically to handle the challenges of Big Data. Data scientists rely on this infrastructure to perform complex analyses on massive datasets efficiently. Without Big Data technologies, applying Data Science to petabyte-scale problems would be impossible.
Example: E-commerce Recommendation Engine
An e-commerce recommendation engine uses data analysis and machine learning to personalize product suggestions for customers. By leveraging user behavior and purchase history, it enhances shopping experiences, increases sales, and drives customer loyalty through targeted, relevant recommendations.
Big Data
An online store like Amazon collects massive amounts of data every second (Volume, Velocity) – user clicks, search queries, items viewed, purchase history, items added to cart, time spent on pages (Variety). This data might have inconsistencies (Veracity). Storing and processing this requires Big Data infrastructure (e.g., distributed databases, processing frameworks).
Data Science
Data scientists use this collected Big Data. They clean it, explore user behaviour patterns, and then build machine learning models (Data Science process). These models learn from the vast purchase and browsing history to predict what other items a user might like.
Result
The “Customers who bought this item also bought…” or “Recommended for you” sections on the website. This feature, powered by Data Science applied to Big Data, drives engagement and sales (Value).
Conclusion: Different Roles, Shared Goal
Understanding the difference between Big Data and Data Science is crucial. Big Data is about the challenge and potential of handling enormous, fast-moving, and diverse datasets, focusing on the necessary infrastructure and technologies.
Data Science is about the process and practice of extracting meaningful insights, predictions, and knowledge from data (often, but not always, Big Data), focusing on analysis, algorithms, and interpretation.
Both are essential components of the modern data landscape, working together to turn raw information into transformative understanding and innovation that shapes our world in countless ways. They aren’t opposing forces, but rather two sides of the same revolutionary coin.
Frequently Asked Questions
What Is the Main Difference Between Big Data and Data Science?
Big Data involves the storage, processing, and management of vast, complex datasets that traditional tools cannot handle. Data Science, in contrast, focuses on analyzing this data using statistical methods, algorithms, and machine learning to extract actionable insights and predict future trends, enabling informed business decisions.
How Do Big Data and Data Science Complement Each Other?
Big Data provides the raw material—large volumes of structured and unstructured data—while Data Science analyses this data to uncover patterns, trends, and insights. Together, they enable organizations to harness the full value of their data, driving innovation and competitive advantage across industries.
What Industries Benefit Most from Big Data and Data Science?
Industries like finance, healthcare, retail, and technology leverage Big Data for real-time processing and storage, while Data Science delivers insights for predictive analytics, personalized services, and strategic planning. Their combined use is essential for organizations seeking to innovate and stay competitive in today’s data-driven landscape.
Authors
-

Written by:
Neha SinghReviewed by:



